A simple note for data-intensive applications.
From Designing Data-Intensive Applications by Martin Kleppmann
- Data Replication
- Partitioning / Sharding
- transaction
- Trouble with Distributed Systems
Data Replication
single-leader, multi-leader, and leaderless replication
leader-based replication:
- main steps:
-
One of the replicas is designated the leader (also known as master or primary). When clients want to write to the database, they must send their requests to the leader, which first writes the new data to its local storage.
-
The other replicas are known as followers (read replicas, slaves, secondaries, or hot standbys). Whenever the leader writes new data to its local storage, it also sends the data change to all of its followers as part of a replication log or change stream. Each follower takes the log from the leader and updates its local copy of the data base accordingly, by applying all writes in the same order as they were processed on the leader.
-
When a client wants to read from the database, it can query either the leader or any of the followers. However, writes are only accepted on the leader (the follow‐ ers are read-only from the client’s point of view).
-
- Synchronous Versus Asynchronous Replication
- Synchronous: the leader waits until follower 1 has confirmed that it received the write before reporting success to the user, and before making the write visible to other clients
- Asynchronous: the leader sends the message, but doesn’t wait for a response from the follower
- semi-synchronous: one of the followers is synchronous, and the others are asynchronous. If the synchronous follower becomes unavailable or slow, one of the asynchronous followers is made synchronous.
- Setting Up New Followers (Consistency and Durability):
-
Take a consistent snapshot of the leader’s database at some point in time—if possible, without taking a lock on the entire database.
-
Copy the snapshot to the new follower node.
-
The follower connects to the leader and requests all the data changes that have happened since the snapshot was taken. This requires that the snapshot is associated with an exact position in the leader’s replication log.
-
When the follower has processed the backlog of data changes since the snapshot, we say it has caught up. It can now continue to process data changes from the leader as they happen.
-
- Handling Node Outages (availability):
- Follower failure: Catch-up recovery
- from its log, it knows the last transaction that was processed before the fault occurred. Thus, the follower can connect to the leader and request all the data changes that occurred during the time when the follower was disconnected.
- Leader failure: Failover
- failover: the process of choosing a new leader when the old leader is no longer available.
- automatic failover process:
- Determining that the leader has failed: heartbeat and timeout
- Choosing a new leader: election process, quorum-based consensus algorithm
- Reconfiguring the system to use the new leader: The system needs to ensure that the old leader becomes a follower and recognizes the new leader
- Follower failure: Catch-up recovery
leader-based replication implementation
- Statement-based replication
- cons:
- Any statement that calls a nondeterministic function, such as NOW() to get the current date and time or RAND() to get a random number, is likely to generate a different value on each replica.
- If statements use an autoincrementing column, or if they depend on the existing data in the database, must be executed in exactly the same order on each replica, or else they may have a different effect.
- Statements that have side effects (e.g., triggers, stored procedures, user-defined functions) may result in different side effects occurring on each replica, unless the side effects are absolutely deterministic.
- not that commonly used now in practice
- cons:
- Write-ahead log (WAL) shipping
- used in PostgreSQL and Oracle
- use the exact same log to build a replica on another node: besides writing the log to disk, the leader also sends it across the network to its followers.
- cons:
- log describes the data on a very low level: a WAL contains details of which bytes were changed in which disk blocks.
- replication closely coupled to the storage engine
- typically not possible to run different versions of the database software on the leader and the followers.
- If the replication protocol allows the follower to use a newer software version than the leader, you can perform a zero-downtime upgrade of the database software by first upgrading the followers and then performing a failover to make one of the upgraded nodes the new leader. If the replication protocol does not allow this version mismatch, as is often the case with WAL shipping, such upgrades require downtime.
- Logical (row-based) log replication
- use different log formats for replication and for the storage engine, which allows the replication log to be decoupled from the storage engine internals.
- A logical log for a relational database is usually a sequence of records describing writes to database tables at the granularity of a row
- For an inserted row, the log contains the new values of all columns
- For a deleted row, the log contains enough information to uniquely identify the row that was deleted (usually the primary key)
- For an updated row, the log contains enough information to uniquely identify the updated row, and the new values of all columns (or at least the new values of all columns that changed).
- For transaction: A transaction that modifies several rows generates several such log records, followed by a record indicating that the transaction was committed.
- Trigger-based replication
- move replication up to the application layer
- A trigger lets you register custom application code that is automatically executed when a data change (write transaction) occurs in a database system.
- The trigger has the opportunity to log this change into a separate table, from which it can be read by an external process. That external process can then apply any necessary application logic and replicate the data change to another system.
Problems with Replication Lag
Appearently syncrounous replication is impratical for Leader-based replication aiming to handle workloads that consist of mostly reads and only a small percentage of writes (a common pattern on the web).
If an application reads from an asynchronous follower, it may see outdated information if the follower has fallen behind. This leads to apparent inconsistencies in the database: if you run the same query on the leader and a follower at the same time, you may get different results, because not all writes have been reflected in the follower.
Eventual consistency: if you stop writing to the database and wait a while, the followers will eventually catch up and become consistent with the leader.
Three possible problems that are likely to occur when there is replication lag
- Reading Your Own Writes: A user makes a write, followed by a read from a stale replica. To prevent this anomaly, we need read-after-write consistency.
- read-after-write consistency / read-your-writes consistency: guarantee that if the user reloads the page, they will always see any updates they submitted themselves.
- It makes no promises about other users: other users’ updates may not be visible until some later time.
- possible implementations:
- When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower. (For example, user profile information on a social network is normally only editable by the owner of the profile, not by anybody else. Thus, a simple rule is: always read the user’s own profile from the leader, and any other users’ profiles from a follower.)
- Use other criteria to decide whether to read from the leader. (track the time of the last update, for one minute after the last update, make all reads from the leader)
- The client can remember the timestamp of its most recent write—then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp. If a replica is not sufficiently up to date, either the read can be handled by another replica or the query can wait until the replica has caught up.- Monotonic Reads
- lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency.
- monotonic reads only means that if one user makes several reads in sequence, they will not see time go backward—i.e., they will not read older data after having previously read newer data.
- possible implementation:
- each user always makes their reads from the same replica (different users can read from different replicas).
- Consistent Prefix Reads
- This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
- in many distributed databases, different partitions operate independently, so there is no global ordering of writes: when a user reads from the database, they may see some parts of the database in an older state and some in a newer state.
- possible solution: make sure that any writes that are causally related to each other are written to the same partition
Multi-Leader Replication
Leader-based replication downside: one leader, and all writes must go through it.
multi-leader configuration / master–master or active/active replication: allow more than one node to accept writes. Replication still happens in the same way: each node that processes a write must forward that data change to all the other nodes.
Use Cases for Multi-Leader Replication
- Multi-datacenter operation
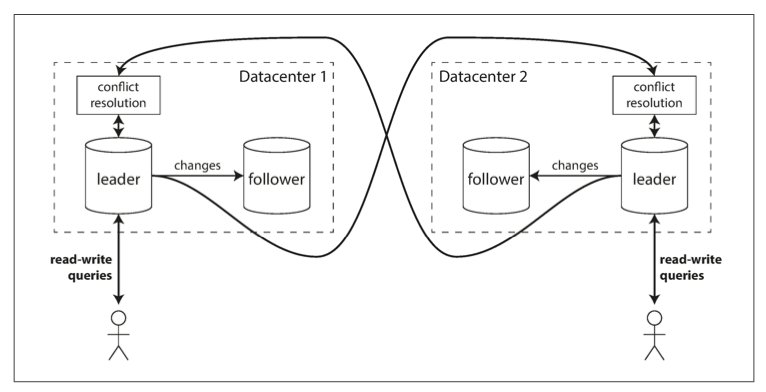
- have a leader in each datacenter, Within each datacenter, regular leader–follower replication is used; between datacenters, each datacenter’s leader replicates its changes to the leaders in other datacenters.
- the same data may be concurrently modified in two different datacenters, and those write conflicts must be resolved.
- Clients with offline operation
- if you have an application that needs to continue to work while it is disconnected from the internet, like calendar. If you make any changes while you are offline, they need to be synced with a server and your other devices when the device is next online.
- every device has a local database that acts as a leader (it accepts write requests), and there is an asynchronous multi-leader replication process (sync) between the replicas of your calendar on all of your devices.
- this setup is essentially the same as multi-leader replication between datacenters, taken to the extreme: each device is a “datacenter,” and the network connection between them is extremely unreliable.
- Collaborative editing
- like Google Docs, Etherpad
- When one user edits a document, the changes are instantly applied to their local replica (the state of the document in their web browser or client application) and asynchronously replicated to the server and any other users who are editing the same document.
Handling Write Conflicts
Conflict avoidance
- if the application can ensure that all writes for a particular record go through the same leader, then conflicts cannot occur.
Converging toward a consistent state
- every replication scheme must ensure that the data is eventually the same in all replicas.
- possible solutions:
- Give each write a unique ID (e.g., a timestamp, a long random number, a UUID, or a hash of the key and value), pick the write with the highest ID as the winner, and throw away the other writes.
- If a timestamp is used, this technique is known as last write wins (LWW).
- dangerously prone to data loss
- Give each replica a unique ID, and let writes that originated at a higher-numbered replica always take precedence over writes that originated at a lower-numbered replica.
- also implies data loss
- Somehow merge the values together
- Record the conflict in an explicit data structure that preserves all information, and write application code that resolves the conflict at some later time (perhaps by prompting the user).
Custom conflict resolution logic
- Give each write a unique ID (e.g., a timestamp, a long random number, a UUID, or a hash of the key and value), pick the write with the highest ID as the winner, and throw away the other writes.
most appropriate way of resolving a conflict may depend on the application
two choices:
- On write:
- As soon as the database system detects a conflict in the log of replicated changes, it calls the conflict handler.
- On read:
- When a conflict is detected, all the conflicting writes are stored.
- The next time the data is read, The application may prompt the user or automatically resolve the conflict, and write the result back to the database.
