Introduction
This is a note for parallel programming, including OpenMP, Pthread, and MPI.
Table of Contents
- Introduction
- Table of Contents
- Loop Transformation
- Cache Performance
- Memory Systems
- Amdahl’s Law
- Profiling
- Intro to Parallelism
- Parallel Programming Models
- Creating a Parallel Program
- OpenMP Programming
- Parallel Programming Issuses
- Inherent vs. Artifactual Communication
- Syncronization
- Pthread
- Parallel Programming for Linked Data Structures
- Memory Consistency
- Lock Free Data Structures
- Programming for Clusters
- Programming for Accelerators w/ Directives
Loop Transformation
Performancs Primer
Performance = Executed Instructions * CPI * (1 / CPU frequency)
- Performance = wall clock time, time consumed by the program
- CPI = average cycles per instruction
- CPI can be less than due to superscalar
- Assuming a fixed hardware system
- Reducing the number of program instructions
- Reducing the average CPI (making the instructions execute more efficiently and/or expose more ILP to the CPU)
Data Dependency
- Instruction A comes before instruction B in program order
- True Dependence
- Input of instruction B is produced as an output of instruction A
- Anti Dependence
- Output of instruction B is an input of instruction A
- Output Dependence
- Output of instruction B is an output of instruction A
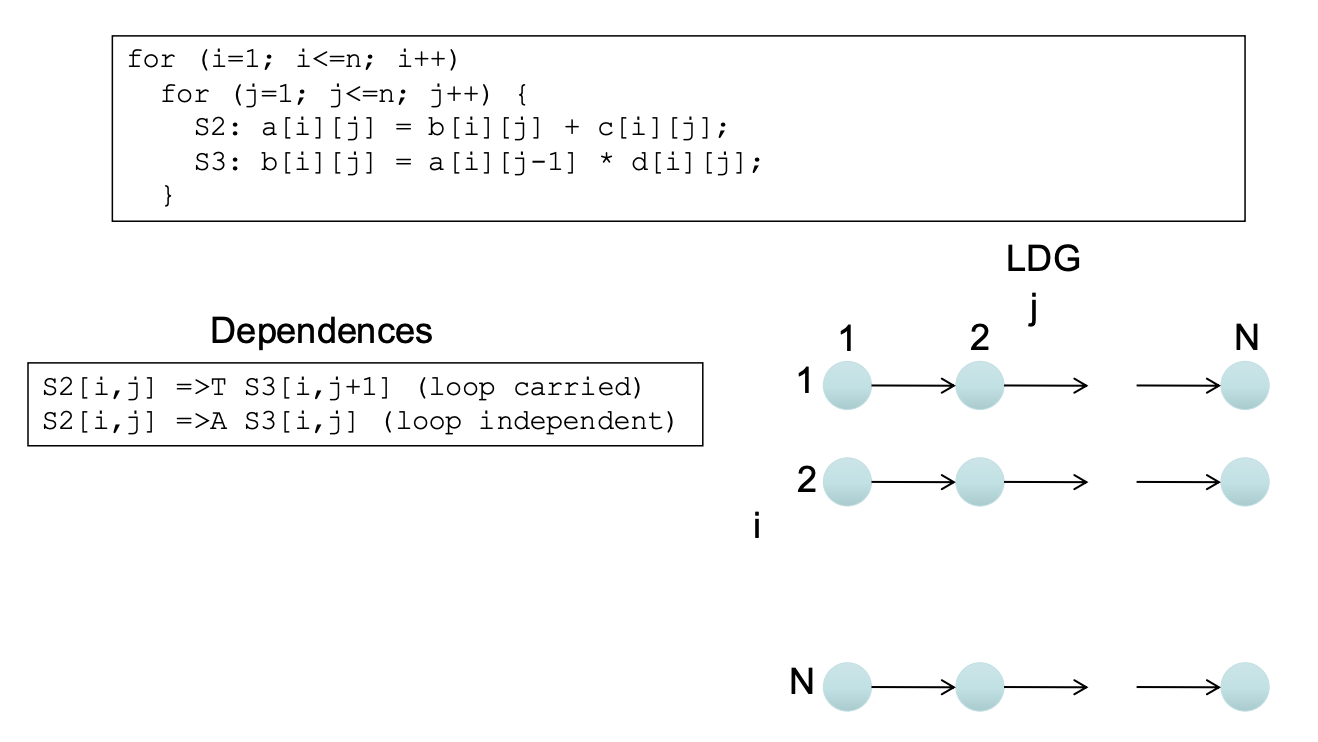
Loop-independent and Loop-carried Dependence
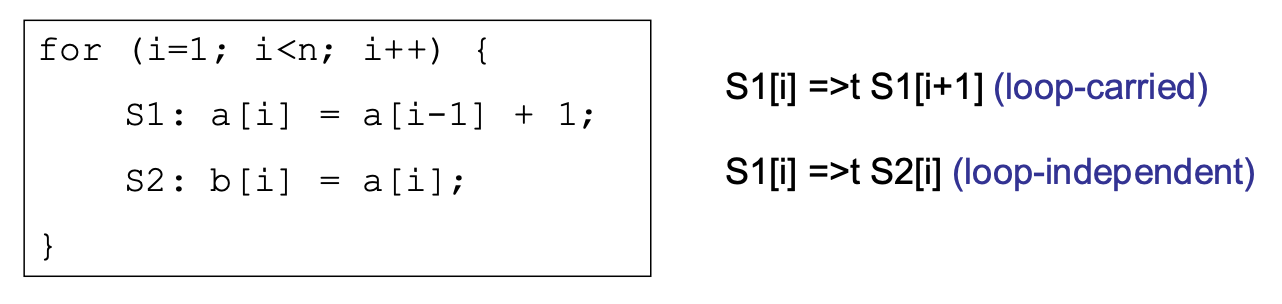
- Loop-independent dependence
- Dependence exists within an iteration
- If loop is removed, the dependence still exists
- Loop-carried dependence
- Dependence exists across iterations
