A simple note for system design.
From System Design Interview Volume 2 by Alex Xu
Proximity Service
Basic requirements
- functional
- Return all businesses based on a user’s location (latitude and longitude pair) and radius.
- Business owners can add, delete or update a business, but this information doesn’t need to be reflected in real-time.
- Customers can view detailed information about a business.
- non-functional
- Highly availability and scalability: able to handle spike in traffic
- Low latency
- Data privacy: comply data privacy laws like GDPR and CCPA when designing LBS (Location-Based Service) systems.
- “Back-of-the-envelope estimation”
- assume DAU (Daily Active Users) = 100 million
- assume 200 million businesses
- seconds in day: 24 * 60 * 60 = 86400, round to 100,000
- assume each user makes 5 requests per day
- QPS = 100 million * 5 / 100,000 = 5000
High-level design and Buy-in
- API:
- “GET /v1/search/nearby”
- query parameters: latitude, longitude, radius
- response: list of businesses objects with their details
- only for search results, details page will be handled by another API
- “POST /v1/businesses”
- “GET /v1/businesses/{business_id}”
- “PUT /v1/businesses/{business_id}”
- “DELETE /v1/businesses/{business_id}”
- “GET /v1/search/nearby”
- Data model: two main factors: r/w ratio and scheme design
- r/w ratio:
- read volume is much higher:
- Search for nearby businesses are commonly used.
- View the detailed information of a business.
- For a read-heavy system, a relational database such as MySQL can be a good fit.
- read volume is much higher:
- schema design:
- Business table: “contains detailed information about a business.”
- business_id as primary key
- Geo index table: used for effecient processing of spatial operations, discussed later.
- Business table: “contains detailed information about a business.”
- r/w ratio:
- High-level design:
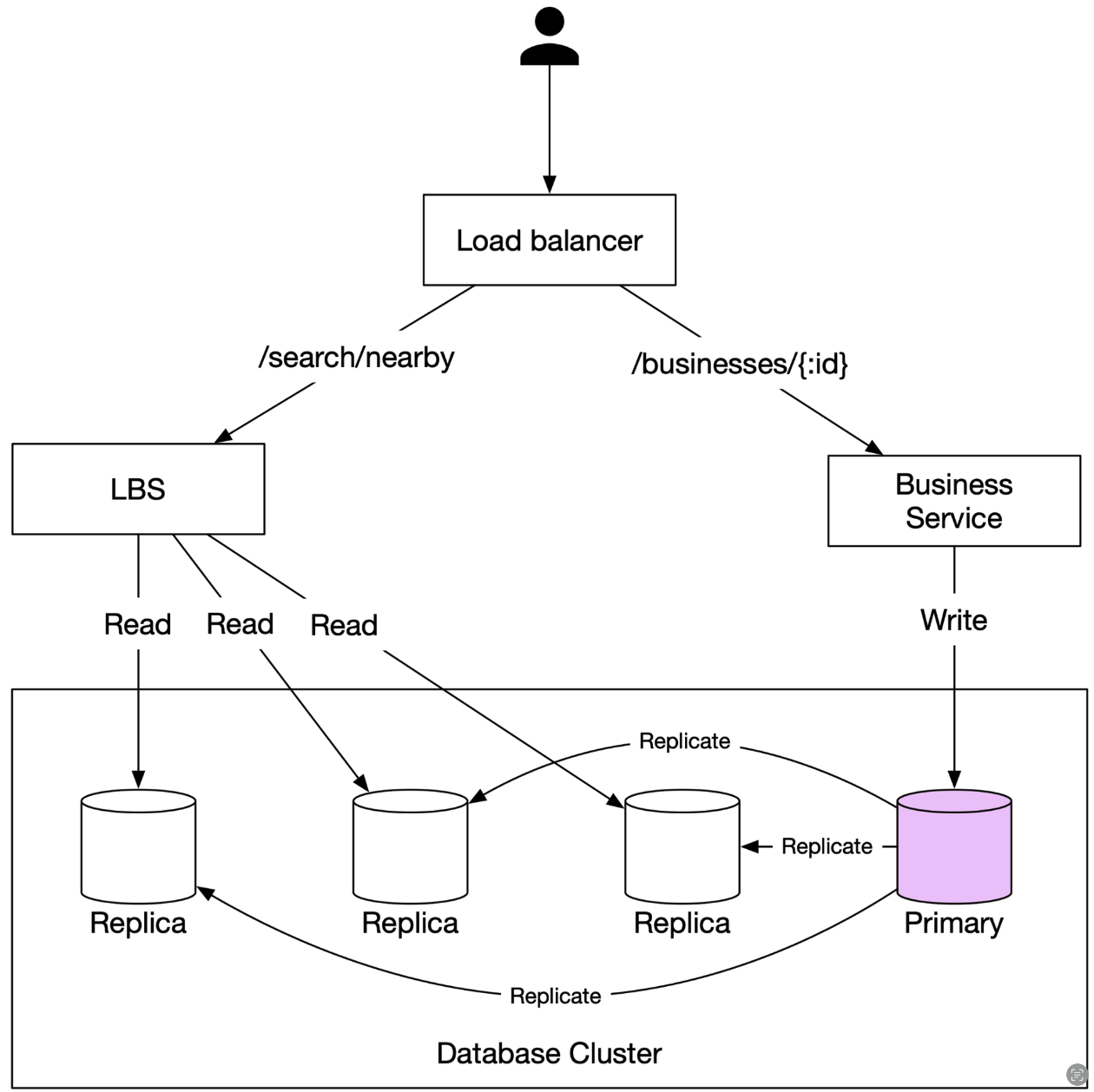
- components
- Load balancer: distribute incoming requests to multiple servers
- LBS (Location-Based Service):
- read heavy system, with no write requests
- high QPS
- stateless service, can be scaled horizontally
- Business owner service:
- CRUD operations for businesses, mainly write operations, not high QPS
- fetch details of a business from customers, high QPS
- Database cluster:
- use primary-secondary setup
- “primary database handles all the write operations, and multiple replicas are used for read operations. ”
- “Data is saved to the primary database first and then replicated to replicas.”
- “Due to the replication delay, there might be some discrepancy between data read by the LBS and the data written to the primary database. This inconsistency is usually not an issue because business information doesn’t need to be updated in real-time.”
- use primary-secondary setup
- scalability for LBS and Business service:
- both are stateless services, can be scaled horizontally
- Algorithms to find nearby businesses:
- possible existing solution:
- “use existing geospatial databases such as Geohash in Redis or Postgres with PostGIS extension”
- “Option 1: Two-dimensional search”
- example:
SELECT business_id, latitude, longitude, FROM businessWHERE (latitude BETWEEN {:my_lat} - radius AND {:my_lat} + radius) AND (longitude BETWEEN {:my_long} - radius AND {:my_long} + radius)
- example:
- Option 2: changing geospatial indexing approace
- high-level idea: divide the map into smaller regions amd build indexes for fast search
- real world Choices:
- Hash: even grid, geohash, cartesian tiers
- Tree: quadtree, Google S2, RTree
- evenly divided grid:
- problem with even grid: produce uneven distribution of data
- use more fine-grained grid for areas with high density of businesses
- geohash:
- how it works:
- Geohash algorithms work by recursively dividing the world into smaller and smaller grids with each additional bit.