Also, conflict resolution usually applies at the level of an individual row or document, not for an entire transaction
if you have a transaction that atomically makes several different writes (see Chapter 7), each write is still considered separately for the purposes of conflict resolution.
Automatic Conflict Resolution
- Conflict-free replicated datatypes (CRDTs)
- Mergeable persistent data structures
- Operational transformation: Google Docs
Multi-Leader Replication Topologies
circular, star topology, all-to-all / full mesh
- problem for circular and star topology:
- if just one node fails, it can interrupt the flow of replication messages between other nodes
- problem for all-to-all / full mesh:
- some network links may be faster than others (e.g., due to network congestion), with the result that some replication messages may “overtake” others
Leaderless Replication
Writing to the Database When a Node Is Down
To prevent read stale data from a node which is previously down, when a client reads from the database, it doesn’t just send its request to one replica: read requests are also sent to several nodes in parallel.
Version numbers are used to determine which value is newer
Read repair and anti-entropy
After an unavailable node comes back online, how does it catch up on the writes that it missed?
- Read repair
- When a client makes a read from several nodes in parallel, it can detect any stale responses.
- The client can then send the latest value back to the node that had the stale value, and that node can update its local copy.
- Anti-entropy
- a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another
- does not copy writes in any particular order
- may be a significant delay before data is copied
Quorums for reading and writing
quorum reads and writes:
- w + r > n
- A common choice is to make n an odd number (typically 3 or 5) and to set w = r = (n + 1) / 2 (rounded up).
Limitations of Quorum Consistency
- If a sloppy quorum is used, the w writes may end up on different nodes than the r reads, so there is no longer a guaranteed overlap between the r nodes and the w nodes
- If two writes occur concurrently, it is not clear which one happened first. the only safe solution is to merge the concurrent writes
- If a write happens concurrently with a read, the write may be reflected on only some of the replicas. In this case, it’s undetermined whether the read returns the old or the new value.
- If a write succeeded on some replicas but failed on others (for example because the disks on some nodes are full), and overall succeeded on fewer than w replicas, it is not rolled back on the replicas where it succeeded.
- If a node carrying a new value fails, and its data is restored from a replica carry‐ ing an old value, the number of replicas storing the new value may fall below w, breaking the quorum condition.
Sloppy Quorums and Hinted Handoff
sloppy quorum:
- writes and reads still require w and r successful responses, but those may include nodes that are not among the designated n “home” nodes for a value.
- network interruption can easily cut off a client from a large number of database node, under this circumstance, accept writes anyway, and write them to some nodes that are reachable but aren’t among the n nodes on which the value usually lives
hinted handoff:
- Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate “home” nodes.
Sloppy quorums are particularly useful for increasing write availability:
- as long as any w nodes are available, the database can accept writes.
- when w + r > n, you cannot be sure to read the latest value for a key, because the latest value may have been temporarily written to some nodes outside of n
Detecting Concurrent Writes
The problem is that events may arrive in a different order at different nodes, due to variable network delays and partial failures.
If each node simply overwrote the value for a key whenever it received a write request from a client, the nodes would become permanently inconsistent, the replicas should converge toward the same value.
- Last Write Wins (discarding concurrent writes)
- Use a timestamp to determine which write is the latest: last write wins (LWW)
- only one of the writes will survive and the others will be silently discarded
- may even drop writes that are not concurrent
- only safe way of using a database with LWW is to ensure that a key is only written once and thereafter treated as immutable
- Use a timestamp to determine which write is the latest: last write wins (LWW)
- The “happens-before” relationship and concurrency
- An operation A happens before another operation B if B knows about A, or depends on A, or builds upon A in some way.
- Three possibilities:
- A happens before B
- B happens before A
- A and B are concurrent
- Capturing the happens-before relationship:
- The server maintains a version number for every key, increments the version number every time that key is written, and stores the new version number along with the value written.
- When a client reads a key, the server returns all values that have not been overwritten, as well as the latest version number. A client must read a key before writing.
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read. (The response from a write request can be like a read, returning all current values, which allows us to chain several writes like in the shopping cart example.)
- When the server receives a write with a particular version number, it can overwrite all values with that version number or below (since it knows that they have been merged into the new value), but it must keep all values with a higher version number (because those values are concurrent with the incoming write).
- Merging concurrently written values
- clients have to clean up afterward by merging the concurrently written values.
- a reasonable approach to merging siblings is to just take the union.
- tombstone: an item cannot simply be deleted from the database when it is removed; instead, the system must leave a marker with an appropriate version number to indicate that the item has been removed when merging siblings.
- Version vectors
- we need to use a version number per replica as well as per key.
- Each replica increments its own version number when processing a write, and also keeps track of the version numbers it has seen from each of the other replicas.
- The collection of version numbers from all the replicas is called a version vector.
- The version vector structure ensures that it is safe to read from one replica and subsequently write back to another replica.
Partitioning / Sharding
Partitioning of Key-Value Data
skewed: If the partitioning is unfair, so that some partitions have more data or queries than others
hot spot: A partition with disproportionately high load
Partitioning by Key Range
One way of partitioning is to assign a continuous range of keys (from some minimum to some maximum) to each partition
downside of key range partitioning:
- certain access patterns can lead to hot spots.
Partitioning by Hash of Key
A good hash function takes skewed data and makes it uniformly distributed.
-
This technique is good at distributing keys fairly among the partitions. The partition boundaries can be evenly spaced, or they can be chosen pseudorandomly (in which case the technique is sometimes known as consistent hashing).
-
by using the hash of the key for partitioning we lose a nice property of key-range partitioning: the ability to do efficient range queries.
-
A table in Cassandra can be declared with a compound primary key consisting of several columns. Only the first part of that key is hashed to determine the partition, but the other columns are used as a concatenated index for sorting the data in Cassandra’s SSTables. A query therefore cannot search for a range of values within the first column of a compound key, but if it specifies a fixed value for the first column, it can perform an efficient range scan over the other columns of the key.
- primary key for updates is chosen to be (user_id, update_timestamp), then you can efficiently retrieve all updates made by a particular user within some time interval, sorted by timestamp.
Skewed Workloads and Relieving Hot Spots
extreme case: where all reads and writes are for the same key
Solution:
- a simple technique is to add a random number to the beginning or end of the key. Just a two-digit decimal random number would split the writes to the key evenly across 100 different keys, allowing those keys to be distributed to different partitions.
- having split the writes across different keys, any reads now have to do additional work, as they have to read the data from all 100 keys and combine it.
Partitioning and Secondary Indexes
document-based partitioning and term-based partitioning
Partitioning Secondary Indexes by Document
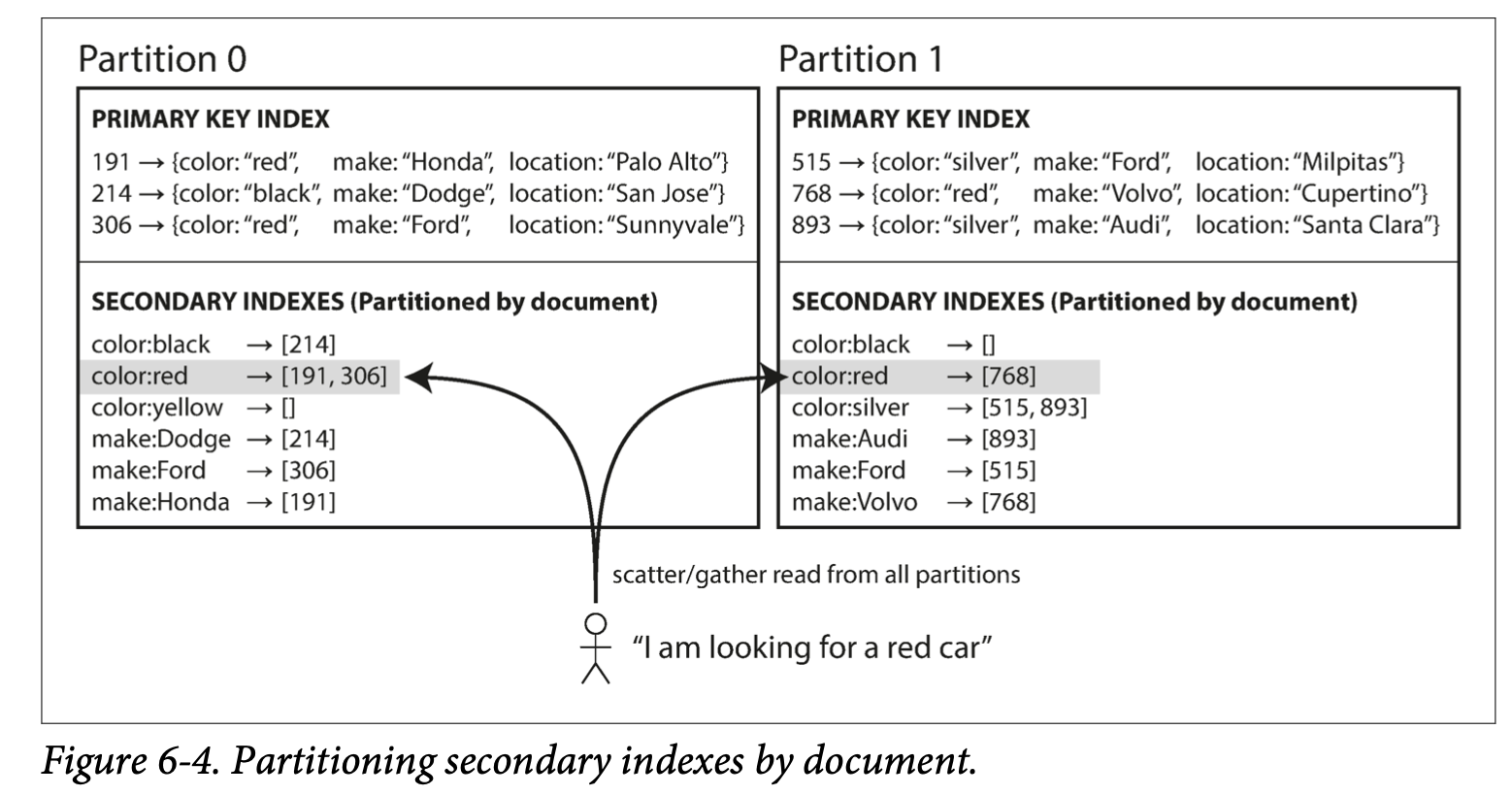
also known as local index
- each partition is completely separate: each partition maintains its own secondary indexes, covering only the documents in that partition.