- If loop is removed, the dependence no longer exists
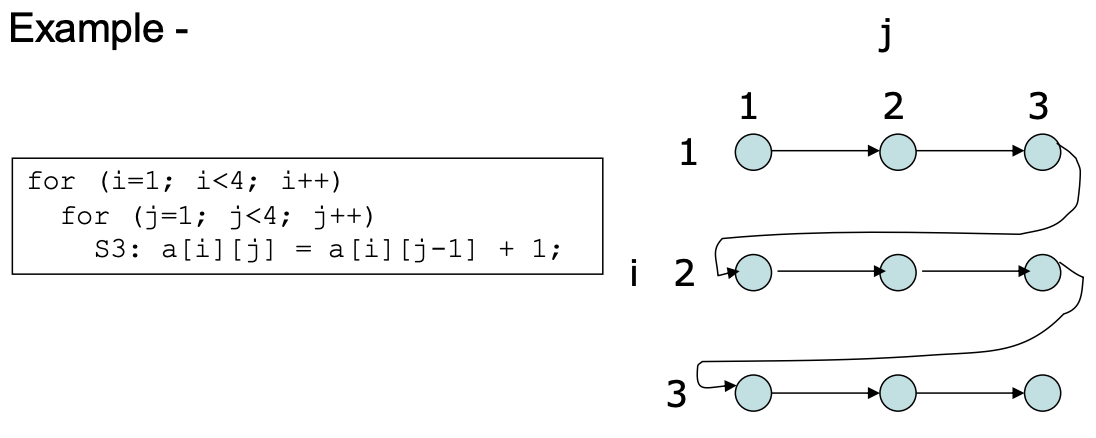
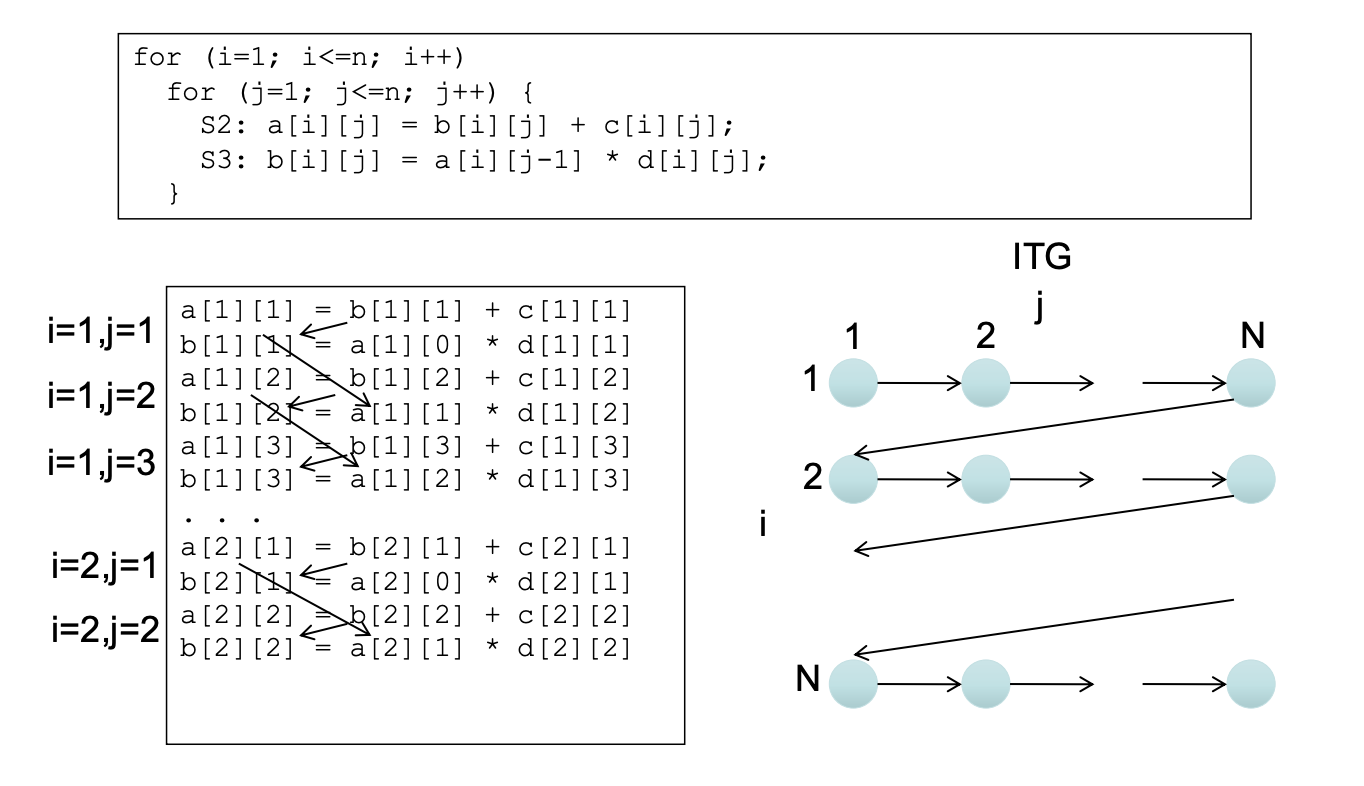
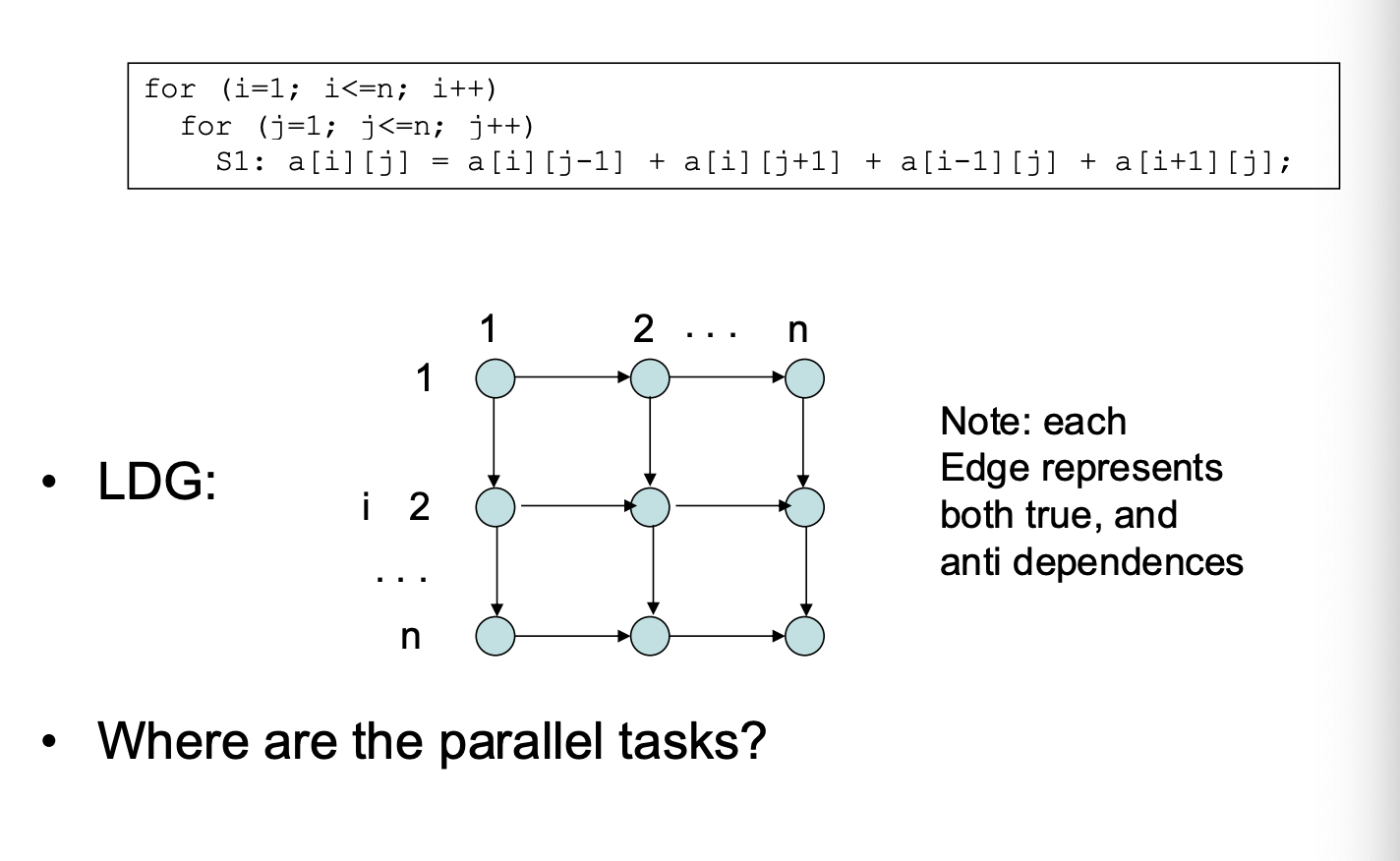
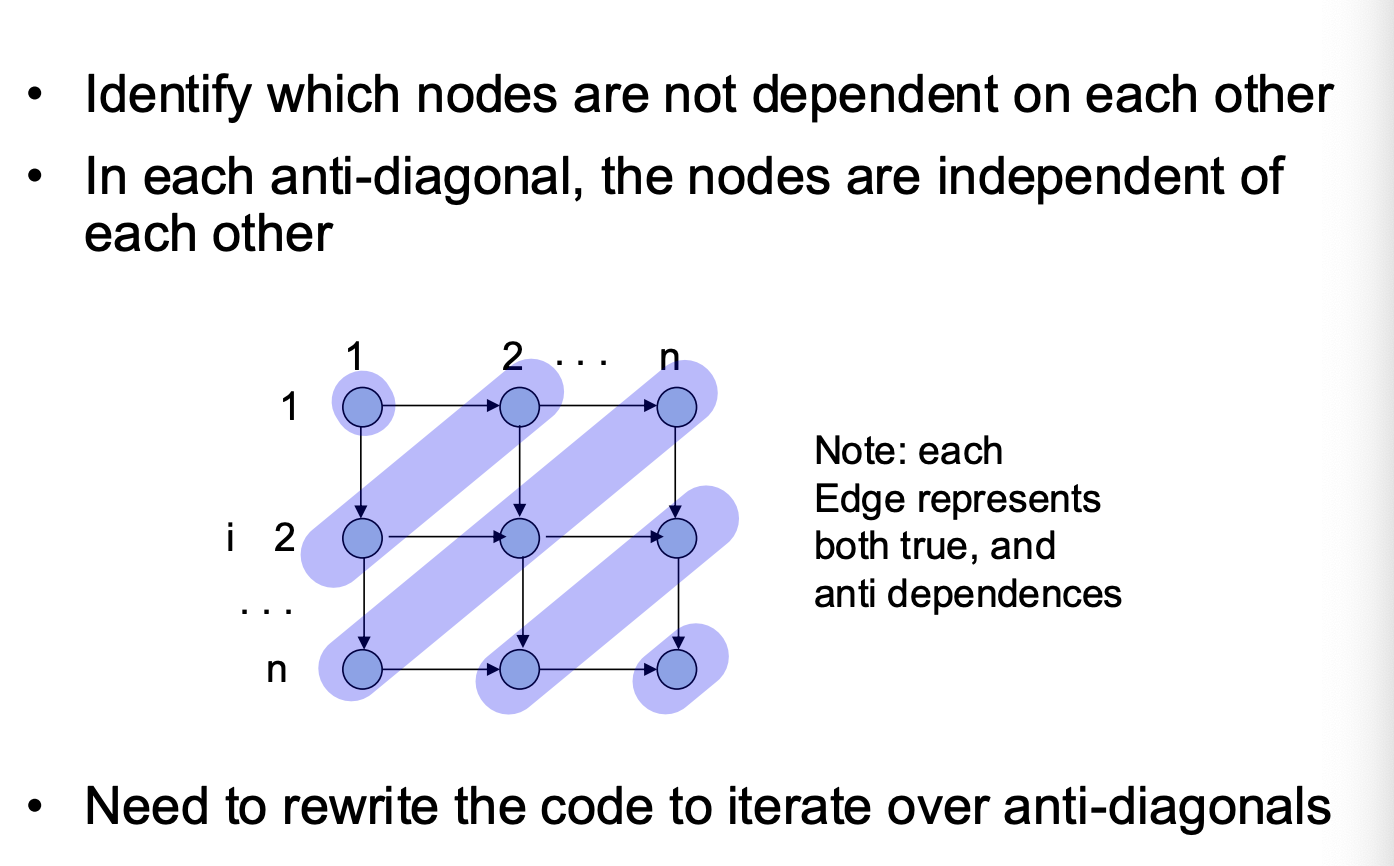
ITG and LDG
Iteration-space Traversal Graph (ITG)
- ITG shows graphically the order of traversal in the iteration space
(happens-before relationship)
- Node = a point in the iteration space
- Directed Edge = the next point that will be encountered after the current point is traversed
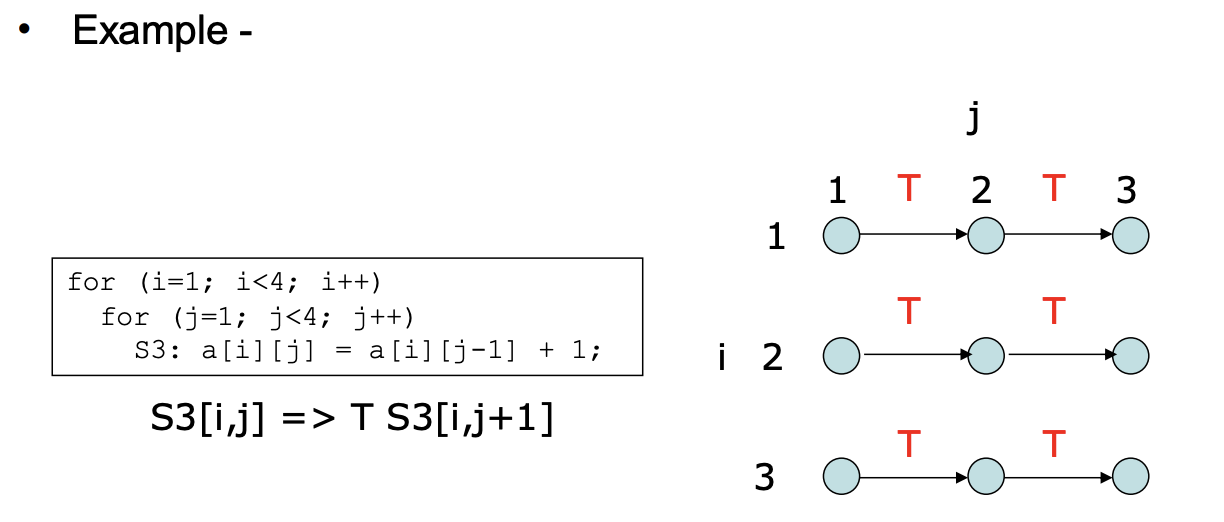
Loop-carried Dependence Graph (LDG)
- LDG shows the true/anti/output dependence relationship graphically
- Node = a point in the iteration space
- Directed Edge = the dependence


Loop Optimization
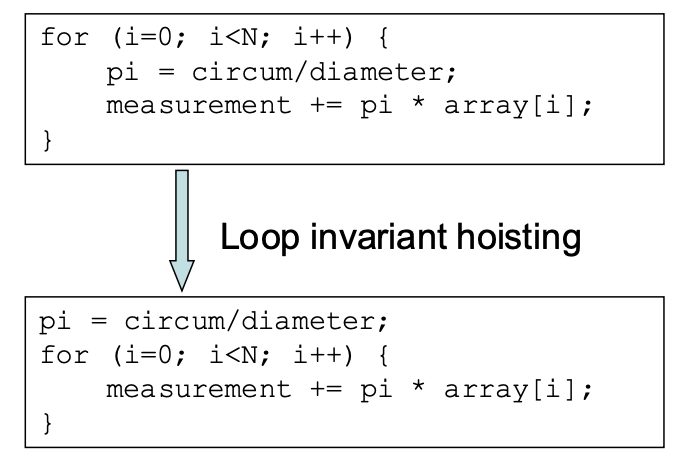
Loop Invariant Hoisting
Loop Unrolling