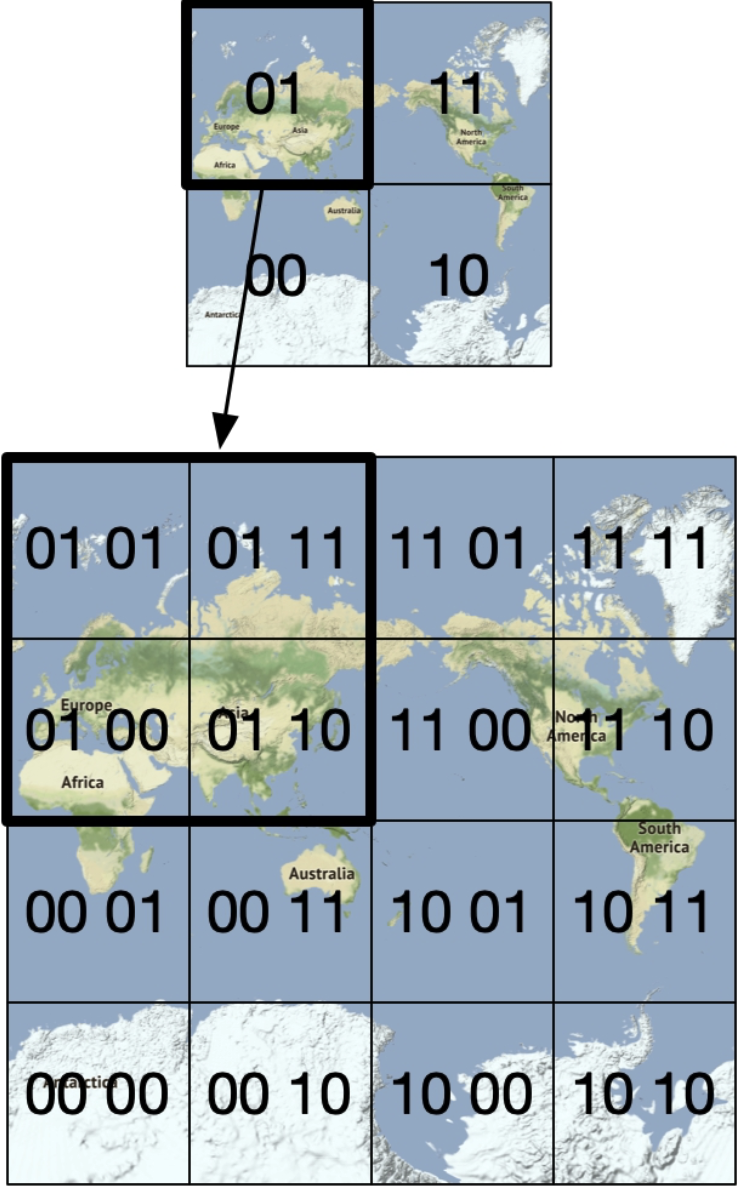
- Repeat this subdivision until the grid size is within the precision desired
- specs
- Geohash usually uses base32 representation
- “1001 10110 01001 10000 11011 11010 (base32 in binary) → 9q9hvu (base32)”
- 12 level of precision, usually use 4 to 6
- Geohashing guarantees that the longer a shared prefix is between two geohashes, the closer they are.
- Geohash usually uses base32 representation
- Boundary issues:
- usually use a relationship table to decide the map between level and user input radius
- issue 1:
- two locations can be very close but have no shared prefix at all.
- This is because two close locations on either side of the equator or prime meridian belong to different ‘halves’ of the world.
- issue 2:
- two positions can have a long shared prefix but belong to different grids.
- Bonus Question: Not enough businesses
-
- keep it simple, just return empty result
-
- increase the search radius
- remove the last digit of the geohash to get a larger area
- if still not enough, keep removing the last digit until enough results are found or reach a max radius
- increase the search radius
-
- how it works:
- Option 3: Quadtree
- how it works:
- recursively divide the map into four quadrants or regions
- in-memory data structure solution, the data structure is built at server startup time
- how it works:
- Option 4: Google S2
- in memory solution like Quadtree
- maps a sphere to a 1D index based in the Hilbert curve
- “two points that are close to each other on the Hilbert curve are close in 1D space”
- great for geofencing because can cover arbitrary areas with varying level
- “Another advantage of S2 is its Region Cover algorithm”
- possible existing solution:
Deep Dive
- scale out the database
- Business table: sharding
- Geospatial index table:
- Option1: index == geohash + list_of_business_id
- Option2: each_row == geohash + business_id
- Option2 is recommended:
- “For option 1, to update a business, we need to fetch the array of business_ids and scan the whole array to find the business to update. When inserting a new business, we have to scan the entire array to make sure there is no duplicate. ”
- “For option 2, if we have two columns with a compound key of (geohash, business_id), the addition and removal of a business are very simple. There would be no need to lock anything.”
- Caching
- really need a cache? situations that cache “is not a solid win”
- read-heavy workload and dataset is small enough to fit in the working set (ram of db server)
- read perf as bottleneck: add read replica to improve throughput
- Cache Key:
- “location coordinates (latitude and longitude) of the user”, with issues:
- “Location coordinates returned from mobile phones are not accurate as they are just the best estimation [32]. Even if you don’t move, the results might be slightly different each time you fetch coordinates on your phone.”
- “A user can move from one location to another, causing location coordinates to change slightly. For most applications, this change is not meaningful.”
- “small changes in location should still map to the same cache key.
- The geohash/quadtree solution mentioned earlier handles this problem well because all businesses within a grid map to the same geohash.”
- “location coordinates (latitude and longitude) of the user”, with issues:
- “Types of data to cache”
- geohash - list of business IDS in the grid
- businessId - Business Obj
- really need a cache? situations that cache “is not a solid win”
NearBy Friends
Basic requirements
Scope and design standard
- “nearby”: 5miles
- straight-line distance
- “1 billion users and 10% of them use the nearby friends feature”, dau = 10 million
- need to store location history
- assume inactive friends will no longer to be shown
- “The location refresh interval is 30 seconds.”
- human walk slow
- “On average, a user has 400 friends. Assume all of them use the “nearby friends” feature.”
- “Location update QPS = 10 million / 30 = ~334,000”
Functional and non-functional requirements
- functional
- Users should be able to see nearby friends on their mobile apps. Each entry in the nearby friend list has a distance and a timestamp indicating when the distance was last updated.
- Nearby friend lists should be updated every few seconds.
- Non-functional requirements
- Low latency. It’s important to receive location updates from friends without too much delay.
- Reliability. The system needs to be reliable overall, but occasional data point loss is acceptable.
- Eventual consistency. The location data store doesn’t need strong consistency. A few seconds delay in receiving location data in different replicas is acceptable.
High level design & buy-in
High level design
baisc ideas:
- shared backend
- “Receive location updates from all active users.
- For each location update, find all the active friends who should receive it and forward it to those users’ devices.
- If the distance between two users is over a certain threshold, do not forward it to the recipient’s device.”
- problem: “to do this at scale is not easy. We have 10 million active users. With each user updating the location information every 30 seconds, there are 333K updates per second. If on average each user has 400 friends, and we further assume that roughly 10% of those friends are online and nearby, every second the backend forwards 333K x 400 x 10% = 13 million location updates per second. That is a lot of updates to forward.”
- proposed design
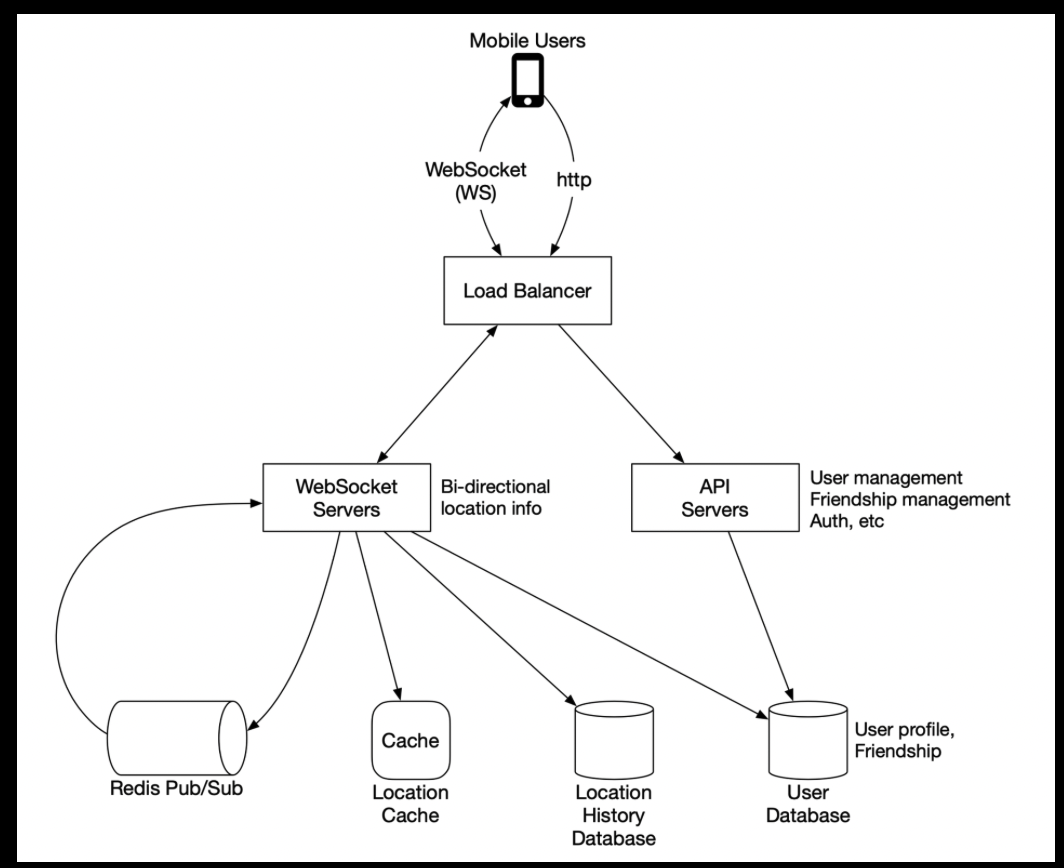
- “Websocket servers
- This is a cluster of stateful servers that handles the near real-time update of friends’ locations. Each client maintains one persistent WebSocket connection to one of these servers. When there is a location update from a friend who is within the search radius, the update is sent on this connection to the client.”