- doesn’t care what data is stored in other partitions
- need to send the query to all partitions, and combine all the results you get back.
also known as scatter/ gather
Partitioning Secondary Indexes by Term
also known as global index
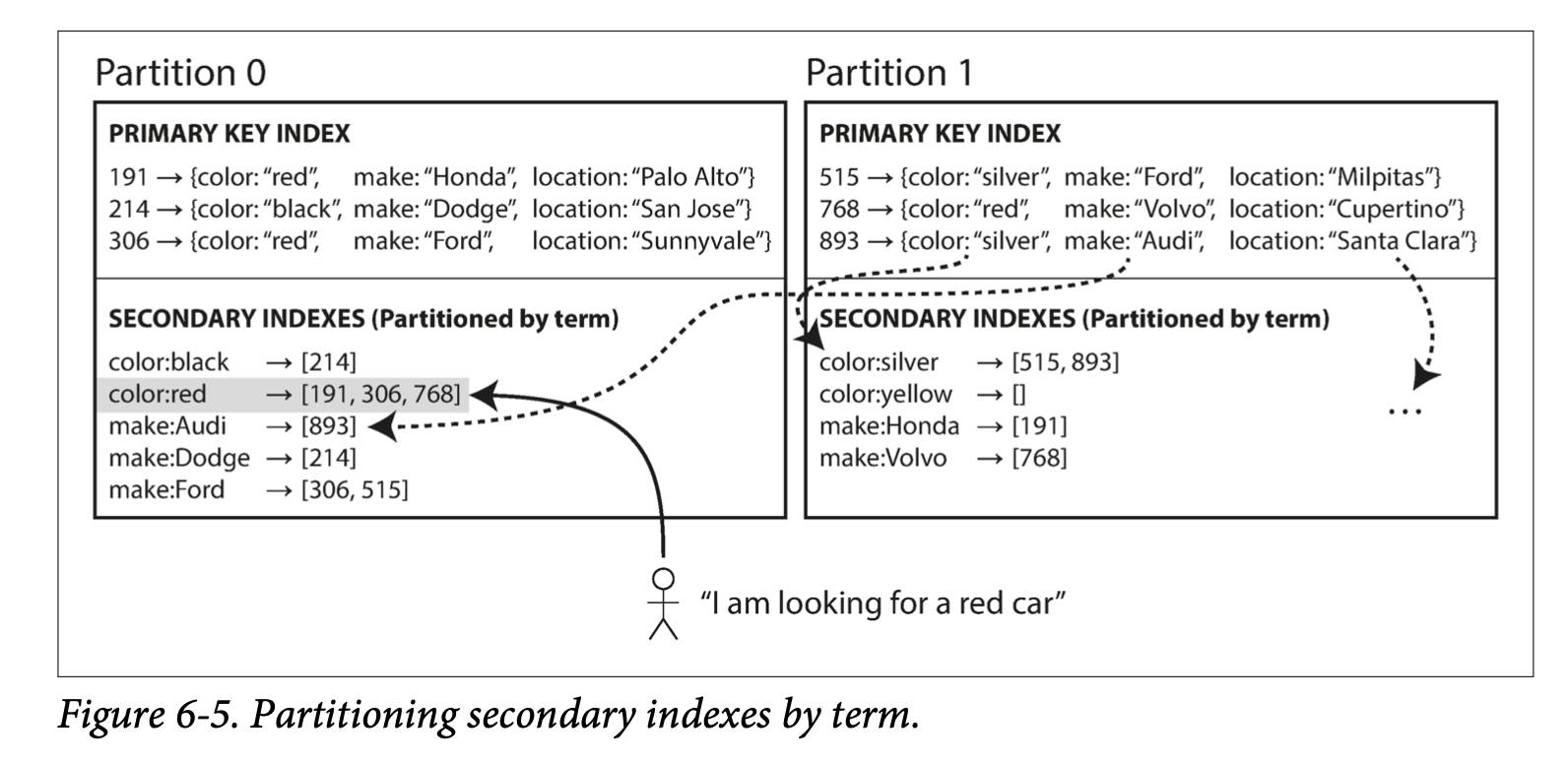
We call this kind of index term-partitioned, because the term we’re looking for determines the partition of the index.
- The advantage of a global (term-partitioned) index over a document-partitioned index is that it can make reads more efficient: rather than doing scatter/gather over all partitions, a client only needs to make a request to the partition containing the term that it wants.
- downside of a global index is that writes are slower and more complicated, because a write to a single document may now affect multiple partitions of the index
- In practice, updates to global secondary indexes are often asynchronous
Rebalancing Partitions
The process of moving load from one node in the cluster to another is called rebalancing.
- After rebalancing, the load (data storage, read and write requests) should be shared fairly between the nodes in the cluster.
- While rebalancing is happening, the database should continue accepting reads and writes.
- No more data than necessary should be moved between nodes, to make rebalancing fast and to minimize the network and disk I/O load.
Strategies for Rebalancing
- why not using mod:
- The problem with the mod N approach is that if the number of nodes N changes, most of the keys will need to be moved from one node to another.
- Such frequent moves make rebalancing excessively expensive.
Fixed number of partitions
- create many more partitions than there are nodes
- assign several partitions to each node.
-
if a node is added to the cluster, the new node can steal a few partitions from every existing node until partitions are fairly distributed once again.
- Only entire partitions are moved between nodes.
- The number of partitions does not change
- nor does the assignment of keys to partitions
- The only thing that changes is the assignment of partitions to nodes.
When using this startegy:
- the number of partitions is usually fixed when the database is first set up and not changed afterward
- the number of partitions configured at the outset is the maximum number of nodes you can have, so you need to choose it high enough to accommodate future growth.
Dynamic partitioning
This means:
- When a partition grows to exceed a configured size (on HBase, the default is 10 GB), it is split into two partitions so that approximately half of the data ends up on each side of the split
- if lots of data is deleted and a partition shrinks below some threshold, it can be merged with an adjacent partition.
- Each partition is assigned to one node, and each node can handle multiple partitions, like in the case of a fixed number of partitions
- In the case of HBase, the transfer of partition files happens through HDFS, the underlying distributed filesystem.
advantages:
- the number of partitions adapts to the total data volume.
caveat:
- there is no a priori information about where to draw the partition boundaries. While the dataset is small—until it hits the point at which the first partition is split—all writes have to be processed by a single node while the other nodes sit idle.
Partitioning proportionally to nodes
- make the number of partitions proportional to the number of nodes—in other words, to have a fixed number of partitions per node
- the size of each partition grows proportionally to the dataset size while the number of nodes remains unchanged
- increase the number of nodes, the partitions become smaller again.
- When a new node joins the cluster, it randomly chooses a fixed number of existing partitions to split, and then takes ownership of one half of each of those split partitions while leaving the other half of each partition in place.
- Picking partition boundaries randomly requires that hash-based partitioning is used (so the boundaries can be picked from the range of numbers produced by the hash function).
Automatic or Manual Rebalancing
- fully automatic rebalancing: the system decides automatically when to move partitions from one node to another, without any administrator interaction
- fully manual: the assignment of partitions to nodes is explicitly configured by an administrator, and only changes when the administrator explicitly reconfigures it
- something in between: system generate a suggested partition assignment automatically, but require an administrator to commit it before it takes effect
Request Routing
service discovery
possible solutions for service discovery:
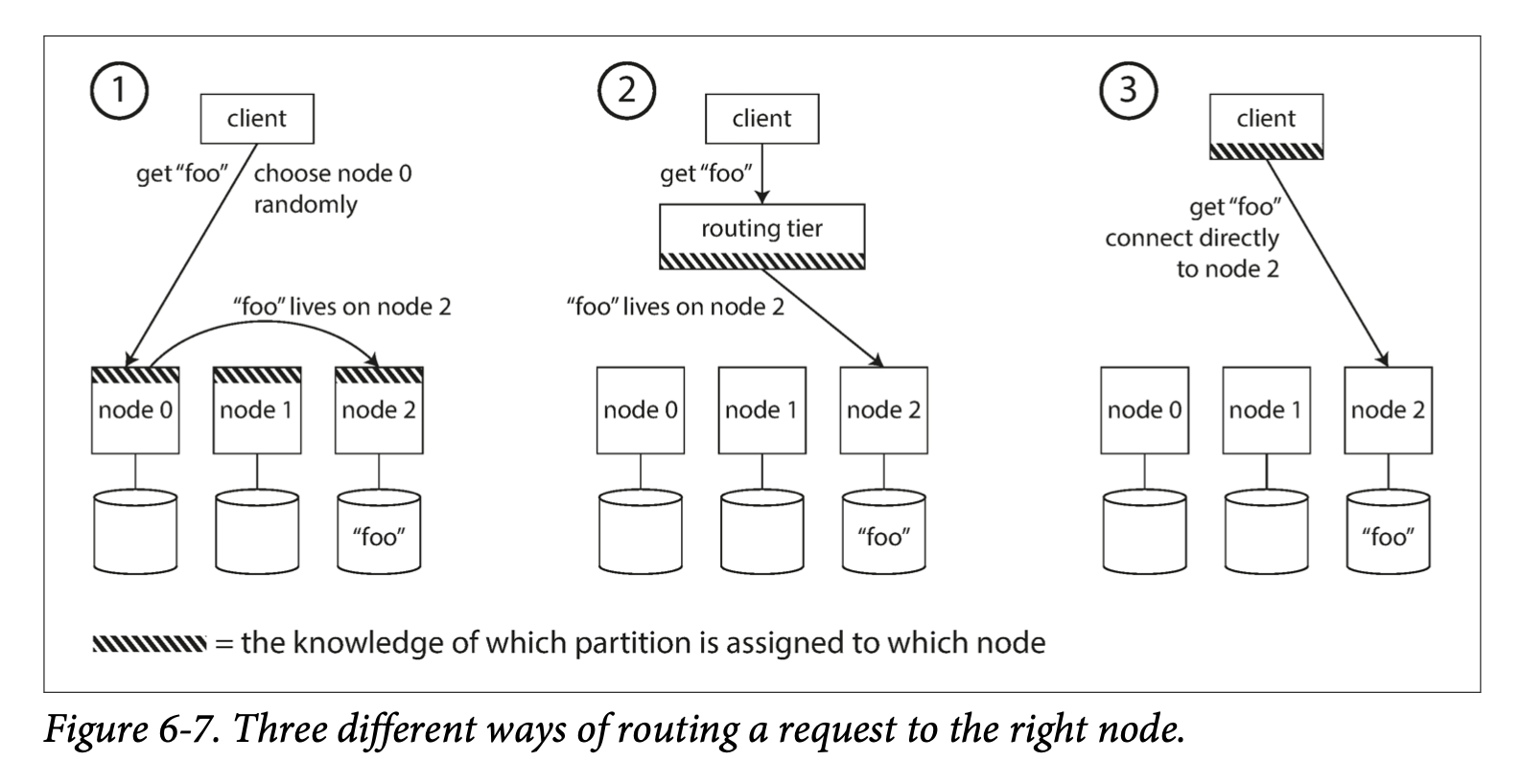
- Allow clients to contact any node (e.g., via a round-robin load balancer). If that node coincidentally owns the partition to which the request applies, it can handle the request directly; otherwise, it forwards the request to the appropriate node, receives the reply, and passes the reply along to the client.