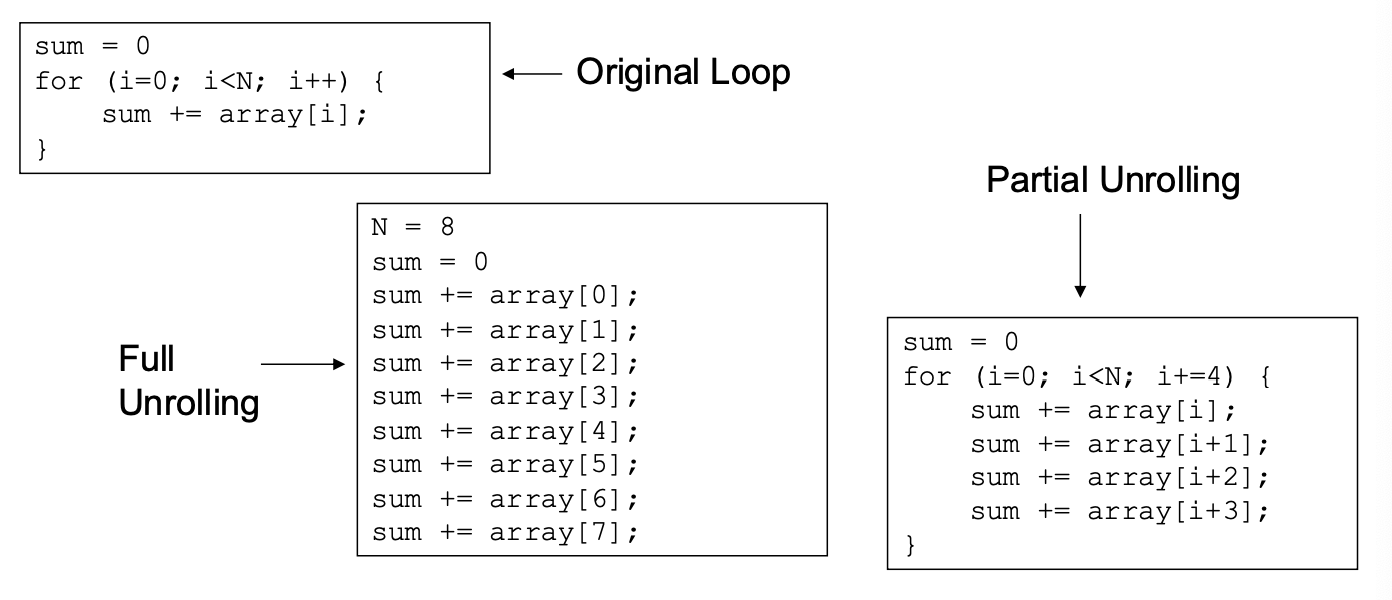

Benefits
- Expose additional ILP (instruction level parallelism)
- Reduce instruction count (fewer loop management instructions) Drawbacks
- Potentially use more registers
- May cause register spilling
- Save registers to memory with stores
- Restore registers from memory later with loads
- May cause register spilling
- Increases code size => use more of the instruction cache
Loop Fusion
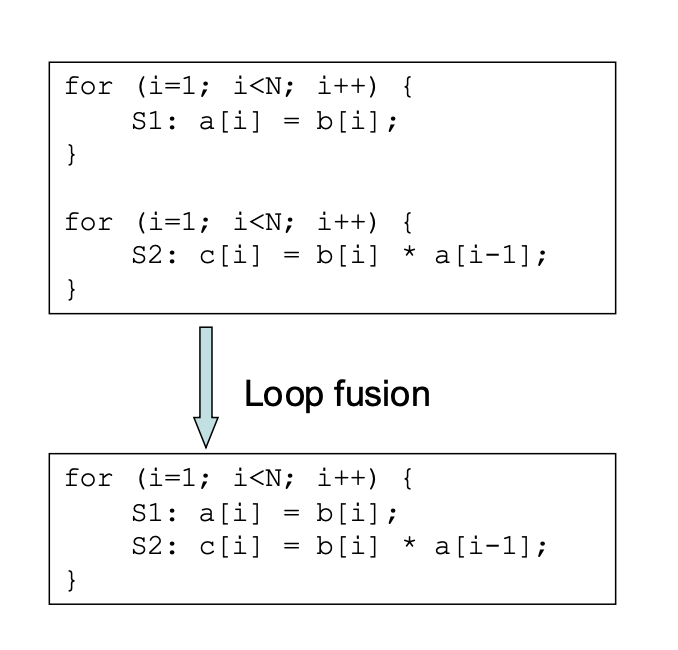
Loop Fission
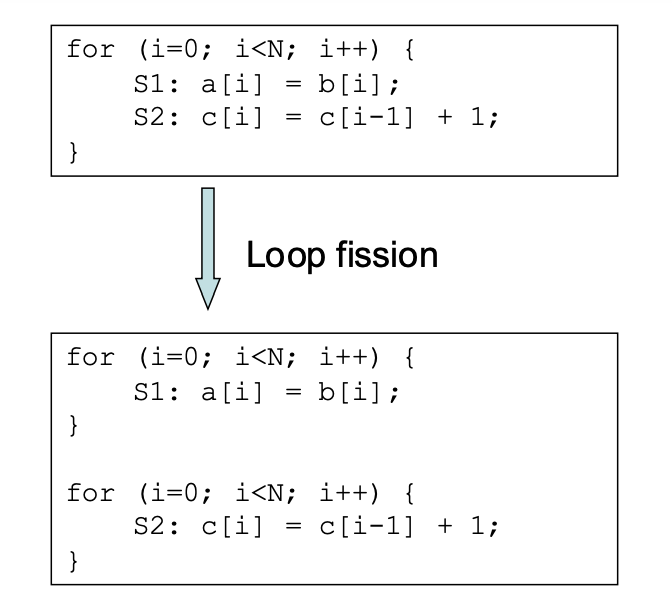
Loop Peeling
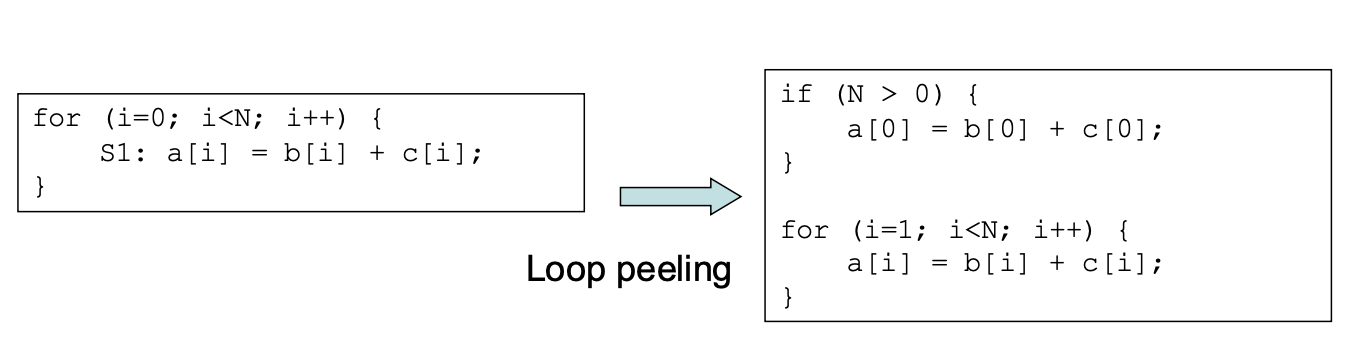
Loop Unswitching
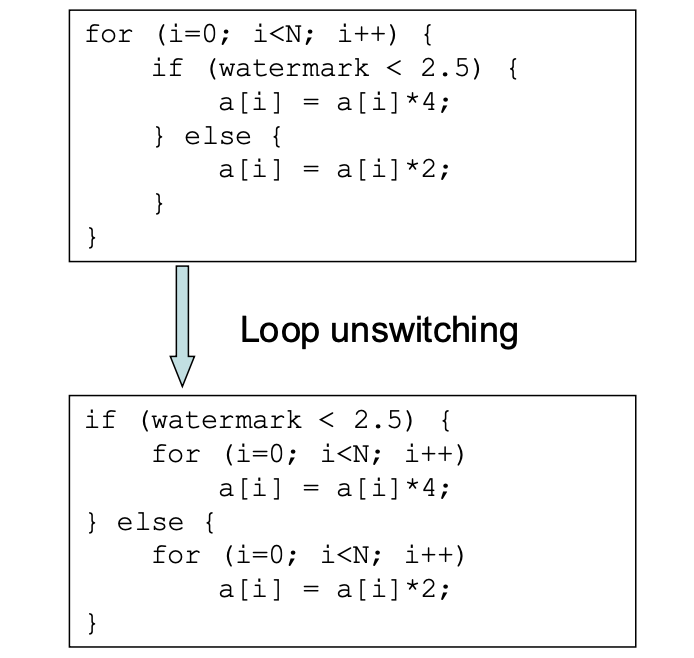
Loop Interchange
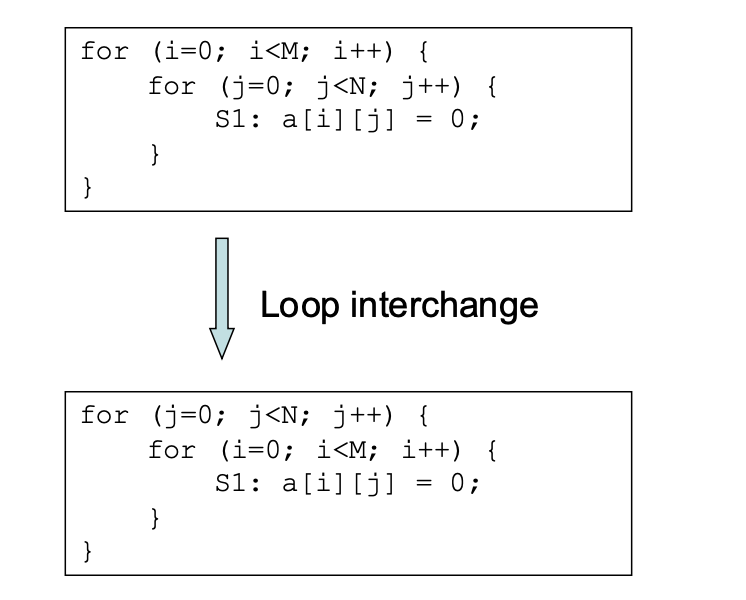
- Loop Interchange is safe if outermost loop does not carry any data dependence from one statement instance executed for i and j to another statement instance executed for i’ and j’ where (i < i’ and j > j’) OR (i > i’ and j < j’)