- “Another major responsibility of the WebSocket servers is to handle client initialization for the “nearby friends” feature. It seeds the mobile client with the locations of all nearby online friends.”
- Redis location cache
- “Redis is used to store the most recent location data for each active user. There is a Time to Live (TTL) set on each entry in the cache.
- When the TTL expires, the user is no longer active and the location data is expunged from the cache. Every update refreshes the TTL.
- “Location history database
- This database stores users’ historical location data. It is not directly related to the “nearby friends” feature.
- “Websocket servers
- how it works
- “In this design, location updates received via the WebSocket server are published to the user’s own channel in the Redis pub/sub server. A dedicated WebSocket connection handler for each active friend subscribes to the channel. When there is a location update, the WebSocket handler function gets invoked, and for each active friend, the function recomputes the distance. If the new distance is within the search radius, the new location and timestamp are sent via the WebSocket connection to the friend’s client. Other message buses with lightweight channels could also be used.”
- “The mobile client sends a location update to the load balancer.
- The load balancer forwards the location update to the persistent connection on the WebSocket server for that client.
- The WebSocket server saves the location data to the location history database.The WebSocket server updates the new location in the location cache. The update refreshes the TTL.
- The WebSocket server saves the new location in a variable in the user’s WebSocket connection handler for subsequent distance calculations.The WebSocket server publishes the new location to the user’s channel in the Redis pub/sub server.
- When Redis pub/sub receives a location update on a channel, it broadcasts the update to all the subscribers (WebSocket connection handlers). In this case, the subscribers are all the online friends of the user sending the update. For each subscriber (i.e., for each of the user’s friends), its WebSocket connection handler would receive the user location update.
- On receiving the message, the WebSocket server, on which the connection handler lives, computes the distance between the user sending the new location (the location data is in the message) and the subscriber (the location data is stored in a variable with the WebSocket connection handler for the subscriber).
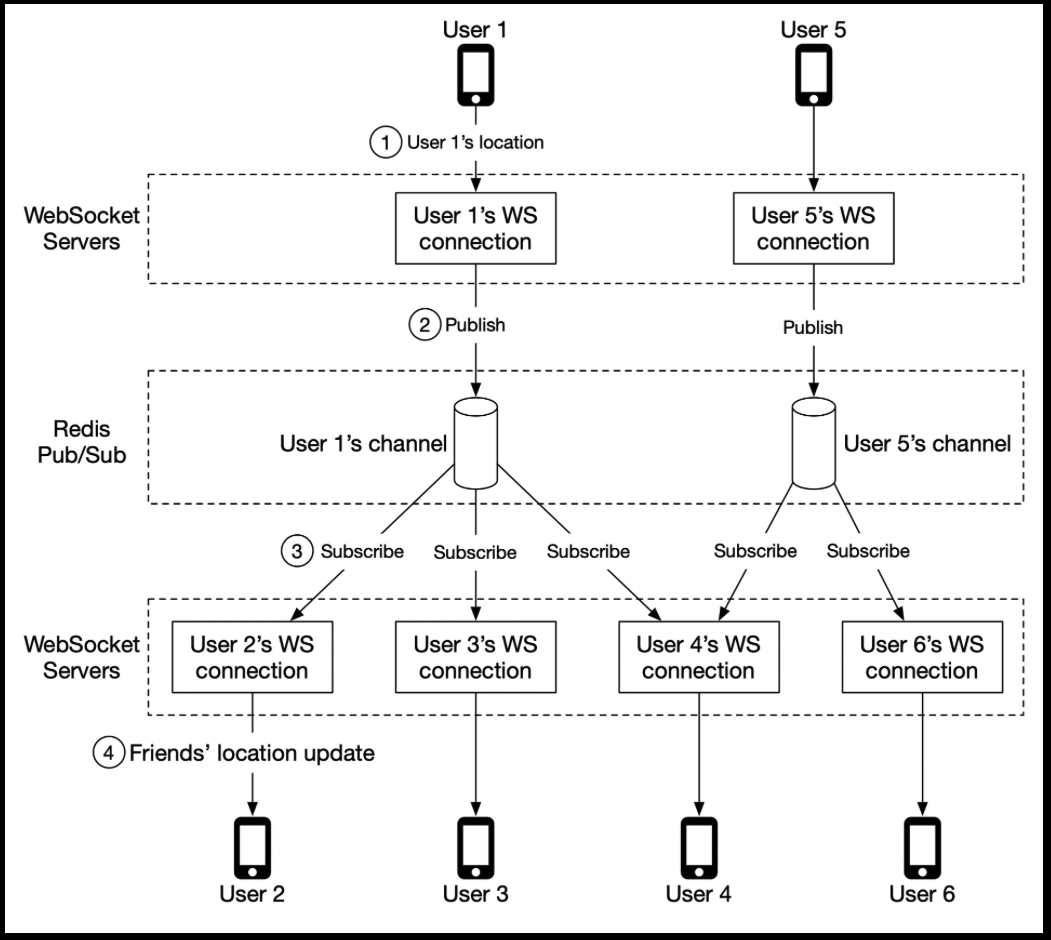
- “In this design, location updates received via the WebSocket server are published to the user’s own channel in the Redis pub/sub server. A dedicated WebSocket connection handler for each active friend subscribes to the channel. When there is a location update, the WebSocket handler function gets invoked, and for each active friend, the function recomputes the distance. If the new distance is within the search radius, the new location and timestamp are sent via the WebSocket connection to the friend’s client. Other message buses with lightweight channels could also be used.”
Data Model
- location cache
- redis, ttl, no need for durably store
- key-value: user_id-{latitude, longtitude, timestamp}
- location history database
- schema: userid-latitude-longtitude-timestamp
- “handles the heavy-write workload well and can be horizontally scaled”
- might need shard, use user_id to shard
- relational or non-relational both acceptable
Design Deep Dive
Scalability
- API server
- easy to scale out, stateless server
- WebSocket server
- process of scale (stateful so more complicated)
- drain connections: “mark a node as “draining” at the load balancer so that no new WebSocket connections will be routed to the draining server.”
- “Once all the existing connections are closed (or after a reasonably long wait), the server is then removed.”
- process of scale (stateful so more complicated)
- Client Initialization
- “mobile client on startup establishes a persistent WebSocket connection with one of the WebSocket server instances. Each connection is long-running.”
- “When a WebSocket connection is initialized, the client sends the initial location of the user, and the server performs the following tasks in the WebSocket connection handler.”
- “It updates the user’s location in the location cache.
- It saves the location in a variable of the connection handler for subsequent calculations.
- It loads all the user’s friends from the user database.
- It makes a batched request to the location cache to fetch the locations for all the friends. Note that because we set a TTL on each entry in the location cache to match our inactivity timeout period, if a friend is inactive then their location will not be in the location cache.
- For each location returned by the cache, the server computes the distance between the user and the friend at that location. If the distance is within the search radius, the friend’s profile, location, and last updated timestamp are returned over the WebSocket connection to the client.
- For each friend, the server subscribes to the friend’s channel in the Redis pub/sub server. We will explain our use of Redis pub/sub shortly. Since creating a new channel is cheap, the user subscribes to all active and inactive friends. The inactive friends will take up a small amount of memory on the Redis pub/sub server, but they will not consume any CPU or I/O (since they do not publish updates,) until they come online.
- It sends the user’s current location to the user’s channel in the Redis pub/sub server.”
- User DB
- scalable by sharding based on user ID
- Location cache
- use redis to cache the most recent locations of all the active users
- set a TTL on each key, renewed on every update
- Redis pub/sub server
- “The pub/sub server is used as a routing layer to direct messages (location updates) from one user to all the online friends.”