- Send all requests from clients to a routing tier first, which determines the node that should handle each request and forwards it accordingly. This routing tier does not itself handle any requests; it only acts as a partition-aware load balancer.
- Require that clients be aware of the partitioning and the assignment of partitions to nodes. In this case, a client can connect directly to the appropriate node, without any intermediary.
key problem: how does the component making the routing decision (which may be one of the nodes, or the routing tier, or the client) learn about changes in the assignment of partitions to nodes
- rely on a separate coordination service such as ZooKeeper to keep track of this cluster metadata
- Cassandra and Riak take a different approach: they use a gossip protocol among the nodes to disseminate any changes in cluster state.
- Requests can be sent to any node, and that node forwards them to the appropriate node for the requested partition.
transaction
safety guarantees: Transactions are not a law of nature; they were created with a purpose, namely to simplify the programming model for applications accessing a database. By using transactions, the application is free to ignore certain potential error scenarios and concurrency issues, because the database takes care of them instead.
ACID
Atomicity, Consistency, Isolation, and Durability
BASE: Basically Available, Soft state, and Eventual consistency
Atomicity
In multi-threaded programming:
- if one thread executes an atomic operation, that means there is no way that another thread could see the half-finished result of the operation.
In the context of ACID:
- something that cannot be broken down into smaller parts.
- describes what happens if a client wants to make several writes, but a fault occurs after some of the writes have been processed
- The ability to abort a transaction on error and have all writes from that transaction discarded is the defining feature of ACID atomicity.
Consistency
consistency (in the ACID sense) is a property of the application. The application may rely on the database’s atomicity and isolation properties in order to achieve consistency, but it’s not up to the database alone.
The idea of ACID consistency is that you have certain statements about your data (invariants) that must always be true.
If a transaction starts with a database that is valid according to these invariants, and any writes during the transaction preserve the validity, then you can be sure that the invariants are always satisfied.
this idea of consistency depends on the application’s notion of invariants, and it’s the application’s responsibility to define its transactions correctly so that they preserve consistency.
Isolation
Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other: they cannot step on each other’s toes.
- Concurrently running transactions shouldn’t interfere with each other.
- classic database textbooks formalize isolation as serializability, which means that each transaction can pretend that it is the only transaction running on the entire database.
- The database ensures that when the transactions have committed, the result is the same as if they had run serially (one after another), even though in reality they may have run concurrently.
- However, in practice, serializable isolation is rarely used, because it carries a performance penalty.
More details will be discussed in Weak Isolation Levels
Durability
Durability is the promise that once a transaction has committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes.
Single-Object and Multi-Object Operations
These definitions (Atomic and Isolation) assume that you want to modify several objects (rows, documents, records) at once. Such multi-object transactions are often needed if several pieces of data need to be kept in sync.
A transaction is usually understood as a mechanism for grouping multiple operations on multiple objects into one unit of execution.
Single-object writes
single-object operations:
- prevent lost updates when several clients try to write to the same object concurrently
- not transactions in the usual sense of the word
examples:
- storage engines almost universally aim to provide atomicity and isolation on the level of a single object (such as a key- value pair) on one node:
- Atomicity can be implemented using a log for crash recovery
- isolation can be implemented using a lock on each object (allowing only one thread to access an object at any one time)
- atomic operations:
- increment operation
- compare-and-set
The need for multi-object transactions
- In a relational data model, a row in one table often has a foreign key reference to a row in another table. (Similarly, in a graph-like data model, a vertex has edges to other vertices.) Multi-object transactions allow you to ensure that these references remain valid: when inserting several records that refer to one another, the foreign keys have to be correct and up to date, or the data becomes nonsensical.
- In a document data model, the fields that need to be updated together are often within the same document, which is treated as a single object—no multi-object transactions are needed when updating a single document. However, document databases lacking join functionality also encourage denormalization (see “Relational Versus Document Databases Today” on page 38). When denormalized information needs to be updated, like in the example of Figure 7-2, you need to update several documents in one go. Transactions are very useful in this situation to prevent denormalized data from going out of sync.
- In databases with secondary indexes (almost everything except pure key-value stores), the indexes also need to be updated every time you change a value. These indexes are different database objects from a transaction point of view: for example, without transaction isolation, it’s possible for a record to appear in one index but not another, because the update to the second index hasn’t happened yet.
Handling errors and aborts
Weak Isolation Levels
serializable isolation:
- database guarantees that transactions have the same effect as if they ran serially (i.e., one at a time, without any concurrency).
- has a performance cost
Read Committed
The most basic level of transaction isolation
- When reading from the database, you will only see data that has been committed (no dirty reads).
- When writing to the database, you will only overwrite data that has been committed (no dirty writes).
- No dirty reads:
- dirty reads: a transaction has written some data to the database, but the transaction has not yet committed or aborted, and another transaction can see that uncommitted data
- any writes by a transaction only become visible to others when that transaction commits (and then all of its writes become visible at once).
- possible needed situation:
- transaction needs to update several objects
- transaction aborts, any writes it has made need to be rolled back
- No dirty writes:
- dirty writes: the earlier write is part of a transaction that has not yet committed, and the later write overwrites an uncommitted value
- Transactions running at the read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted.
Implementation of read committed:
- prevent dirty writes by using row-level locks
- when a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object.
- It must then hold that lock until the transaction is committed or aborted
- prevent dirty reads:
- for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock.
- While the transaction is ongoing, any other transactions that read the object are simply given the old value.
- Only when the new value is committed do transactions switch over to reading the new value.
Snapshot Isolation and Repeatable Read
nonrepeatable read / read skew:
- nonrepeatable read: A transaction reads a value, and then another transaction modifies that value and commits. If the first transaction reads the value again, it will see a different value.
common solution:
- Snapshot isolation is the most common solution to this problem.
- The idea is that each transaction reads from a consistent snapshot of the database—that is, the transaction sees all the data that was committed in the database at the start of the transaction.
Implementation:
- Like read committed isolation, implementations of snapshot isolation typically use write locks to prevent dirty writes
- However, reads do not require any locks. readers never block writers, and writers never block readers.
- MVCC: The database must potentially keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time. Because it maintains several versions of an object side by side
Read-Committed Isolation and Snapshot Isolation:
- If a database only needed to provide read committed isolation, but not snapshot isolation, it would be sufficient to keep two versions of an object: the committed version and the overwritten-but-not-yet-committed version. However, storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well.
- A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction.