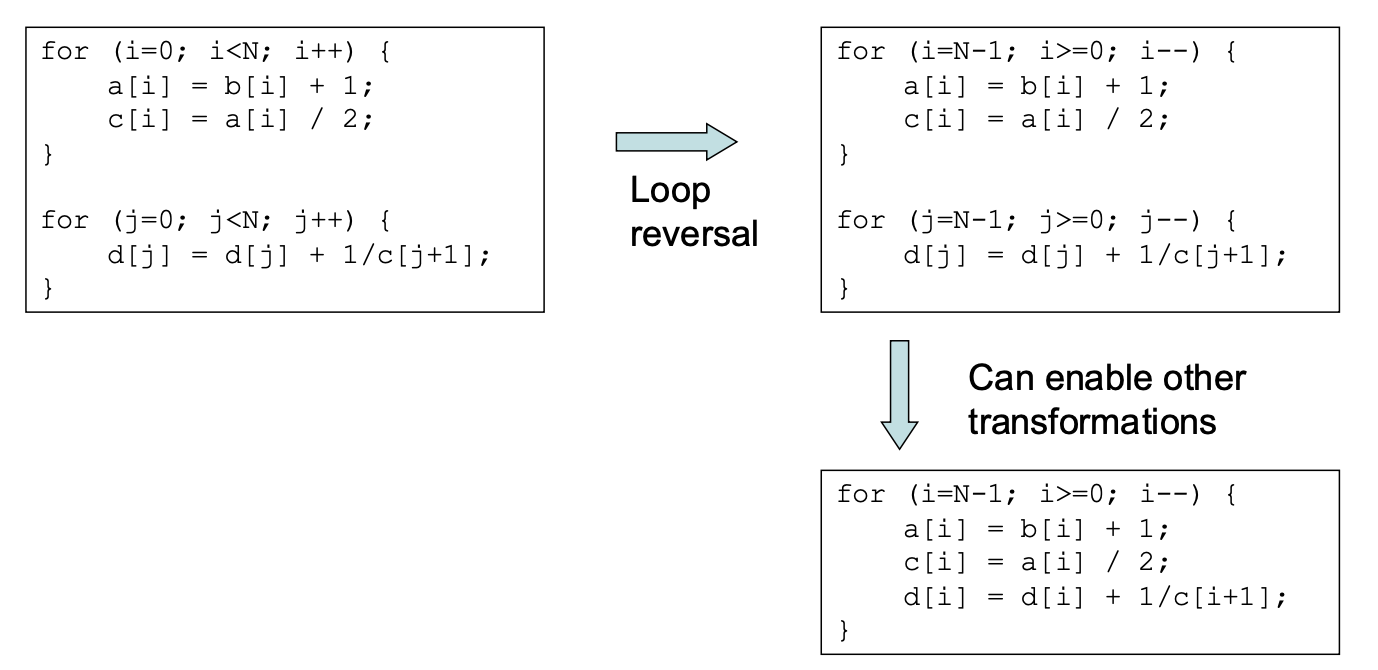
Loop reversal
Loop Unroll and Jam
- Partially unroll one or more loops higher in the loop nest than the innermost loop, and then fuse (jam) resulting loops back together

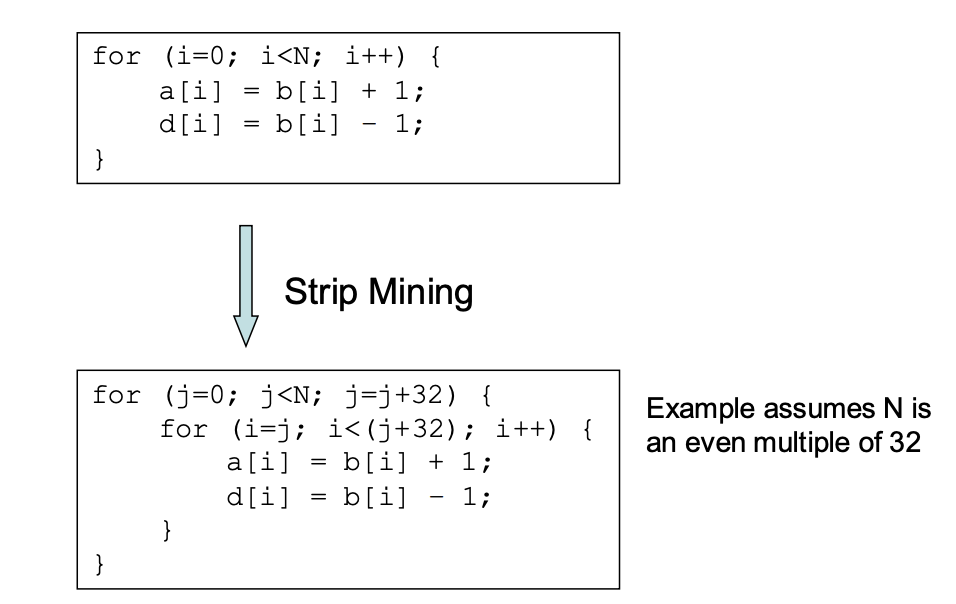
Loop Strip Mining
- Transforms singly-nested loop into doubly-nested loop
- Outer loop steps through index in blocks of some size
- Inner loop iterates through each block
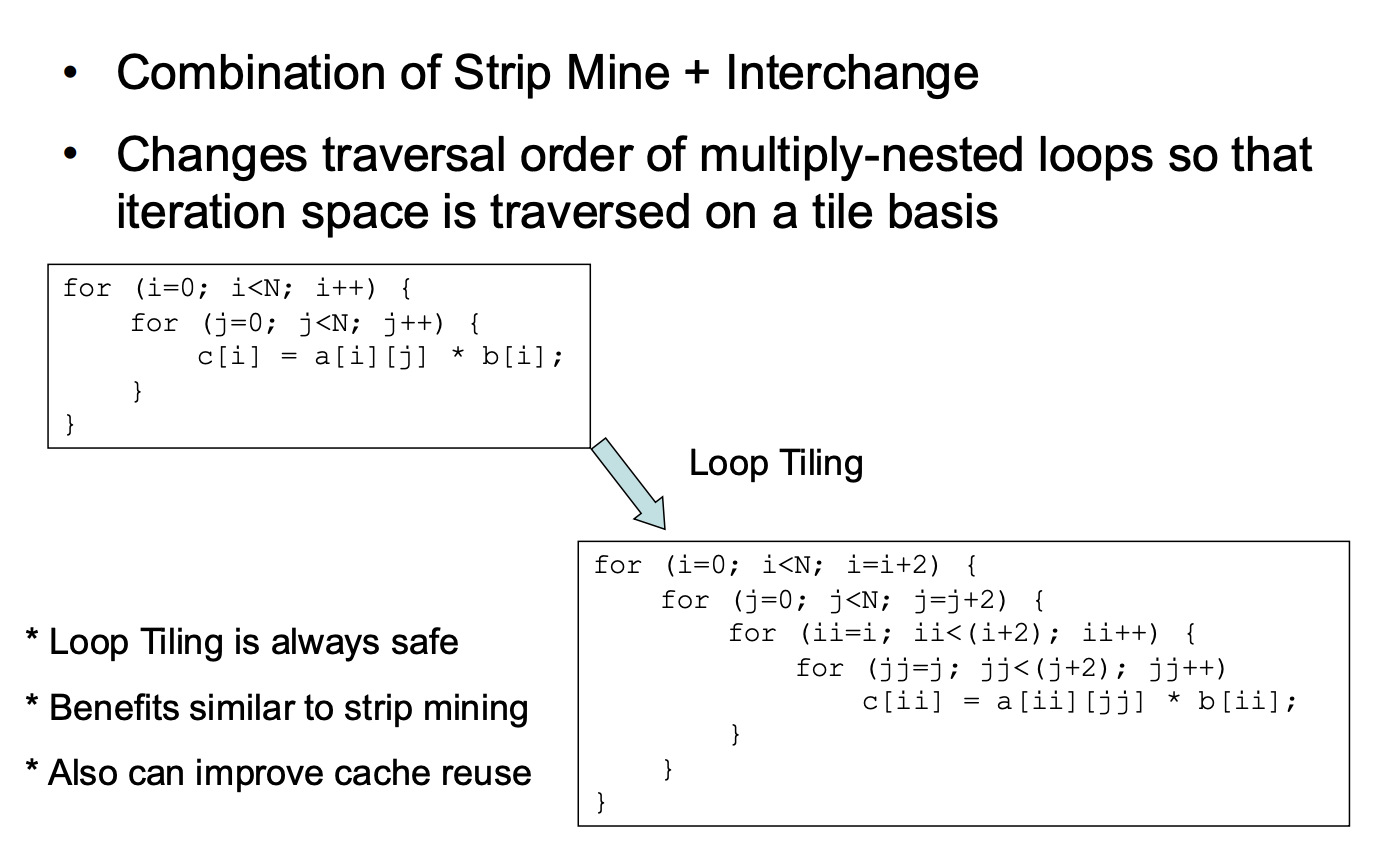
Loop Tiling
Cache Performance
- Cache Performance = Hit Time * Hit Rate + Miss Time * Miss Rate
Cache Access Patterns
- Data set size
- As data set grows larger than a cache level, performance drops
- Stride
- Affects spatial locality provided by cache blocks