- “choose Redis pub/sub because it is very lightweight to create new channels”
- “A new channel is created when someone subscribes to it”
- “If a message is published to a channel that has no subscribers, the message is dropped, placing very little load on the server.”
- what actually happens in redis:
- “When a channel is created, Redis uses a small amount of memory to maintain a hash table and a linked list to track the subscribers.”
- “If there is no update on a channel when a user is offline, no CPU cycles are used after a channel is created. ”
- “We assign a unique channel to every user who uses the “nearby friends” feature. A user would, upon app initialization, subscribe to each friend’s channel, whether the friend is online or not. This simplifies the design since the backend does not need to handle subscribing to a friend’s channel when the friend becomes active, or handling unsubscribing when the friend becomes inactive.”
- “The pub/sub server is used as a routing layer to direct messages (location updates) from one user to all the online friends.”
- caculation for redis pub/sub server
- Memory usage
- “Assuming a channel is allocated for each user who uses the nearby friends feature, we need 100 million channels (1 billion x 10%). ”
- “Assuming that on average a user has 100 active friends using this feature (this includes friends who are nearby, or not), and it takes about 20 bytes of pointers in the internal hash table and linked list to track each subscriber, it will need about 200 GB (100 million x 20 bytes x 100 friends / 109 = 200 GB) to hold all the channels. ”
- “For a modern server with 100 GB of memory, we will need about 2 Redis pub/sub servers to hold all the channels.”
- CPU usage
- “As previously calculated, the pub/sub server pushes about 13 million updates per second to subscribers. ”
- “let’s pick a conservative number and assume that a modern server with a gigabit network could handle about 100,000 subscriber pushes per second. Given how small our location update messages are, this number is likely to be conservative. Using this conservative estimate, we will need to distribute the load among 13 million / 100,000 = 130 Redis servers.”
- conclusion
- “The bottleneck of Redis pub/sub server is the CPU usage, not the memory usage.”
- “To support our scale, we need a distributed Redis pub/sub cluster.”
- Memory usage
- “Distributed Redis pub/sub server cluster”
- “channels are independent of each other. This makes it relatively easy to spread the channels among multiple pub/sub servers by sharding, based on the publisher’s user ID. ”
- what we need for cluster management:
- “The ability to keep a list of servers in the service discovery component, and a simple UI or API to update it. ”
- “The ability for clients (in this case, the WebSocket servers) to subscribe to any updates to the “Value” (Redis pub/sub servers).”
- solution: hash ring/ consistent hashing
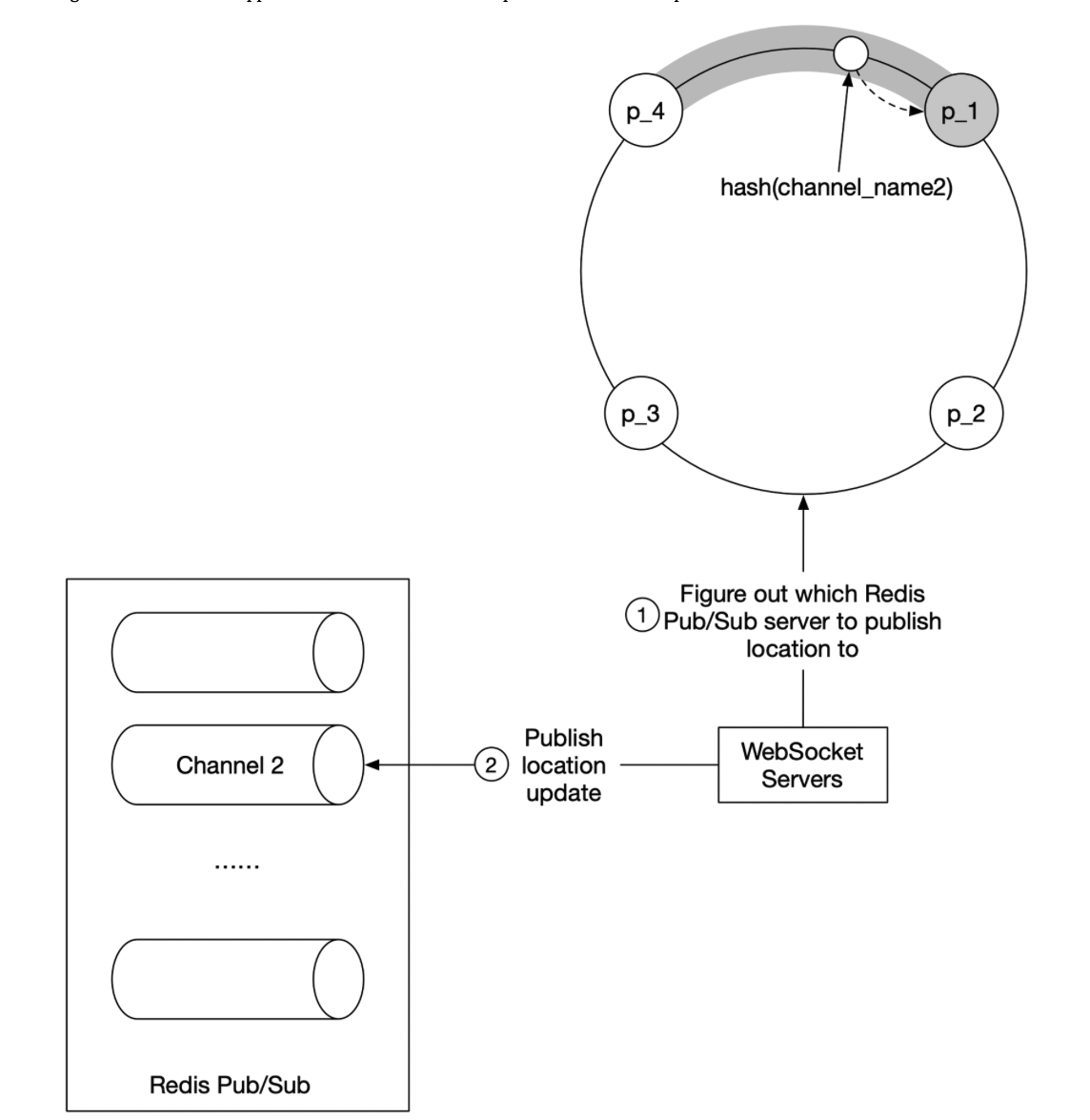
- “The WebSocket server consults the hash ring to determine the Redis pub/sub server to write to. The source of truth is stored in service discovery, but for efficiency, a copy of the hash ring could be cached on each WebSocket server. The WebSocket server subscribes to any updates on the hash ring to keep its local in-memory copy up to date.
- WebSocket server publishes the location update to the user’s channel on that Redis pub/sub server.
- Subscribing to a channel for location updates uses the same mechanism.”
- scale problem for Redis pub/sub servers
- background
- “The messages sent on a pub/sub channel are not persisted in memory or on disk. They are sent to all subscribers of the channel and removed immediately after. If there are no subscribers, the messages are just dropped. In this sense, the data going through the pub/sub channel is stateless.”
- “However, there are indeed states stored in the pub/sub servers for the channels. Specifically, the subscriber list for each channel is a key piece of the states tracked by the pub/sub servers. ”
- “In this sense, a pub/sub server is stateful, and coordination with all subscribers to the server must be orchestrated to minimize service interruptions.”
- “With stateful clusters, scaling up or down has some operational overhead and risks, so it should be done with careful planning.”
- “When we resize a cluster, many channels will be moved to different servers on the hash ring. When the service discovery component notifies all the WebSocket servers of the hash ring update, there will be a ton of resubscription requests.”
- “During these mass resubscription events, some location updates might be missed by the clients. Although occasional misses are acceptable for our design, we should minimize the occurrences.
- Because of the potential interruptions, resizing should be done when usage is at its lowest in the day.”
- “How is resizing actually done? It is quite simple. Follow these steps:
- Determine the new ring size, and if scaling up, provision enough new servers.
- Update the keys of the hash ring with the new content.
- Monitor your dashboard. There should be some spike in CPU usage in the WebSocket cluster.”
- background
Extra credit
Nearby random person
- “One way to do this while leveraging our design is to add a pool of pub/sub channels by geohash.”