How MVCC-based snapshot isolation is implemented in PostgreSQL
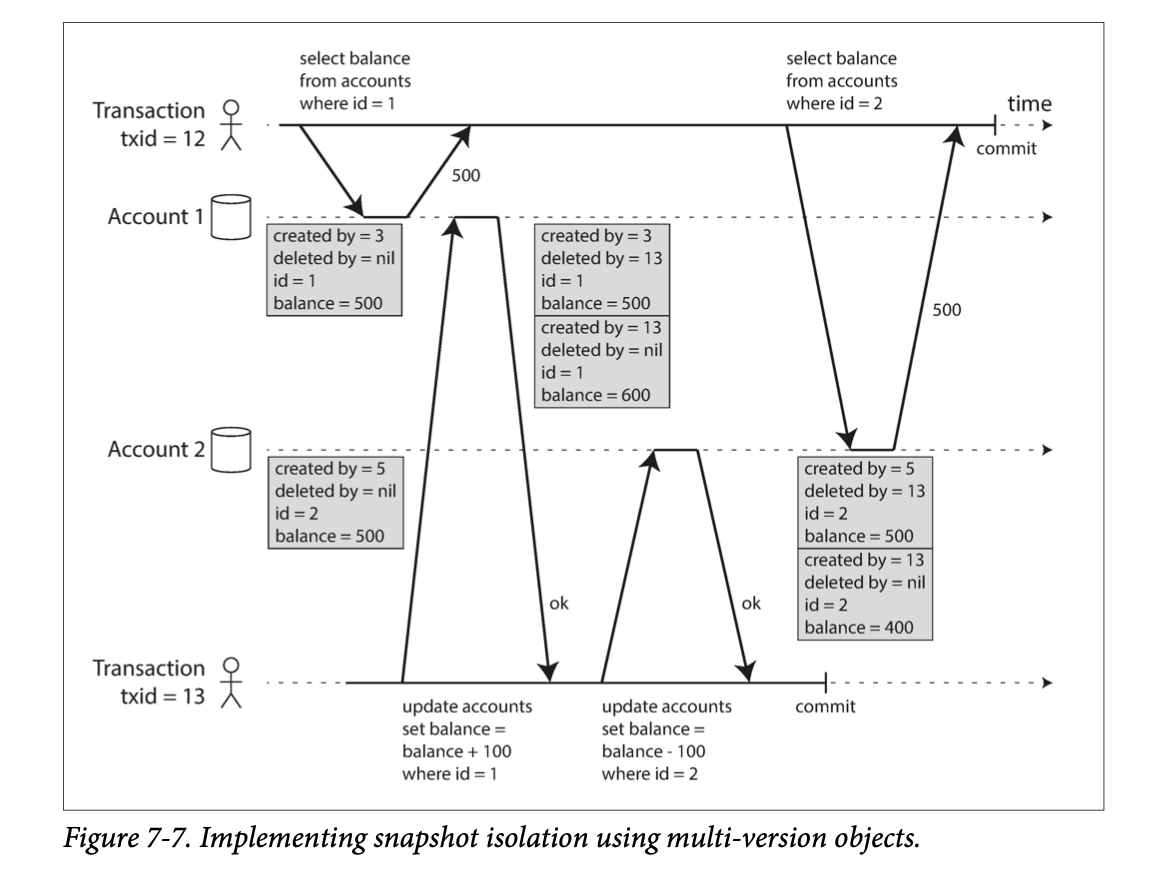
- When a transaction is started, it is given a unique, always-increasingvii transaction ID (txid)
- Whenever a transaction writes anything to the database, the data it writes is tagged with the transaction ID of the writer.
- If a transaction deletes a row, the row isn’t actually deleted from the database, but it is marked for deletion by setting the deleted_by field to the ID of the transaction that requested the deletion.
- At some later time, when it is certain that no transaction can any longer access the deleted data, a garbage collection process in the database removes any rows marked for deletion and frees their space.
Visibility rules for observing a consistent snapshot
creation and deletion of objects:
- At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time. Any writes that those transactions have made are ignored, even if the transactions subsequently commit.
- Any writes made by aborted transactions are ignored.
- Any writes made by transactions with a later transaction ID (i.e., which started after the current transaction started) are ignored, regardless of whether those transactions have committed.
- All other writes are visible to the application’s queries.
an object is visible if both of the following conditions are true:
- At the time when the reader’s transaction started, the transaction that created the object had already committed.
- The object is not marked for deletion, or if it is, the transaction that requested deletion had not yet committed at the time when the reader’s transaction started.
snapshot isolation and Indexes
PostgreSQL:
- One option is to have the index simply point to all versions of an object and require an index query to filter out any object versions that are not visible to the current transaction.
- When garbage collection removes old object versions that are no longer visible to any transaction, the corresponding index entries can also be removed.
- if different versions of the same object can fit on the same page, avoid index updates
CouchDB, Datomic, and LMDB:
- use an append-only/copy-on-write variant that does not overwrite pages of the tree when they are updated, but instead creates a new copy of each modified page.
Repeatable read and naming confusion
Snapshot isolation:
- In Oracle it is called serializable
- In PostgreSQL and MySQL it is called repeatable read
- IBM DB2: uses “repeatable read” to refer to serializability
Preventing Lost Updates
lost update:
- two transactions writing concurrently, write-write conflict
- A transaction reads a value, and then another transaction modifies that value and commits. If the first transaction writes the value back, it will overwrite the second transaction’s write.
- read-modify-write cycle
Atomic write operations
- Many databases provide atomic update operations, which remove the need to implement read-modify-write cycles in application code.
- implementation of atomicity
- cursor stability: taking an exclusive lock on the object when it is read so that no other transaction can read it until the update has been applied
- or force all atomic operations to be executed on a single thread
- implementation of atomicity
Explicit locking
Another option for preventing lost updates, if the database’s built-in atomic operations don’t provide the necessary functionality, is for the application to explicitly lock objects that are going to be updated.
- a lock for read-modify-write cycle
- involves some logic that you cannot sensibly implement as a database query
Automatically detecting lost updates
Atomic operations and locks are ways of preventing lost updates by forcing the read-modify-write cycles to happen sequentially.
An alternative is to allow them to execute in parallel and, if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle.
- advantage: databases can perform this check efficiently in conjunction with snapshot isolation.
- PostgreSQL’s repeatable read, Oracle’s serializable, and SQL Server’s snapshot isolation levels automatically detect when a lost update has occurred and abort the offending transaction.
- MySQL/InnoDB’s repeatable read does not detect lost updates
Compare-and-set
The purpose of this operation is to avoid lost updates by allowing an update to happen only if the value has not changed since you last read it.
Conflict resolution and replication
In replicated databases (mltiple nodes), preventing lost updates takes on another dimension: since they have copies of the data on multiple nodes, and the data can potentially be modified concurrently on different nodes, some additional steps need to be taken to prevent lost updates.
- a common approach in such replicated databases is to allow concurrent writes to create several conflicting versions of a value (also known as siblings), and to use application code or special data structures to resolve and merge these versions after the fact.
- Atomic operations can work well in a replicated context, especially if they are commutative (i.e., you can apply them in a different order on different replicas, and still get the same result).
- incrementing a counter
- adding an element to a set
- last write wins (LWW) conflict resolution method is prone to lost updates
Write Skew and Phantoms
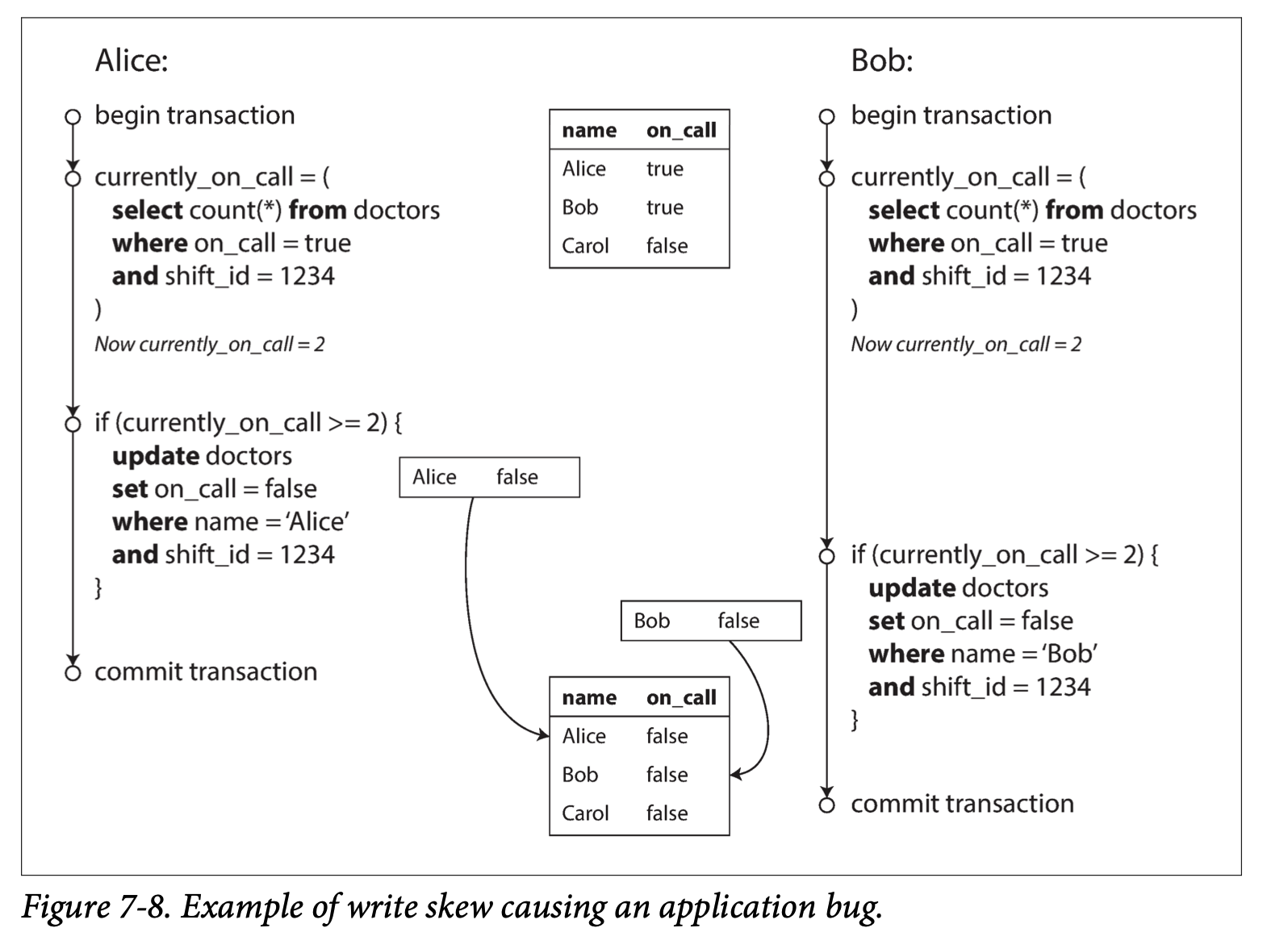
write skew: two transactions read the same data, and then each transaction writes to different objects and trigger conflict or violate restriction.
- two transactions read the same data
- two transactions believe that there is no conflict
- write data back and conflict happens
write skew is a generalization of the lost update problem.