- stride is less than size of a cache line: Initial access may cause cache miss, sequential accesses are fast
- stride is greater than size of a cache line: Sequential accesses are slow
Latency vs. Bandwidth
- Latency: Hit time for a cache level or memory
- Pointer Chasing: Stresses the latency of each access, Only one memory access in flight at a given time
- Bandwidth: Rate
- Bandwidth gets smaller at lower levels of memory hierarchy
- Some code is throughput sensitive, not latency sensitive
Matrix Multiplication Example
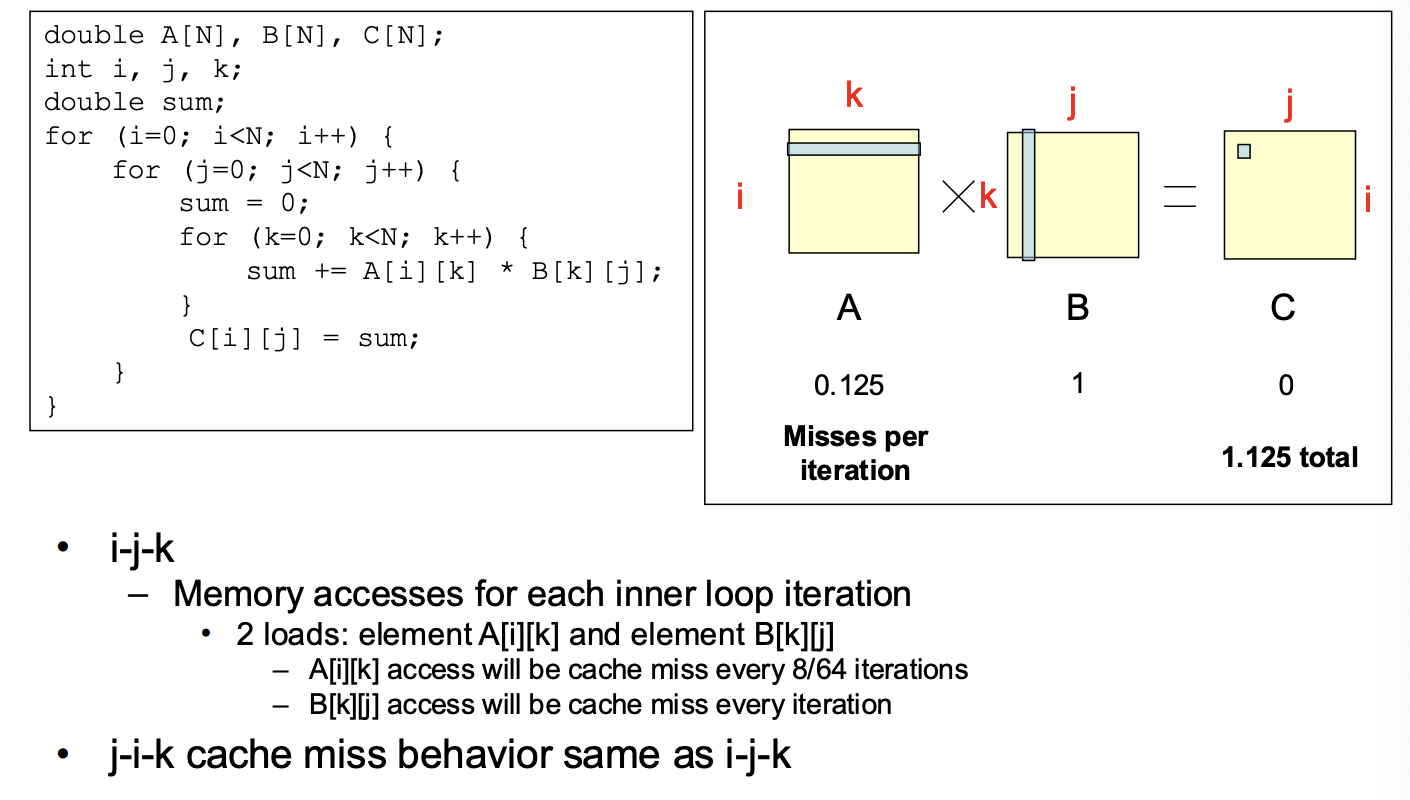
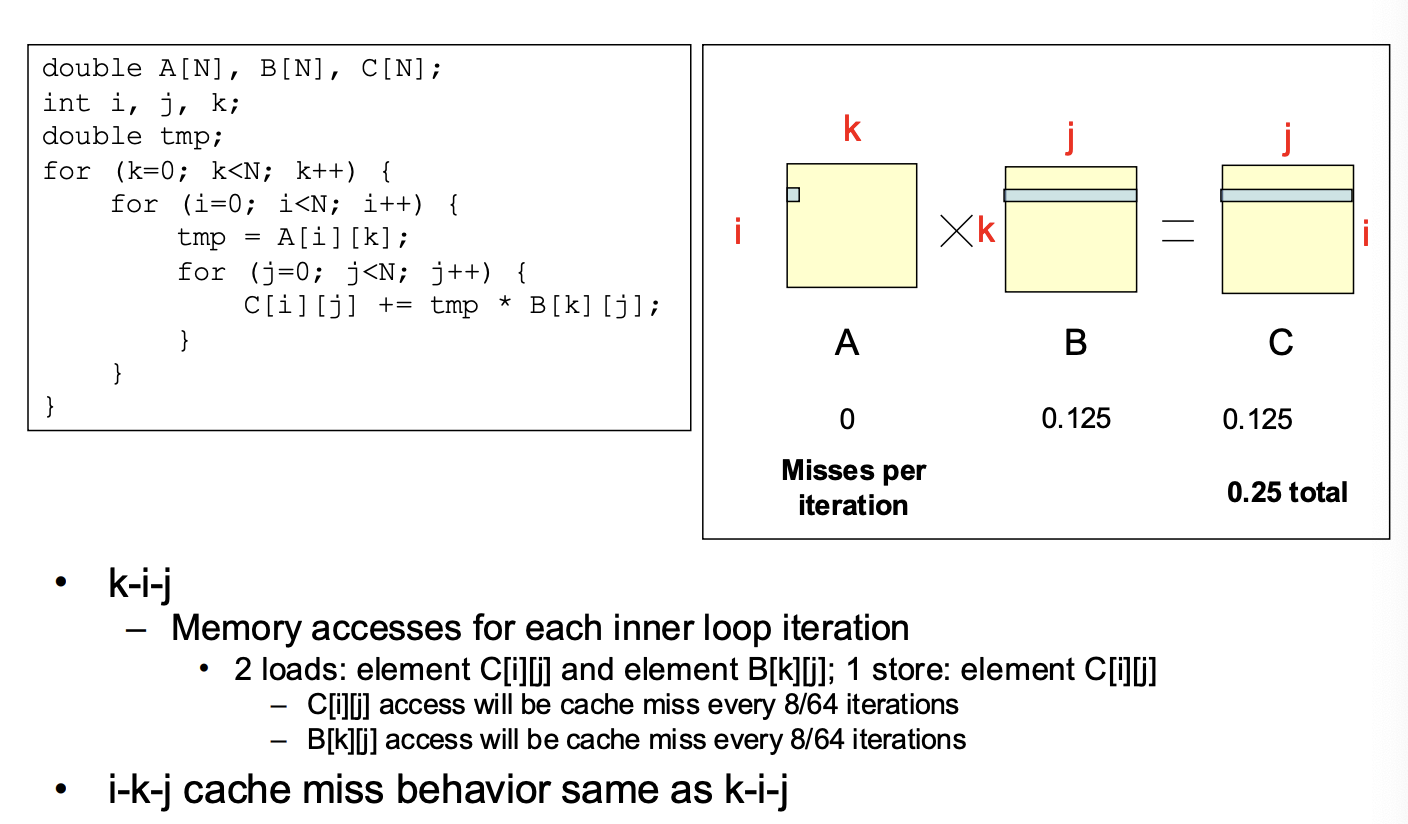
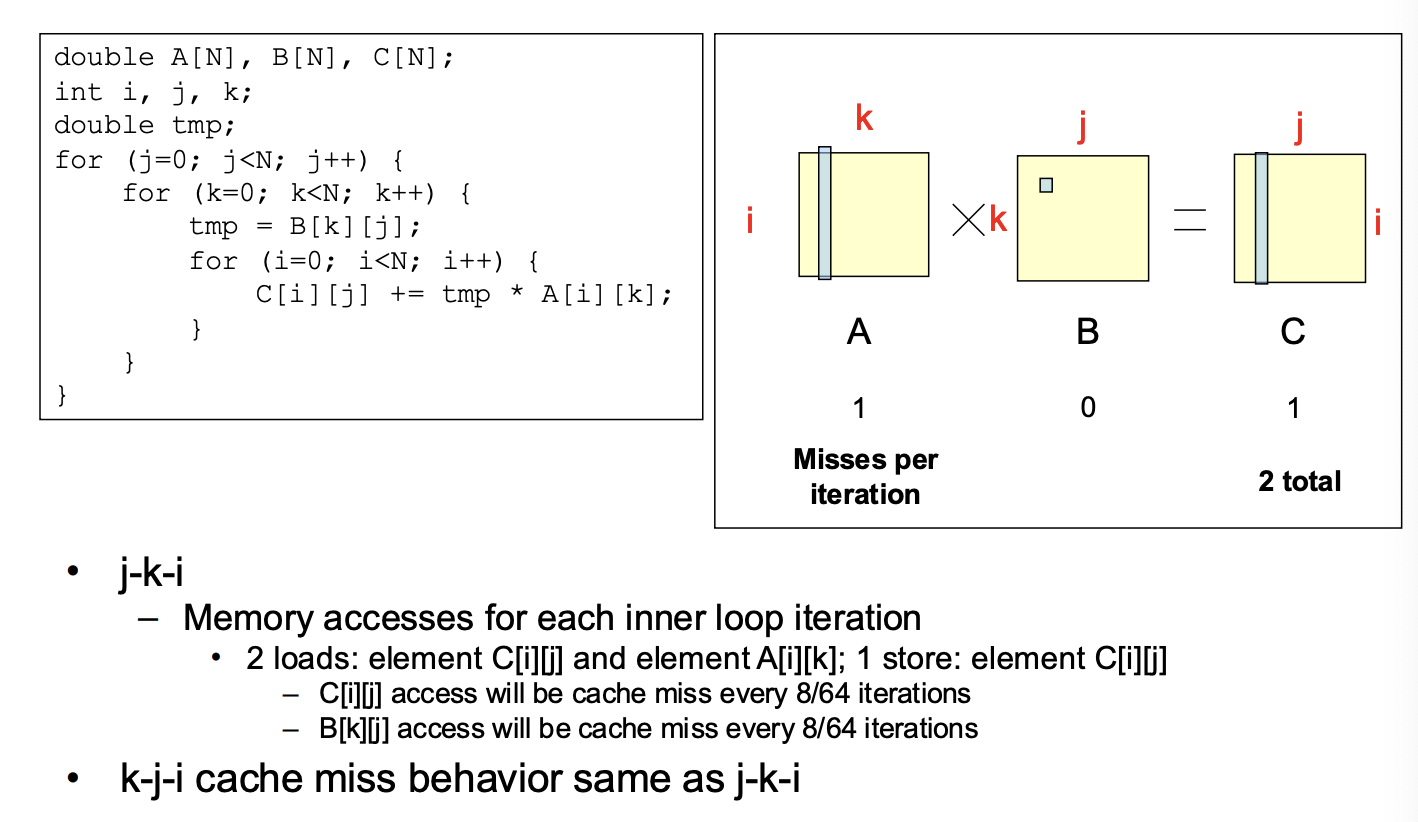
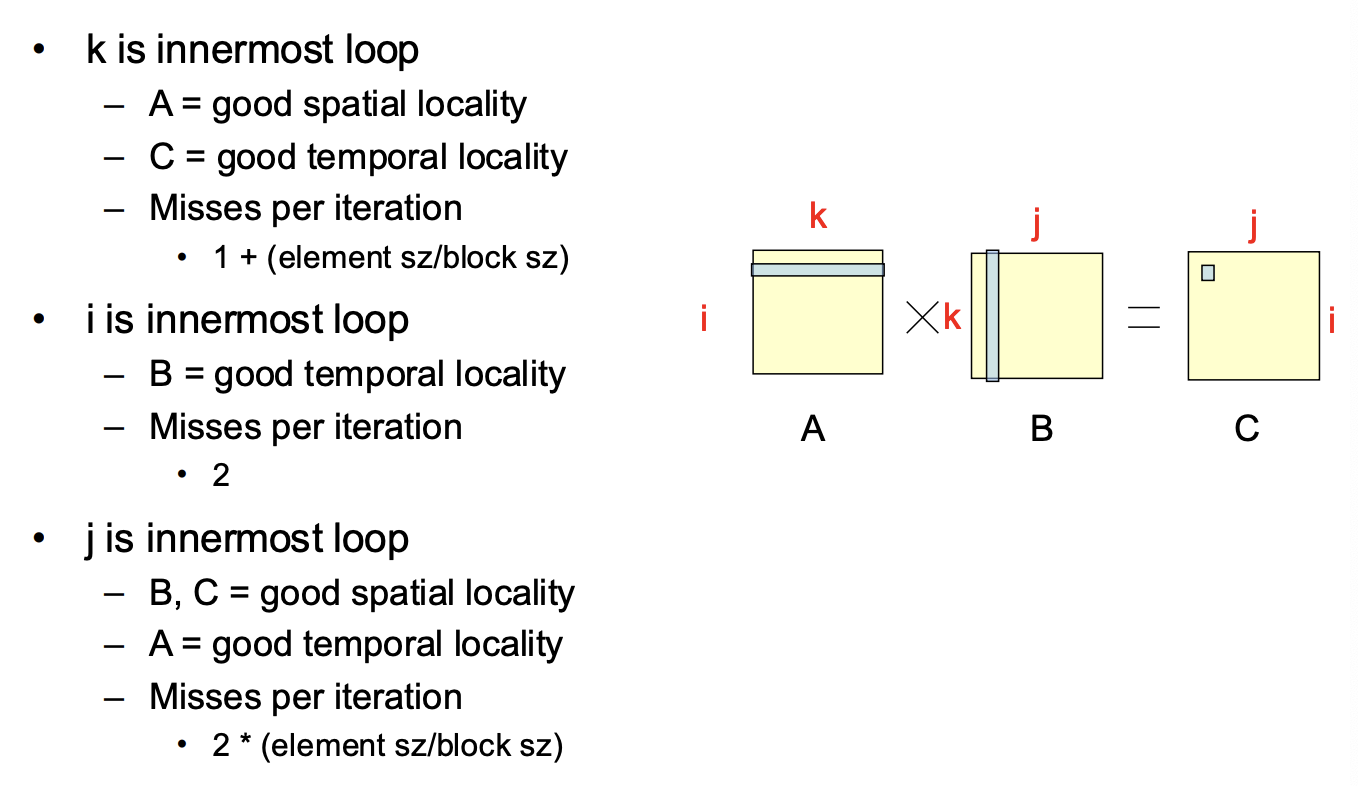
Memory Systems
DRAM Performance


Amdahl’s Law
we’ll skip this part. Look up amdahl’s law and gustafson’s law for more information.