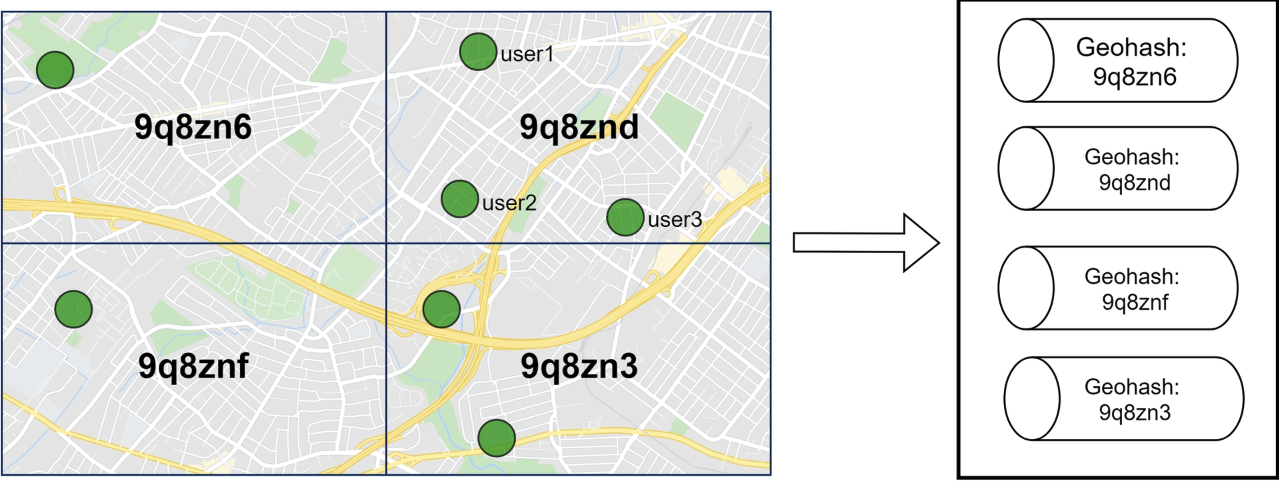
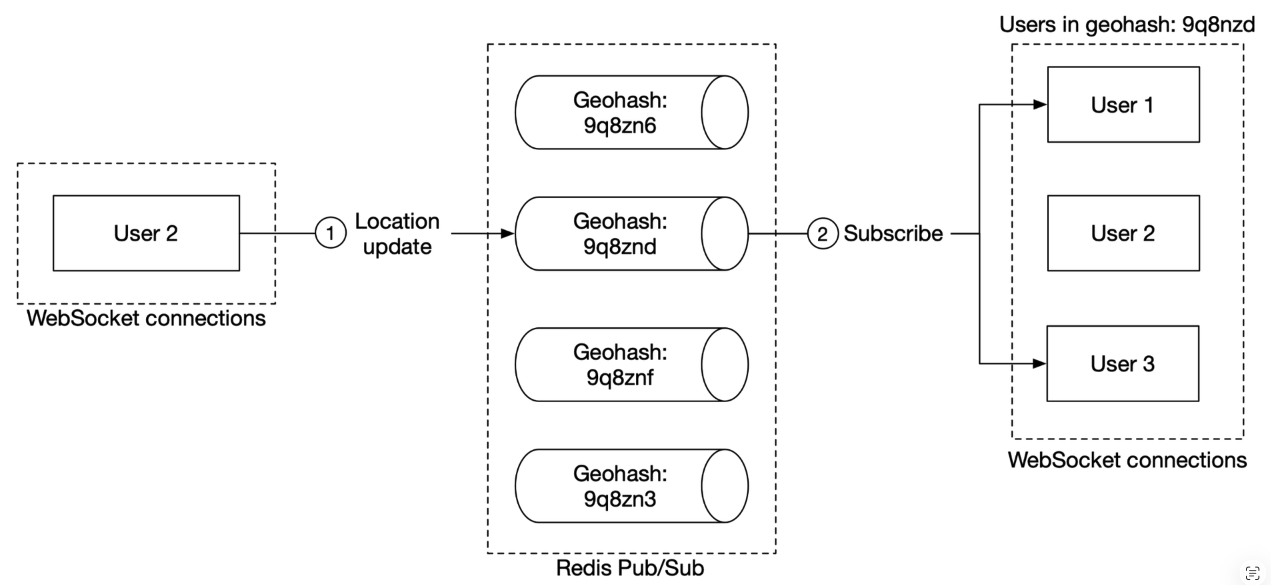
- “To handle people who are close to the border of a geohash grid, every client could subscribe to the geohash the user is in and the eight surrounding geohash grids.”
“Alternative to Redis pub/sub”
- Erlang
- “implement the WebSocket service in Erlang, and also replace the entire cluster of Redis pub/sub with a distributed Erlang application. ”
Google Maps
Basic requirements
- functional
- basic functionality
- “location update, navigation, ETA, and map rendering”
- “How large is the road data”
- “terabytes (TBs) of raw data”
- “take traffic conditions into consideration”
- support different travel modes: walking, driving, bus
- basic functionality
- non-functional
- “Accuracy: Users should not be given the wrong directions.
- Smooth navigation: On the client-side, users should experience very smooth map rendering.
- Data and battery usage: The client should use as little data and energy as possible. This is very important for mobile devices.
- General availability and scalability requirements.”
Background Info
- map renderring
- “map rendering is tiling”: “The client only downloads the relevant tiles for the area the user is in and stitches them together like a mosaic for display.”
- “There are distinct sets of tiles at different zoom levels”:
-
“Road data processing for navigation algorithms”
- “variations of Dijkstra’s or A* pathfinding algorithms”
- “all these algorithms operate on a graph data structure, where intersections are nodes and roads are edges of the graph”
- “The pathfinding performance for most of these algorithms is extremely sensitive to the size of the graph. ”
- “The graph needs to be broken up into manageable units for these algorithms to work at our design scale.”
- grids routing tiles:
- “employing a similar subdivision technique as geohashing, we divide the world into small grids. For each grid, we convert the roads within the grid into a small graph data structure that consists of the nodes (intersections) and edges (roads) inside the geographical area covered by the grid.”
- “Each routing tile holds references to all the other tiles it connects to. This is how the routing algorithms can stitch together a bigger road graph as it traverses these interconnected routing tiles.”
- “variations of Dijkstra’s or A* pathfinding algorithms”
Basic estimation
Storage demand
- “Map of the world”
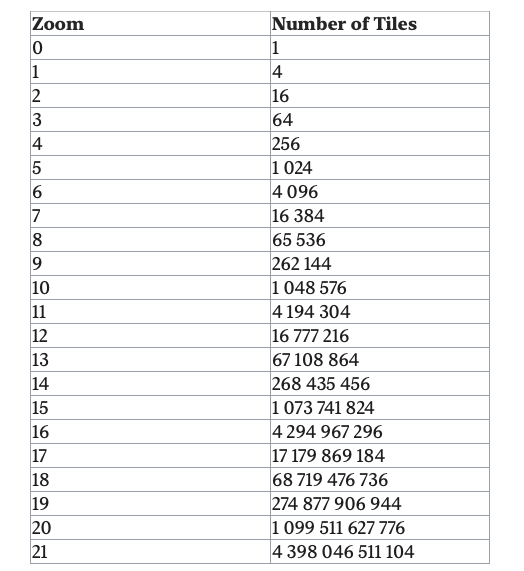
- “At zoom level 21, there are about 4.3 trillion tiles (Table 1). Let’s assume that each tile is a 256 x 256 pixel compressed PNG image, with the image size of about 100 KB. The entire set at the highest zoom level would need about 4.4 trillion x 100KB = 440 PB.”
- “90% of the world’s surface is natural and mostly uninhabited areas like oceans, deserts, lakes, and mountains. Since these areas are highly compressible as images, we could conservatively reduce the storage estimate by 80-90%.”
- “That would reduce the storage size to a range of 44 to 88 PB. Let’s pick a simple round number of 50 PB.”
- “At each lower zoom level, the number of tiles for both north-south and east-west directions drops by half. This results in a total reduction of the number of tiles by 4x, which drops the storage size for the zoom level also by 4x. ”
- “math for the total size is a series: 50 + 50/4 + 50/16 + 50/64 + … = ~67 PB. This is just a rough estimate. It is good enough to know that we need roughly about 100 PB to store all the map tiles at varying levels of detail.”
- Server throughput
- “two main types of requests”
- navigation requests: “sent by the clients to initiate a navigation session”
- location update requests: “sent by the client as the user moves around during a navigation session”
- “1 billion DAU, and each user on average uses navigation 5 times for a total of 35 minutes per week. This translates to 35 billion minutes per week or 5 billion minutes per day. Navigation QPS: 1 billion x 5 / 7 / 105 = ~7,200”
- “Assume peak QPS is five times the average. Peak QPS for navigation: 7200 x 5 = 36,000.”