- Write skew can occur if two transactions read the same objects, and then update some of those objects
- In the special case where different transactions update the same object, you get a dirty write or lost update anomaly (depending on the timing).
restriction for write skew prevention:
- Atomic single-object operations don’t help, as multiple objects are involved.
- Current snapshot isolation and their lost update detection can’t prevent write skew, requires true serializable isolation
Phantoms causing write skew
All of write skew examples follow a similar pattern:
- A SELECT query checks whether some requirement is satisfied by searching for rows that match some search condition
- Depending on the result of the first query, the application code decides how to continue
- If the application decides to go ahead, it makes a write (INSERT, UPDATE, or DELETE) to the database and commits the transaction.
The effect of this write changes the precondition of the decision of step 2.
- if you were to repeat the SELECT query from step 1 after commiting the write, you would get a different result
- the write changed the set of rows matching the search condition
phantom: This effect, where a write in one transaction changes the result of a search query in another transaction
Snapshot isolation avoids phantoms in read-only queries, but in read-write transactions like the examples we discussed, phantoms can lead to particularly tricky cases of write skew.
Solution: Materializing conflicts
materializing conflicts: takes a phantom and turns it into a lock conflict on a concrete set of rows that exist in the database
- hard and error-prone to figure out how to materialize conflicts
- ugly to let a concurrency control mechanism leak into the application data model
- better choice: serializable isolation level
Serializability
Serializable isolation
- strongest isolation level
- even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency
- guarantees that if the transactions behave correctly when run individually, they continue to be correct when run concurrently
Serializability Implementation
- Literally executing transactions in a serial order
- Two-phase locking (2PL)
- Optimistic concurrency control techniques such as serializable snapshot isolation (SSI)
Actual Serial Execution
- The approach of executing transactions serially is implemented in VoltDB/H-Store, Redis, and Datomic
- A system designed for single-threaded execution can sometimes perform better than a system that supports concurrency, because it can avoid the coordination overhead of locking.
- its throughput is limited to that of a single CPU core.
Encapsulating transactions in stored procedures
In this interactive style of transaction (the transaction needs to wait for response from user), a lot of time is spent in network communication between the application and the database.
If you were to disallow concurrency in the database and only process one transaction at a time, the throughput would be dreadful because the database would spend most of its time waiting for the application to issue the next query for the current transaction.
In this kind of database, it’s necessary to process multiple transactions concurrently in order to get reasonable performance.
For this reason, systems with single-threaded serial transaction processing don’t allow interactive multi-statement transactions.
stored procedure:
- application must submit the entire transaction code to the database ahead of time
- Provided that all data required by a transaction is in memory, the stored procedure can execute very fast, without waiting for any network or disk I/O.
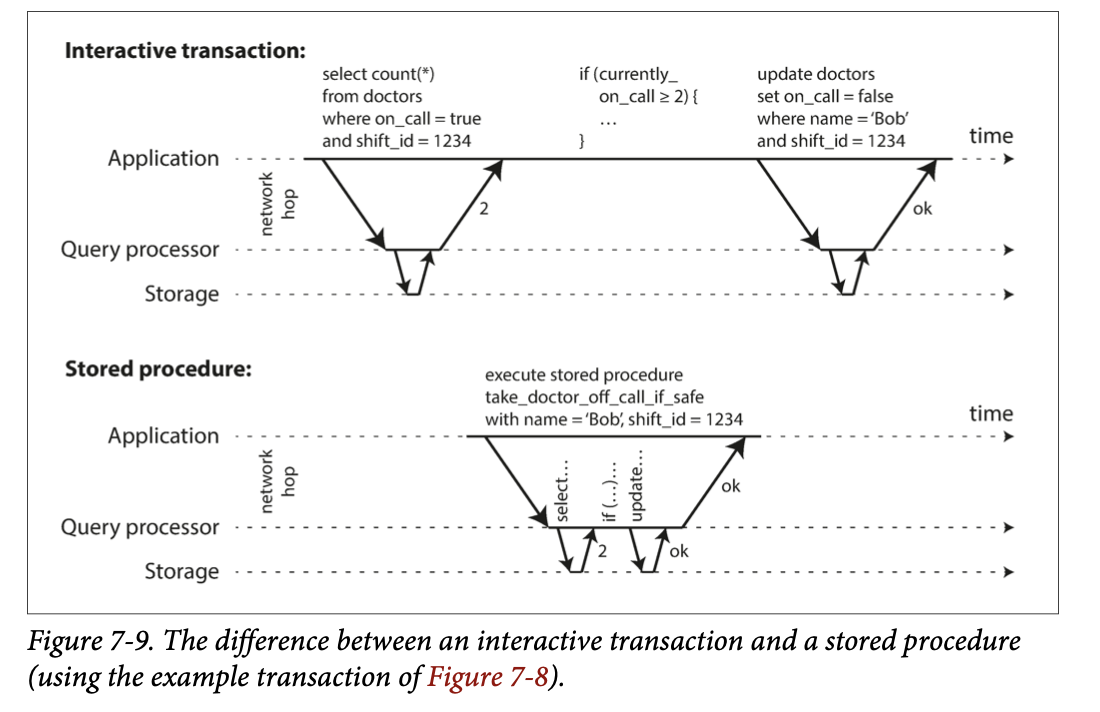
pros and cons of stored procedures:
- cons:
- Each database vendor has its own language for stored procedures (Oracle has PL/ SQL, SQL Server has T-SQL, PostgreSQL has PL/pgSQL, etc.)
- Code running in a database is difficult to manage: compared to an application server, it’s harder to debug, version control and deploy
- A database is often much more performance-sensitive than an application server, because a single database instance is often shared by many application servers. And a badly written stored procedure (e.g., using a lot of memory or CPU time) in a database can cause much more trouble than equivalent badly written code in an application server.
- pros:
- Modern implementations of stored procedures use existing general-purpose programming languages
- VoltDB uses Java or Groovy
- Datomic uses Java or Clojure
- Redis uses Lua.
- executing all transactions on a single thread becomes feasible
- don’t need to wait for I/O and they avoid the overhead of other concurrency control mechanisms
- Modern implementations of stored procedures use existing general-purpose programming languages
Partitioning
- Executing all transactions serially makes concurrency control much simpler, but limits the transaction throughput of the database to the speed of a single CPU core on a single machine.
- In order to scale to multiple CPU cores, and multiple nodes, you can potentially partition your data, which is supported in VoltDB.
- for any transaction that needs to access multiple partitions, the database must coordinate the transaction across all the partitions that it touches. The stored procedure needs to be performed in lock-step across all partitions to ensure serializability across the whole system.
- Simple key-value data can often be partitioned very easily, but data with multiple secondary indexes is likely to require a lot of crosspartition coordination
Summary of serial execution
Serial execution of transactions has become a viable way of achieving serializable isolation within certain constraints:
- Every transaction must be small and fast, because it takes only one slow transaction to stall all transaction processing.
- It is limited to use cases where the active dataset can fit in memory. Rarely accessed data could potentially be moved to disk, but if it needed to be accessed in a single-threaded transaction, the system would get very slow.
- Write throughput must be low enough to be handled on a single CPU core, or else transactions need to be partitioned without requiring cross-partition coordination.
- Cross-partition transactions are possible, but there is a hard limit to the extent to which they can be used.
Two-Phase Locking (2PL)
Two-phase locking:
- Several transactions are allowed to concurrently read the same object as long as nobody is writing to it.
- But as soon as anyone wants to write (modify or delete) an object, exclusive access is required
- If transaction A has read an object and transaction B wants to write to that object, B must wait until A commits or aborts before it can continue. (This ensures that B can’t change the object unexpectedly behind A’s back.)
- If transaction A has written an object and transaction B wants to read that object, B must wait until A commits or aborts before it can continue. (Reading an old version of the object, is not acceptable under 2PL.)
- In 2PL, writers don’t just block other writers; they also block readers and vice versa.
- 2PL provides serializability, it protects against all the race conditions discussed earlier, including lost updates and write skew.
Implementation of two-phase locking
The blocking of readers and writers is implemented by a having a lock on each object in the database. The lock can either be in shared mode or in exclusive mode.
- If a transaction wants to read an object, it must first acquire the lock in shared mode. Several transactions are allowed to hold the lock in shared mode simultaneously, but if another transaction already has an exclusive lock on the object, these transactions must wait.
- If a transaction wants to write to an object, it must first acquire the lock in exclusive mode. No other transaction may hold the lock at the same time (either in shared or in exclusive mode), so if there is any existing lock on the object, the transaction must wait.
- If a transaction first reads and then writes an object, it may upgrade its shared lock to an exclusive lock. The upgrade works the same as getting an exclusive lock directly.
- After a transaction has acquired the lock, it must continue to hold the lock until the end of the transaction (commit or abort). This is where the name “two-phase” comes from: the first phase (while the transaction is executing) is when the locks are acquired, and the second phase (at the end of the transaction) is when all the locks are released.
- The database automatically detects deadlocks between transactions and aborts one of them so that the others can make progress. The aborted transaction needs to be retried by the application.
performance of two-phase locking
downsides:
- transaction throughput and response times of queries are significantly worse under two-phase locking than under weak isolation.
- overhead of acquiring and releasing all those locks
- due to reduced concurrency
- deadlocks occur much more frequently under 2PL serializable isolation, after aborting needs to retry from application layer
Predicate locks
A supplement to two-phase locking:
- It works similarly to the shared/exclusive lock described earlier, but rather than belonging to a particular object (e.g., one row in a table), it belongs to all objects that match some search condition
A predicate lock restricts access as follows:
- If transaction A wants to read objects matching some condition, like in that SELECT query, it must acquire a shared-mode predicate lock on the conditions of the query. If another transaction B currently has an exclusive lock on any object matching those conditions, A must wait until B releases its lock before it is allowed to make its query.
- If transaction A wants to insert, update, or delete any object, it must first check whether either the old or the new value matches any existing predicate lock. If there is a matching predicate lock held by transaction B, then A must wait until B has committed or aborted before it can continue.