Profiling
See what takes time in a large program
Two main types of profiling
Flat Profile
Only computes average time in a particular function
Does not include other (useful) info, like callees
Call-graph Profile
Computes call times
- Reports frequency of function calls
- Gives a call graph
- Which functions are called by which other functions
- Which functions call which other functions
Profiler Data Collection
- Statistical
- Take samples of system state:
- like every 2ms, check the system state
- Instrumentation
- Add additional instructions at specified program points:
- Can do this at compile time or run time (run time is expensive)
- Can instrument either manually or automatically
- Like conditional breakpoints
- Add additional instructions at specified program points:
Hardware Performance Counters
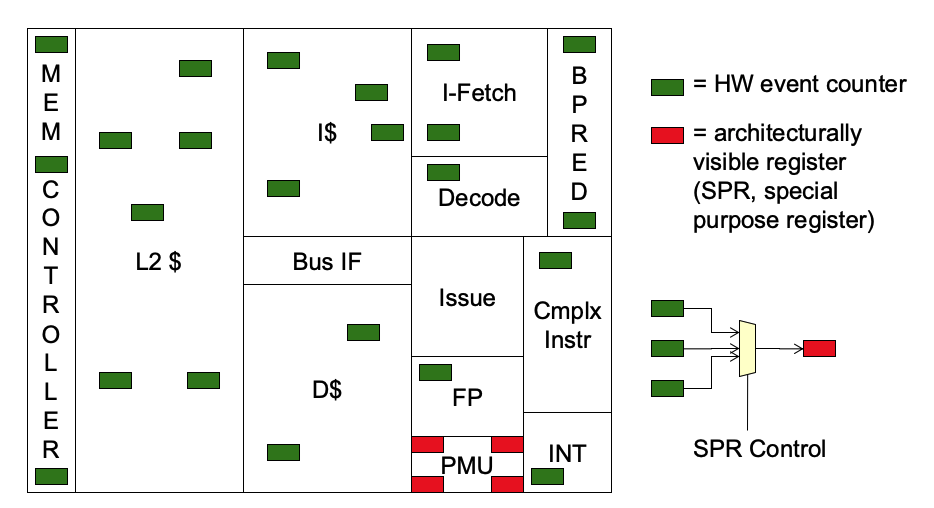
- A dedicated set of special purpose registers (SPRs)
- Perf counters contained in a hardware unit
- Called Performance Monitoring Unit (PMU)
- May be multiple PMUs on a chip
- Processor core PMU, Cache/Memory PMU
- Counters configurable to hold counts of HW activities
- Architecture defines HW events that can be counted
- Counters can be read by software for analysis
Events Categories
Processor pipeline events
- Instructions fetched, executed, committed
- Elapsed cycles
- Branch mispredictions
- Execution of different instruction types
- Pipeline hazards and delays
- Might allow construction of a CPI (cycles per instruction) stack
Cache events
- Cache accesses, hits, misses
- Cache snoops, invalidations
Memory events
- Memory accesses
- Memory read/write bytes
- Memory bandwidth
Performance Counter Events
Architecture will define events for collection
- Typically described in an architecture or perf analysis guide
- SW tools (e.g. profilers) provide an easier interface
- To interact with the HW perf counters
- To turn on PMUs to enable counting
- To select events to count
- To extract counts from the perf counters
Performance Counter Uses
- Enable low-level performance analysis & tuning
- By application developers
- System software
- Enable performance validation of the processor design
- Run targeted code sequences on a processor
- Verify that measured performance counter values match expectation
Intro to Parallelism
Types of Parallelism
Sources of parallelism in high-performance CPUs
- CPU Pipelining
- Different pipe stages work on different instructions simultaneously
- Data Parallelism
- SIMD - Single Instruction, Multiple Data
- Superscalar
- Multiple instructions fetched, decoded, issued, executed, committed per clock cycle
- HW multi-threading (e.g. SMT - simultaneous multithreading)
- Multiple threads run simultaneously on one CPU core
- Multicore
- Multiple processor cores execute different threads/processes
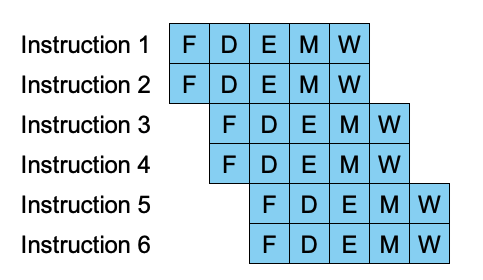
Processor Pipelining
Fits well with RISC architectures
- N-fold improvement in instruction throughput compared to simple processor
- N = # of stages
- Ideally pipelined processor will complete 1 instruction per cycle
- Current processors use many pipeline stages
- A few tens of stages
- Improves parallelism and increases clock rate
- But there are drawbacks too…
Pipeline hazards
- Control hazards
- Branches, jumps, etc.
- Can be resolved with branch prediction
- Data hazards
- Data dependencies between instructions
- Can be resolved with forwarding, stalling, etc.
Limitations on pipelining
- Processor frequency (cycle time) is bound by slowest stage
- Deeper pipelines result in worse penalties for hazards
- More cycles required to process for long-latency events
- More cycles to refill processor pipeline after branch misprediction
- More instruction processing work to throw away
Data Parallelism
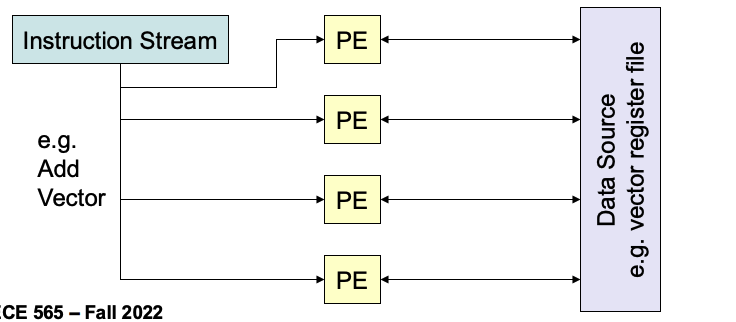
SuperScalar Processor
- Expose Instruction-Level Parallelism (ILP)
- Process multiple instructions in parallel through stages
- Add more hardware to fetch, decode, execute > 1 instruction
- Multiple execution units or ALUs
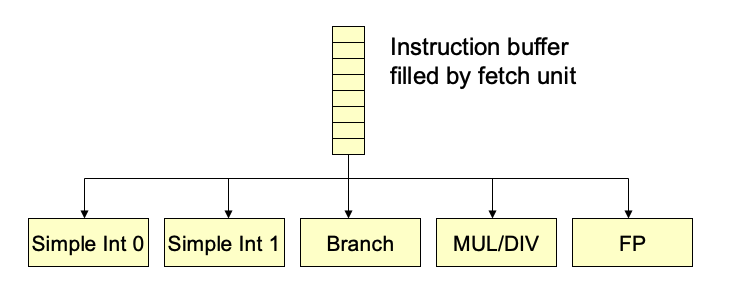
- Can send N instructions per cycle from instruction buffer to available execution units
- Many modern processors are also out-of-order OoO
- Can send instructions for execution OoO from instruction buffer
- Hardware keeps track of which instructions have inputs ready
- Pipeline resource hazards in addition to control & data hazards
- E.g. cannot begin execution of 3 divide instructions in a cycle, if there is only 2 divide units
Instruction Scheduling
- order program instructions to maximize all of this parallelism & keep execution resources busy
- Should order instructions to minimize impact of hazards
- Reordering restricted by control & data dependences
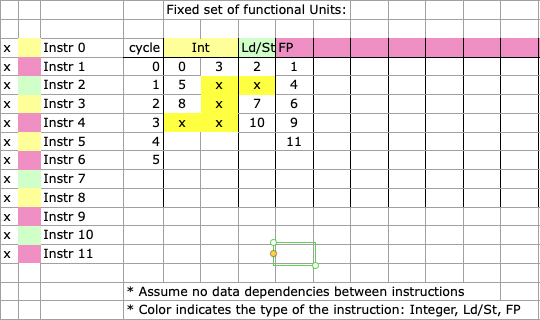
This is a resource hazard example for the In order processor
If rescheduling is allowed, the processor can execute the instructions in a different order to avoid the resource hazard.
Multicore Processors
- ILP Improvements Slowing Down
- More and more cores per chip
Levels of Parallelism for Parallel Procs
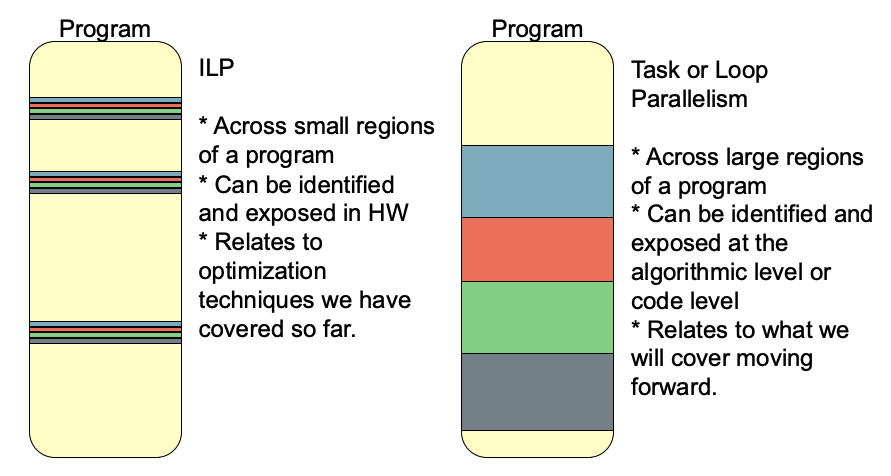
- Program level parallelism
- Various independent programs execute together
- no communication between programs
- Hard to load balance