- “Next, let’s estimate the throughput for location update requests. One simple approach would be to send GPS coordinates every second, which results in 300 billion (5 billion minutes x 60) requests per day, or 3 million QPS (300 billion requests / 105 = 3 million). However, the client may not need to send a GPS update every second. We can batch these on the client and send them at a much lower frequency (for example, every 15 seconds or 30 seconds) to reduce the write QPS. The actual frequency could depend on factors such as how fast the user moves. If they are stuck in traffic, a client can slow down the GPS updates. In our design, we assume GPS updates are batched and then sent to the server every 15 seconds. With this batched approach, the QPS is reduced to 200,000 (3 million / 15).
- Assume peak QPS is five times the average. Peak QPS for location updates = 200,000 x 5 = 1 million.”
High level design and Buy-in
High-level design
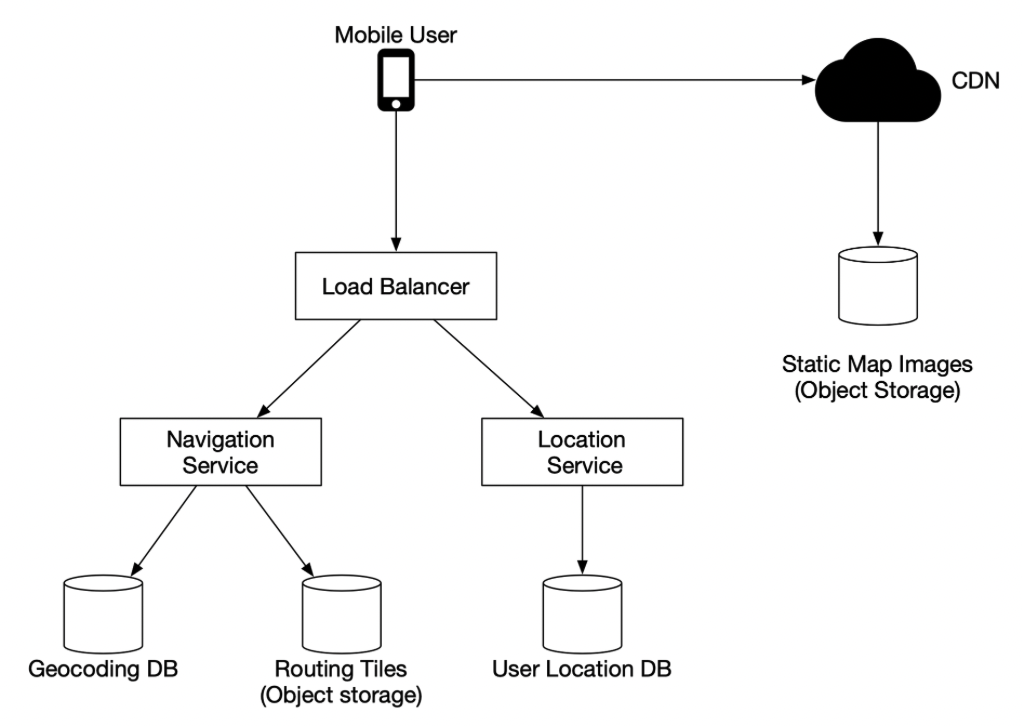
- Location service
- “location service is responsible for recording a user’s location update.”
- “The basic design calls for the clients to send location updates every X seconds, where X is a configurable interval. ”
- “Location history can be buffered on the client and sent in batch to the server at a much lower frequency.”
- “ even when location updates are batched, the write volume is still very high. We need a database that is optimized for high write volume and is highly scalable, such as Cassandra.
- We may also need to log location data using a stream processing engine such as Kafka for further processing. ”
- Navigation service
- “This component is responsible for finding a reasonably fast route from point A to point B. ”
- Map randering
- Option 1
- “The server builds the map tiles on the fly, based on the client location and zoom level of the client viewport.”
- disadvantage:
- “It puts a huge load on the server cluster to generate every map tile dynamically.”
- “Since the map tiles are dynamically generated, it is hard to take advantage of caching.”
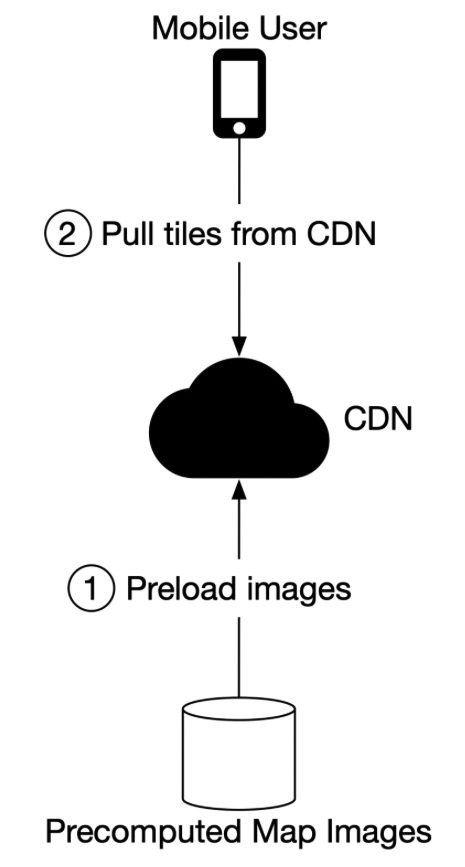
- Option 2
- “Another option is to serve a pre-generated set of map tiles at each zoom level. ”
- “The map tiles are static, with each tile covering a fixed rectangular grid using a subdivision scheme like geohashing. ”
- “Each tile is therefore represented by its geohash.”
- “When a client needs a map tile, it first determines the map tile collection to use based on its zoom level. It then computes the map tile URL by converting its location to the geohash at the appropriate zoom level.”
- Option 1
Deep Dive
- Routing tiles
- original dataset contains a large number of roads and associated metadata such as names, county, longitude, and latitude.
- “This data is not organized as graph data structures and is not usable by most routing algorithms. ”
- “We run a periodic offline processing pipeline, called routing tile processing service, to transform this dataset into the routing tiles we introduced. The service runs periodically to capture new changes to the road data.”
- “The output of the routing tile processing service is routing tiles. ”
- “Each tile contains a list of graph nodes and edges representing the intersections and roads within the area covered by the tile. It also contains references to other tiles its roads connect to.”
- “These tiles together form an interconnected network of roads that the routing algorithms can consume incrementally.”
- “The more efficient way to store these tiles is in object storage like S3 and cache it aggressively on the routing service that uses those tiles.
- There are many high-performance software packages we could use to serialize the adjacency lists to a binary file.
- We could organize these tiles by their geohashes in the object storage. This provides a fast lookup mechanism to locate a tile by lat/lng pair.”
- original dataset contains a large number of roads and associated metadata such as names, county, longitude, and latitude.
- Geocoding database
- “We can use a key-value database such as Redis for fast reads, since we have frequent reads and infrequent writes.
- We use it to convert an origin or destination to a lat/lng pair before passing it to the route planner service.”
- “Precomputed images of the world map”
- “When a device asks for a map of a particular area, we need to get nearby roads and compute an image that represents that area with all the roads and related details.
- These computations would be heavy and redundant, so it could be helpful to compute them once and then cache the images.