The key idea here is that a predicate lock applies even to objects that do not yet exist in the database, but which might be added in the future (phantoms).
If two-phase locking includes predicate locks, the database prevents all forms of write skew and other race conditions, and so its isolation becomes serializable.
Index-range locks
predicate locks do not perform well, use a simplified approximation of predicate locking in most practice.
index-range locking / next-key locking:
- simplify a predicate by making it match a greater set of objects
- attach locks to certain index
Reason:
- an approximation of the search condition is attached to one of the indexes
- if another transaction wants to insert, update, or delete a booking for the same room and/or an overlapping time period, it will have to update the same part of the index.
- In the process of doing so, it will encounter the shared lock, and it will be forced to wait until the lock is released.
This provides effective protection against phantoms and write skew.
- not as precise as predicate locks would be (they may lock a bigger range of objects than is strictly necessary to maintain serializability)
- much lower overheads, they are a good compromise.
If there is no suitable index where a range lock can be attached, the database can fall back to a shared lock on the entire table
Serializable Snapshot Isolation (SSI)
SSI is based on snapshot isolation—that is, all reads within a transaction are made from a consistent snapshot of the database
On top of snapshot isolation, SSI adds an algorithm for detecting serialization conflicts among writes and determining which transactions to abort.
Pessimistic versus optimistic concurrency control
pessimistic concurrency control:
- 2PL is a so-called pessimistic concurrency control mechanism
- based on the principle that if anything might possibly go wrong (as indicated by a lock held by another transaction), it’s better to wait until the situation is safe again before doing anything.
- like mutual exclusion
- Serial execution extremely pessimistic:
- equivalent to each transaction having an exclusive lock on the entire database
- compensate for the pessimism by making each transaction very fast to execute
optimistic concurrency control:
- serializable snapshot isolation:
- Optimistic in this context means that instead of blocking if something potentially dangerous happens, transactions continue anyway, in the hope that everything will turn out all right.
- When a transaction wants to commit, the database checks whether anything bad happened (i.e., whether isolation was violated)
- if so, the transaction is aborted and has to be retried
Decisions based on an outdated premise
Within the same transaction, there may be a causal dependency between the queries and the writes. In order to provide serializable isolation, the database must detect situations in which a transaction may have acted on an outdated premise and abort the transaction in that case.
How does the database know if a query result might have changed? There are two cases to consider:
- Detecting reads of a stale MVCC object version (uncommitted write occurred before the read)
- Detecting writes that affect prior reads (the write occurs after the read)
Detecting stale MVCC reads
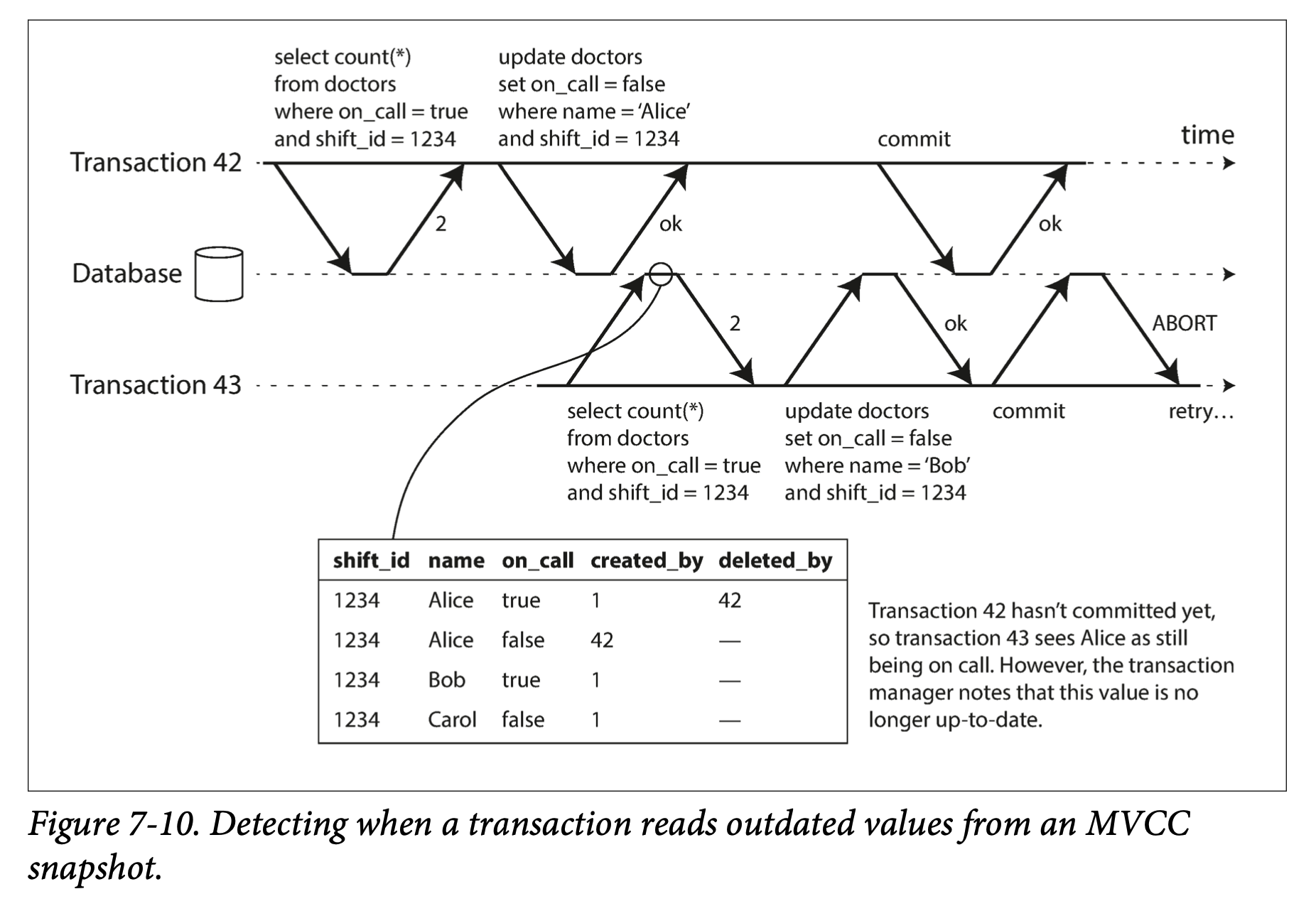
In order to prevent this anomaly, the database needs to track when a transaction ignores another transaction’s writes due to MVCC visibility rules. When the transaction wants to commit, the database checks whether any of the ignored writes have now been committed. If so, the transaction must be aborted.
Why wait until committing, Why not abort transaction immediately when the stale read is detected?:
- possibility of read-only transaction
- read may turn out not to have been stale after all
Detecting writes that affect prior reads
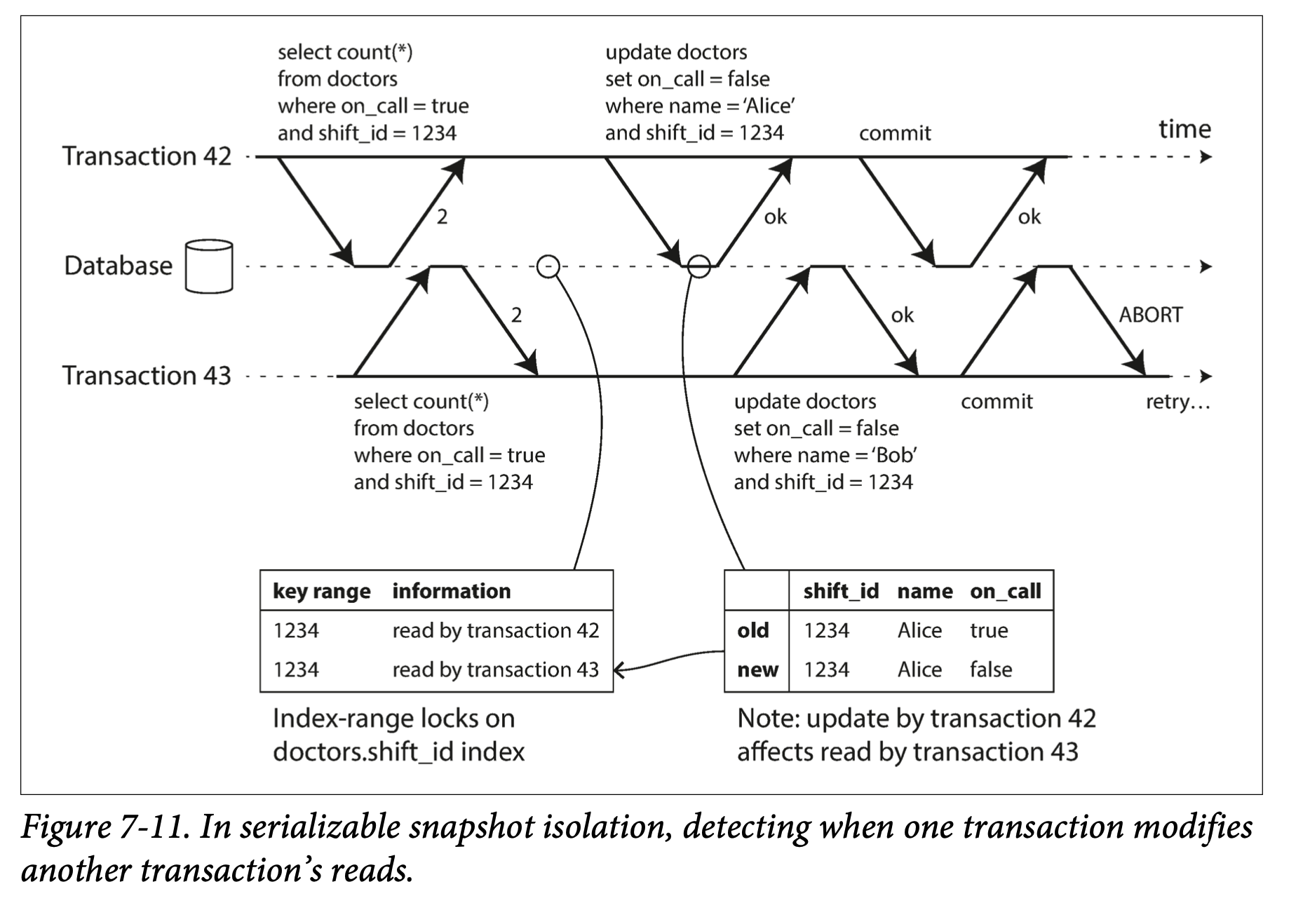
In Figure 7-11, transactions 42 and 43 both search for on-call doctors during shift 1234. If there is an index on shift_id, the database can use the index entry 1234 to record the fact that transactions 42 and 43 read this data. (If there is no index, this information can be tracked at the table level.) This information only needs to be kept for a while: after a transaction has finished (committed or aborted), and all concurrent transactions have finished, the database can forget what data it read.