- We precompute images at different zoom levels and store them on a CDN, which is backed by cloud storage such as Amazon S3. ”
- Location service
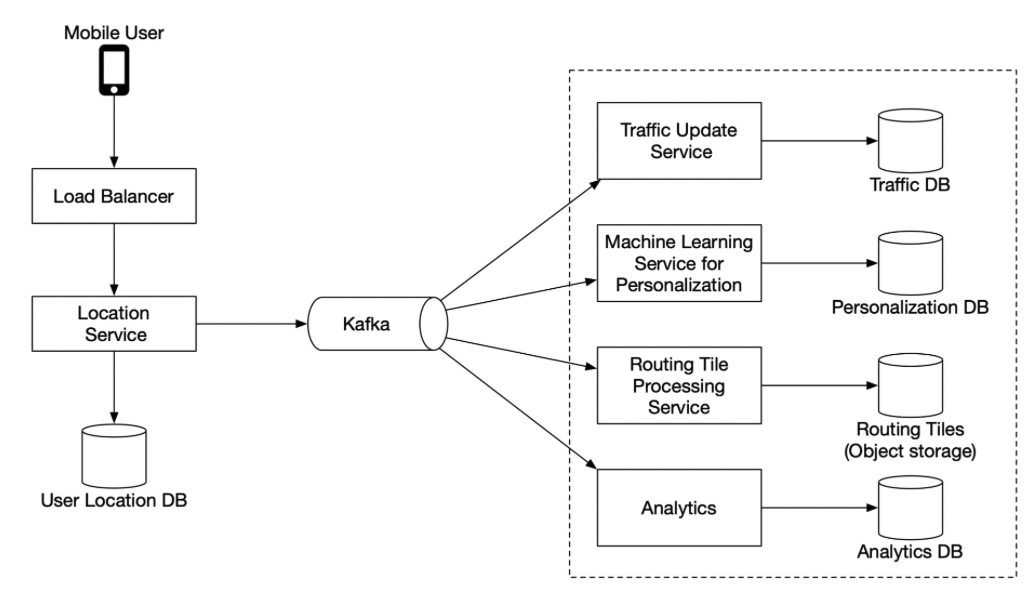
- database choice: cassandra
- “Given the fact we have 1 million location updates every second, we need to have a database that supports fast writes. A No-SQL key-value database or column-oriented database would be a good choice here. ”
- “In addition, a user’s location is continuously changing and becomes stale as soon as a new update arrives. Therefore, we can prioritize availability over consistency. ”
- “How do we use the user location data”
- “We use the data to detect new and recently closed roads. We use it as one of the inputs to improve the accuracy of our map over time. It is also an input for live traffic data.
- To support these use cases, in addition to writing current user locations in our database, we log this information into a message queue, such as Kafka. ”
- database choice: cassandra
- Rendering map
- Possible Optimization: use vectors
- “one potential improvement is to change the design from sending the images over the network, to sending the vector information (paths and polygons) instead. The client draws the paths and polygons from the vector information.”
- “One obvious advantage of vector tiles is that vector data compresses much better than images do. The bandwidth saving is substantial.
- A less obvious benefit is that vector tiles provide a much better zooming experience. With rasterized images, as the client zooms in from one level to another, everything gets stretched and looks pixelated. The visual effect is pretty jarring. With vectorized images, the client can scale each element appropriately, providing a much smoother zooming experience.”
- Possible Optimization: use vectors
- Navigation service
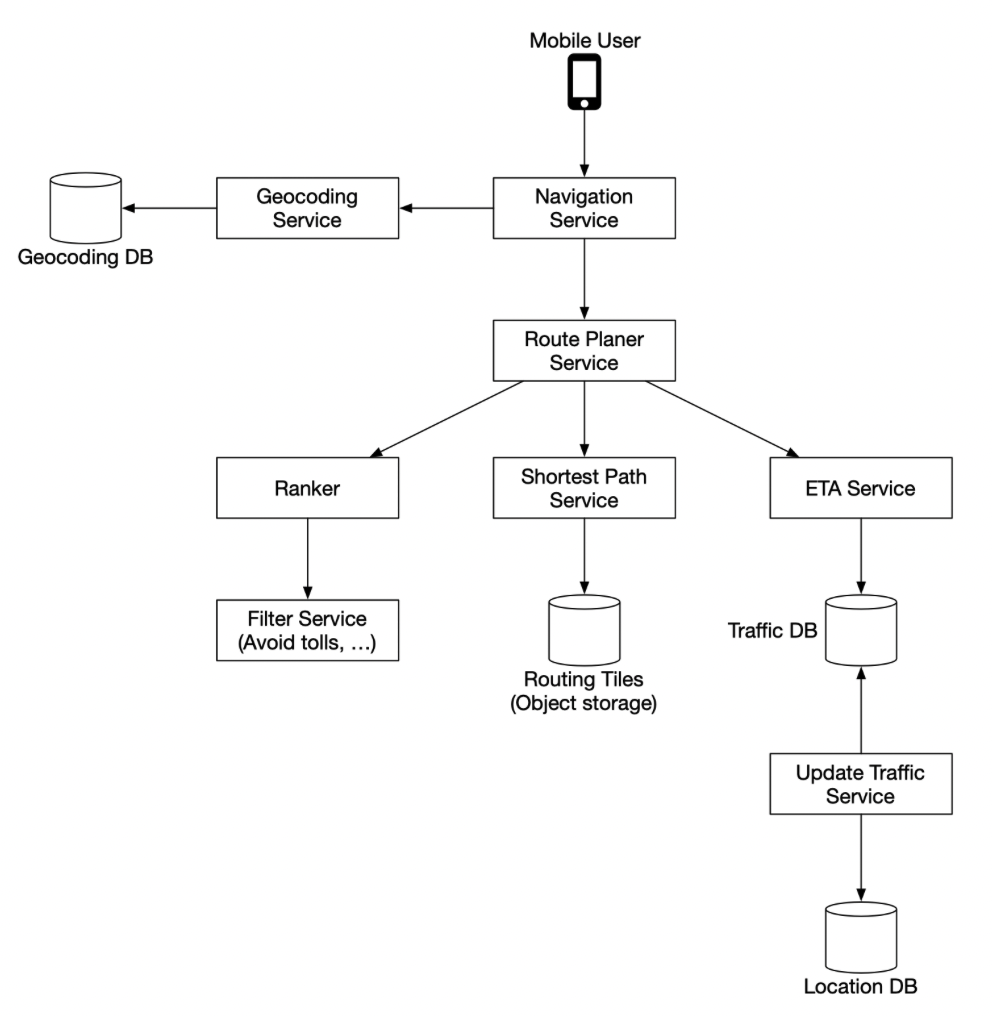
- Route planner service
- “This service computes a suggested route that is optimized for travel time according to current traffic and road conditions. ” - Shortest-path service
- use variation of a* to search routes
- “The shortest-path service receives the origin and the destination in lat/lng pairs and returns the top-k shortest paths without considering traffic or current conditions. ”
- “This computation only depends on the structure of the roads.”
- “Here, caching the routes could be beneficial because the graph rarely changes.” - ETA service
- “ETA service uses machine learning to predict the ETAs based on the current traffic and historical data.” - Ranker service
- “Finally, after the route planner obtains the ETA predictions, it passes this info to the ranker to apply possible filters as defined by the user. Some example filters include options to avoid toll roads or to avoid freeways. The ranker service then ranks the possible routes from fastest to slowest and returns top-k results to the navigation service.” - Updater services
- “These services tap into the Kafka location update stream and asynchronously update some of the important databases to keep them up-to-date.”
- “The traffic database and the routing tiles are some examples.”
- “The routing tile processing service is responsible for transforming the road dataset with newly found roads and road closures into a continuously updated set of routing tiles. This helps the shortest path service to be more accurate.”
- “The traffic update service extracts traffic conditions from the streams of location updates sent by the active users. This insight is fed into the live traffic database. This enables the ETA service to provide more accurate estimates.”
- “Improvement: adaptive ETA and rerouting”
- “needs to keep track of all the active navigating users and update them on ETA continuously, whenever traffic conditions change.”
- how to track actively navigating users / How do we store the data, so that we can efficiently locate the users affected by traffic changes among millions of navigation routes?