When a transaction writes to the database, it must look in the indexes for any other transactions that have recently read the affected data. This process is similar to acquiring a write lock on the affected key range, but rather than blocking until the readers have committed, the lock acts as a tripwire: it simply notifies the transactions that the data they read may no longer be up to date.
In Figure 7-11, transaction 43 notifies transaction 42 that its prior read is outdated, and vice versa. Transaction 42 is first to commit, and it is successful: although transaction 43’s write affected 42, 43 hasn’t yet committed, so the write has not yet taken effect. However, when transaction 43 wants to commit, the conflicting write from 42 has already been committed, so 43 must abort.
Performance of serializable snapshot isolation
one trade-off is the granularity at which transactions’ reads and writes are tracked. If the database keeps track of each transaction’s activity in great detail, it can be precise about which transactions need to abort, but the bookkeeping overhead can become significant. Less detailed tracking is faster, but may lead to more transactions being aborted than strictly necessary.
Compared to two-phase locking, SSI:
- one transaction doesn’t need to block waiting for locks held by another transaction. writers don’t block readers, and vice versa.
- makes query latency much more predictable and less variable
- appealing for read-heavy workloads
Compared to serial execution, SSI:
- not limited to the throughput of a single CPU core
- can be used in a distributed system
The rate of aborts significantly affects the overall performance of SSI.
Summary
Dirty reads
- One client reads another client’s writes before they have been committed. The read committed isolation level and stronger levels prevent dirty reads.
Dirty writes
- One client overwrites data that another client has written, but not yet committed. Almost all transaction implementations prevent dirty writes.
Read skew (nonrepeatable reads)
- A client sees different parts of the database at different points in time. This issue is most commonly prevented with snapshot isolation, which allows a transaction to read from a consistent snapshot at one point in time. It is usually implemented with multi-version concurrency control (MVCC).
Lost updates
- Two clients concurrently perform a read-modify-write cycle. One overwrites the other’s write without incorporating its changes, so data is lost. Some implementations of snapshot isolation prevent this anomaly automatically, while others require a manual lock (SELECT FOR UPDATE).
Write skew
- A transaction reads something, makes a decision based on the value it saw, and writes the decision to the database. However, by the time the write is made, the premise of the decision is no longer true. Only serializable isolation prevents this anomaly.
Phantom reads
- A transaction reads objects that match some search condition. Another client makes a write that affects the results of that search. Snapshot isolation prevents straightforward phantom reads, but phantoms in the context of write skew require special treatment, such as index-range locks.
Weak isolation levels protect against some of those anomalies but leave application developer to handle others manually (e.g., using explicit locking).
Only serializable isolation protects against all of these issues.
Literally executing transactions in a serial order
- If you can make each transaction very fast to execute, and the transaction throughput is low enough to process on a single CPU core, this is a simple and effective option.
Two-phase locking
- For decades this has been the standard way of implementing serializability, but many applications avoid using it because of its performance characteristics.
Serializable snapshot isolation (SSI)
- A fairly new algorithm that avoids most of the downsides of the previous approaches. It uses an optimistic approach, allowing transactions to proceed without blocking. When a transaction wants to commit, it is checked, and it is aborted if the execution was not serializable.
Trouble with Distributed Systems
Faults and Partial Failures
partial failure:
- In a distributed system, there may well be some parts of the system that are broken in some unpredictable way, even though other parts of the system are working fine.
- The difficulty is that partial failures are nondeterministic
This nondeterminism and possibility of partial failures is what makes distributed systems hard to work with.
Cloud Computing and Supercomputing
how to build large-scale computing systems:
- high-performance computing (HPC):
- At one end of the scale is the field of high-performance computing (HPC)
- Supercomputers with thousands of CPUs
- cloud computing:
- At the other end of the scale is cloud computing
- multi-tenant datacenters, commodity computers connected with an IP network (often Ethernet)
- Traditional enterprise datacenters lie somewhere between these extremes.
Unreliable Networks
shared-nothing systems:
- In a shared-nothing system, each node has its own private memory and disk, and nodes communicate with each other only over network.
Shared-nothing is not the only way of building systems, but it has become the dominant approach for building internet services:
- cheap because it requires no special hardware
- make use of commoditized cloud computing services
- can achieve high reliability through redundancy across multiple geographically distributed datacenters.
network partition or netsplit:
- one part of the network is cut off from the rest due to a network fault
Detecting Faults
Rapid feedback about a remote node being down is useful, but you can’t count on it.
Even if TCP acknowledges that a packet was delivered, the application may have crashed before handling it. If you want to be sure that a request was successful, you need a positive response from the application itself.
In general you have to assume that you will get no response at all.
- wait for a timeout to elapse, and eventually declare the node dead if you don’t hear back within the timeout.
Timeouts and Unbounded Delays
Prematurely declaring a node dead is problematic:
- if the node is actually alive and in the middle of performing some action (for example, sending an email), and another node takes over, the action may end up being performed twice.
asynchronous networks have unbounded delays (that is, they try to deliver packets as quickly as possible, but there is no upper limit on the time it may take for a packet to arrive)
most server implementations cannot guarantee that they can handle requests within some maximum time
Unreliable Clocks
It is possible to synchronize clocks to some degree:
- the most commonly used mechanism is the Network Time Protocol (NTP), which allows the computer clock to be adjusted according to the time reported by a group of servers.
Monotonic Versus Time-of-Day Clocks
Time-of-day clock:
- A time-of-day clock is a clock that tells you the current time of day according to some calendar (also known as wall-clock time)
- Time-of-day clocks are usually synchronized with NTP
monotonic clock:
- A monotonic clock is a clock that always moves forward, and never jumps backward.
- suitable for measuring elapsed time
- the absolute value of the clock is meaningless
Knowledge, Truth, and Lies
The Truth Is Defined by the Majority
a node cannot necessarily trust its own judgment of a situation
Fencing tokens:
- we need to ensure that a node that is under a false belief of being “the chosen one” cannot disrupt the rest of the system.
- every time the lock server grants a lock or lease, it also returns a fencing token, a number that increases every time a lock is granted
- require that every time a client sends a write request to the storage service, it must include its current fencing token.
If ZooKeeper is used as lock service, the transaction ID zxid or the node version cversion can be used as fencing token.
this mechanism requires the resource itself to take an active role in checking tokens by rejecting any writes with an older token than one that has already been processed—it is not sufficient to rely on clients checking their lock status themselves.
Byzantine Faults
Byzantine fault:
- A Byzantine fault is a fault that is caused by a malicious actor, such as a hacker or a disgruntled employee.
- Byzantine faults are the most difficult type of fault to deal with, because they can be caused by anything from a hardware failure to a malicious attack.
Byzantine fault-tolerant:
- A Byzantine fault-tolerant system is a system that can continue to operate correctly even in the presence of Byzantine faults.
System Model and Reality
Regard to timing assumptions, three system models are in common use:
Synchronous model
- The synchronous model assumes bounded network delay, bounded process pauses, and bounded clock error. This does not imply exactly synchronized clocks or zero network delay; it just means you know that network delay, pauses, and clock drift will never exceed some fixed upper bound. The synchronous model is not a realistic model of most practical systems, because (as discussed in this chapter) unbounded delays and pauses do occur.
Partially synchronous model
- Partial synchrony means that a system behaves like a synchronous system most of the time, but it sometimes exceeds the bounds for network delay, process pauses, and clock drift. This is a realistic model of many systems: most of the time, networks and processes are quite well behaved—otherwise we would never be able to get anything done—but we have to reckon with the fact that any timing assumptions may be shattered occasionally. When this happens, network delay, pauses, and clock error may become arbitrarily large.
Asynchronous model
- In this model, an algorithm is not allowed to make any timing assumptions—in fact, it does not even have a clock (so it cannot use timeouts). Some algorithms can be designed for the asynchronous model, but it is very restrictive.
The three most common system models for nodes are:
Crash-stop faults
- In the crash-stop model, an algorithm may assume that a node can fail in only one way, namely by crashing. This means that the node may suddenly stop responding at any moment, and thereafter that node is gone forever—it never comes back.
Crash-recovery faults
- We assume that nodes may crash at any moment, and perhaps start responding again after some unknown time. In the crash-recovery model, nodes are assumed to have stable storage (i.e., nonvolatile disk storage) that is preserved across crashes, while the in-memory state is assumed to be lost.
Byzantine (arbitrary) faults
- Nodes may do absolutely anything, including trying to trick and deceive other nodes, as described in the last section.
For modeling real systems, the partially synchronous model with crash-recovery faults is generally the most useful model.
Safety and liveness
-
If a safety property is violated, we can point at a particular point in time at which it was broken (for example, if the uniqueness property was violated, we can identify the particular operation in which a duplicate fencing token was returned). After a safety property has been violated, the violation cannot be undone—the damage is already done.
-
A liveness property works the other way round: it may not hold at some point in time (for example, a node may have sent a request but not yet received a response), but there is always hope that it may be satisfied in the future (namely by receiving a response).