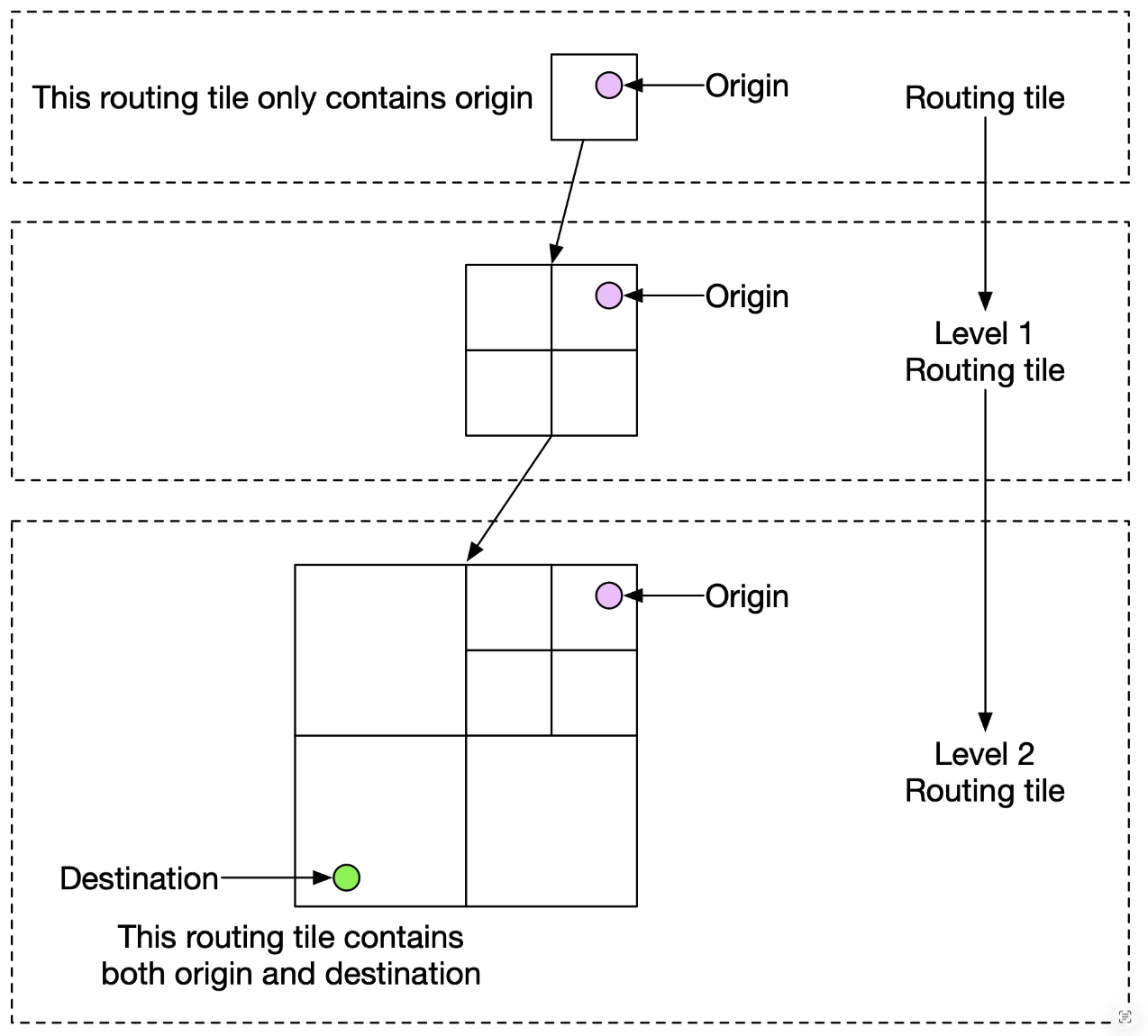
- “For each actively navigating user, we keep the current routing tile, the routing tile at the next resolution level that contains it, and the routing tile that contains the intermediate tile, the last routing tile of the list need to include the destination.”
- “To find out if a user is affected by the traffic change, we need only check if a routing tile is inside the last routing tile of a row in the database. If not, the user is not impacted. If it is, the user is affected. By doing this, we can quickly filter out many users.”
- “This approach doesn’t specify what happens when traffic clears. ”
- “One idea is to keep track of all possible routes for a navigating user, recalculate the ETAs regularly and notify the user if a new route with a shorter ETA is found.”
Final Design
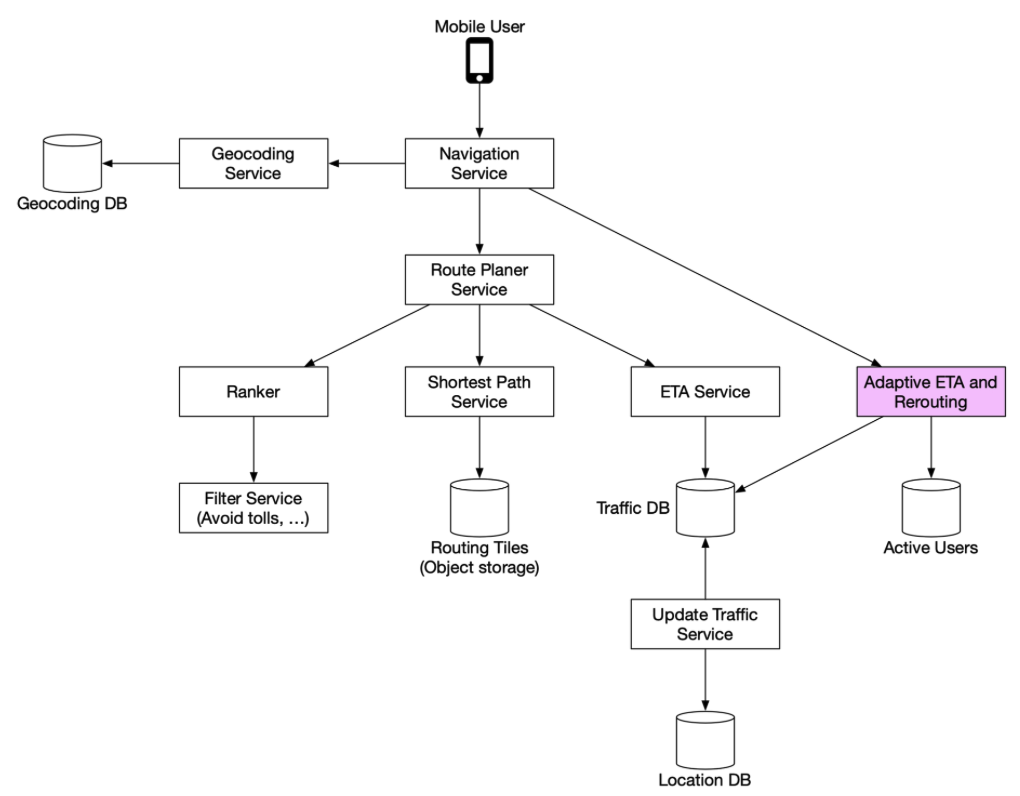
Distributed Message Queue
backgrounds
“Message queues vs event streaming”
- event streaming: long data retention, “repeated consumption of messages”
Basic requirements
- functional
- “Producers send messages to a message queue.
- Consumers consume messages from a message queue.
- Messages can be consumed repeatedly or only once.
- Historical data can be truncated.
- Message size is in the kilobyte range.
- Ability to deliver the messages to consumers in the order they were added to the queue.
- Data delivery semantics (at-least-once, at-most-once, or exactly-once) can be configured by users.”
- non-functional
- “High throughput or low latency, configurable based on use cases.
- Scalable. The system should be distributed in nature. It should be able to support a sudden surge in message volume.
- Persistent and durable. Data should be persisted on disk and replicated across multiple nodes.”
High-Level Design
- Basic Message Queue Concept
- “Producer sends messages to a message queue.
- Consumer subscribes to a queue and consumes the subscribed messages.
- Message queue is a service in the middle that decouples the producers from the consumers, allowing each of them to operate and scale independently.
- Both producer and consumer are clients in the client/server model, while the message queue is the server.
- The clients and servers communicate over the network.
- Messaging Model
- Point-to-point
- “In a point-to-point model, a message is sent to a queue and consumed by one and only one consumer.”
- “There can be multiple consumers waiting to consume messages in the queue, but each message can only be consumed by a single consumer.”
- “Once the consumer acknowledges that a message is consumed, it is removed from the queue. There is no data retention in the point-to-point model.”
- Publish-subscribe
- New concept: topic
- “Topics are the categories used to organize messages. Each topic has a name that is unique across the entire message queue service. Messages are sent to and read from a specific topic.”
- “In the publish-subscribe model, a message is sent to a topic and received by the consumers subscribing to this topic.”
- Point-to-point
- “Topics, partitions, and brokers”
- partition (sharding):
- “divide a topic into partitions and deliver messages evenly across partitions. ”
- “Think of a partition as a small subset of the messages for a topic.”
- “Partitions are evenly distributed across the servers in the message queue cluster.”
- broker:
- “These servers that hold partitions are called brokers.”
- offset
- “The position of a message in the partition is called an offset.”
- whole working process
- “When a message is sent by a producer, it is actually sent to one of the partitions for the topic. ”
- “Each message has an optional message key (for example, a user’s ID), and all messages for the same message key are sent to the same partition.”
- “If the message key is absent, the message is randomly sent to one of the partitions.”
- Consumer Group
- “When a consumer subscribes to a topic, it pulls data from one or more of these partitions. When there are multiple consumers subscribing to a topic, each consumer is responsible for a subset of the partitions for the topic. ”
- “The consumers form a consumer group for a topic.”
- partition (sharding):