- Low degree of parallelism
- Task level parallelism
- Arbitrary code segments in a single program
- Large granularity, low overhead, low communication
- Hard to load balance
- Low degree of parallelism
- Loop level parallelism
- Only can be reach when Each iteration can be computed independently
- Very high parallelism
- easy to achieve load balance
Parallel Programming Models
- An abstraction provided by the hardware to programmers
-
Determines how easy/difficult for programmers to express their algorithms into computation tasks that the hardware understands
- Uniprocessor programming model
- Multiprocessor programming model
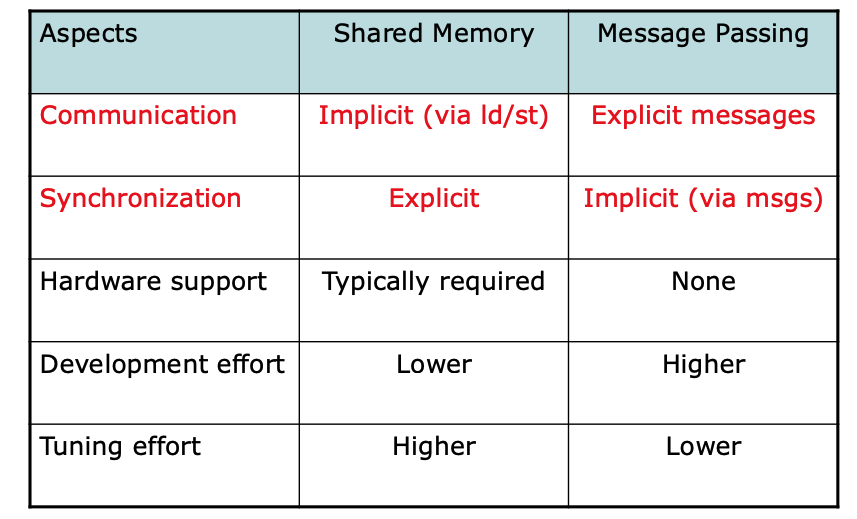
- Shared Memory / Shared Address Space
- Each memory location visible to all processors
- Message Passing
- Each memory location visible to 1 (or a subset of) processors
- Shared Memory / Shared Address Space
Shared Memory vs. Message Passing
Creating a Parallel Program
- Task Creation: identifying parallel tasks, variable scopes, synchronization
- Finding parallel tasks:
- Code analysis
- Algorithm analysis
- Viriable partitioning:
- Shared variables
- Private variables
- Reduction variables
- Syncronization:
- Finding parallel tasks:
- Task Mapping: grouping tasks, mapping to processors/memory
- Static & Dynamic Mapping
- Block & Cyclic Mapping
- Dimension Mapping: column-wise or row-wise
- Communication and Data locality considerations
Code Analysis
- Focus mainly on loop dependence analysis
- True, Anti, Output dependence
- Loop-carried vs. Loop independent
- ITG, LDG
-
Example:

- DOACROSS Parallelization
- Dependecy
for (i=1; i<=N; i++) { S: a[i] = a[i-1] + b[i] * c[i]; }S[i] =>T S[i+1]

- Dependecy
- DOPIPE Parallelization
- Dependecy
for (i=2; i<=N; i++) { S1: a[i] = a[i-1] + b[i]; S2: c[i] = c[i] + a[i]; }S1[i] =>T S2[i]
S1[i] =>T S1[i+1]
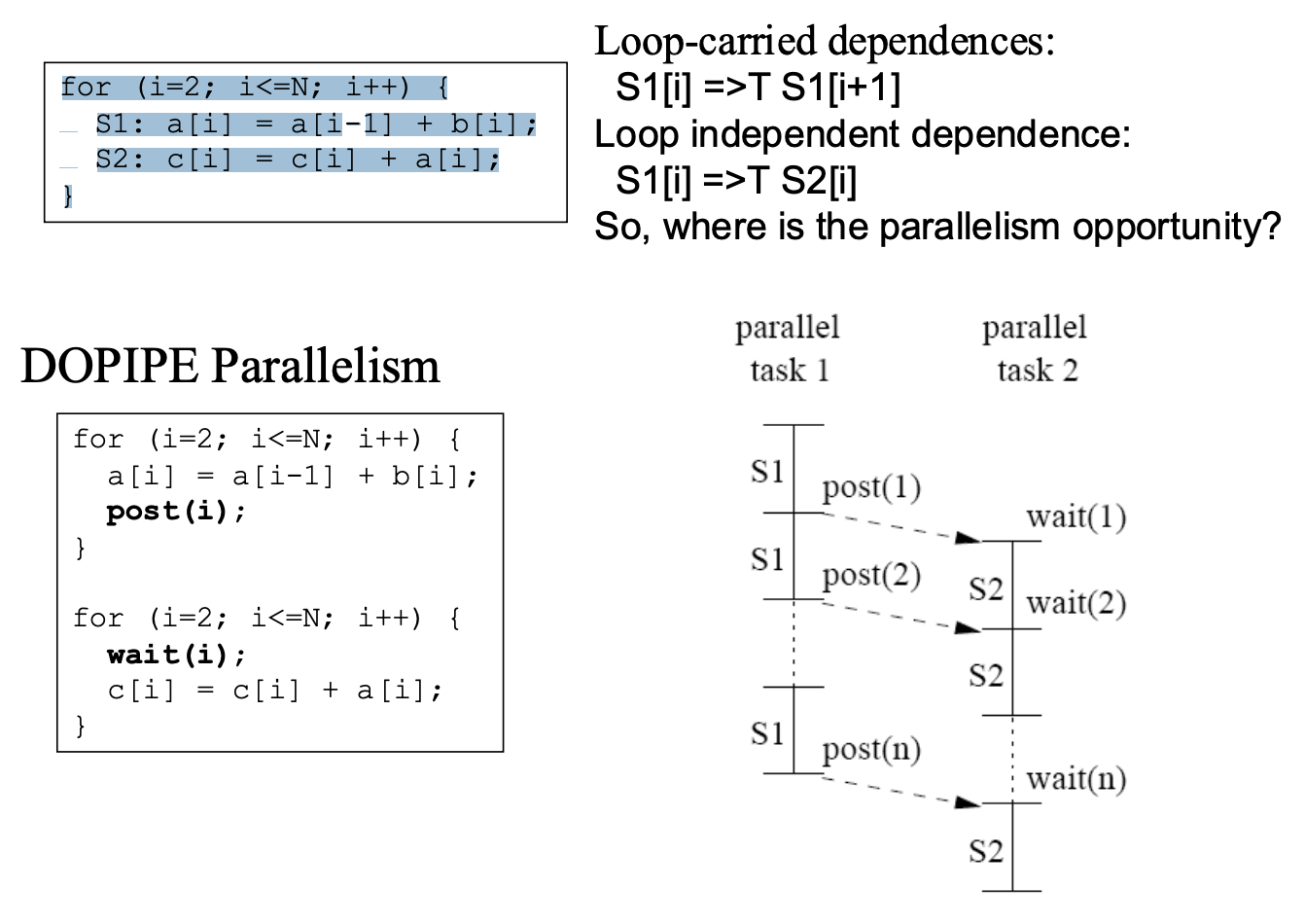
- Dependecy
Algorithm Analysis
code analysis misses parallelization opportunities available at the algorithm level
Determining Viriable Scope
- Basic Category:
- Read-Only: variable is only read by all tasks
- R/W non-conflicting: variable is read, written, or both by only one task
-
R/W Conflicting: variable written by one task may be read by another
- example:
-
for (i=1; i<=n; i++) for (j=1; j<=n; j++) { S1: a[i][j] = b[i][j] + c[i][j]; S2: b[i][j] = a[i][j-1] * d[i][j]; S3: c[n][j] = d[i-1][j]; }Define a parallel task as each “for i” loop iteration
Here
iis a R/W conflicting variable, since each task will take control of severalivalues, which means they will write to the same variable. -
for (i=1; i<=n; i++) for (j=1; j<=n; j++) { S1: a[i][j] = b[i][j] + c[i][j]; S2: b[i][j] = a[i-1][j] * d[i][j]; S3: e[i][j] = a[i][j]; }Parallel task = each “for j” loop iteration
Here
jis a R/W conflicting variable, same reason as above.
-
- Variable Privatization
- Conflicting variable that, in program order, is always defined (=written) by a task before use (=read) by the same task
- Conflicting variable whose values for different parallel tasks are known ahead of time (hence, private copies can be initialized to the known values)
- making private copies of a shared variable
- R/W Conflicting => R/W Non-conflicting
- Reduction Variables and Operation
- Reduces elements of some vector/array down to one element: sum, multiplication, logical
- Reduction variable is updated by each task, and the order of update is not important
- commutative and associative
- How we do it:
- Should be declared shared:
- Read-only variables
- R/W Non-conflicting variables
- Should be declared reduction:
- Reduction variables
- Other R/W conflicting variables:
- Privatization possible? If so, privatize them
- Otherwise, declare as shared, but protect with synchronization
- Should be declared shared:
Task Mapping
- Static and Dynamic Mapping
- Static: tasks are assigned to threads ahead of time
- lower runtime overhead
- Dynamic: tasks are assigned to threads at runtime
- better load balancing
- need shared task queue
- Static: tasks are assigned to threads ahead of time
- Block and Cyclic Mapping
- Cyclic: Threads are assigned tasks in a striped fashion
- 1st thread: 1st, 1+n, 1+2n, …
- 2nd thread: 2nd, 2+n, 2+2n, …
- Block: Threads are assigned contiguous chunks of tasks
- 1st thread: 1st, 2nd, …, n
- 2nd thread: n+1, n+2, …, 2n
- Consider both data locality and communication overhead
- Want to exchange minimal data between threads
- Also want to maximize locality
- Cyclic: Threads are assigned tasks in a striped fashion
OpenMP Programming
- OpenMP: a set of compiler directives, library routines, and environment variables that can be used to specify high-level parallelism in Fortran and C/C++ programs
OpenMP Usage
#pragma omp directive-name [clause[ [,] clause]...] new-line
//structured-block
Forms a team of threads and starts parallel execution, Thread that enters the region becomes the master
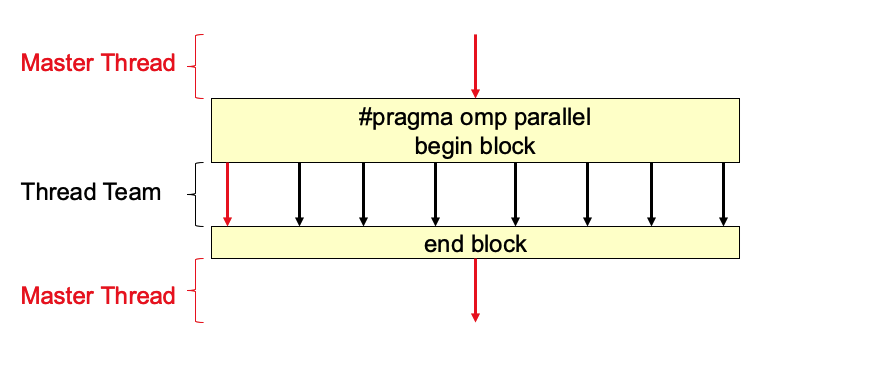
After parallel block, the thread team sleeps until needed
#include <omp.h>
{
omp_set_num_threads(4);
#pragma omp parallel
{
#pragma omp for private(i), shared(N, A, B, C)
for (int i=0; i<N; i++) {
A[i] = B[i] + C[i];
}
}
}
#include <omp.h>
{
omp_set_num_threads(4);
#pragma omp parallel for private(i), shared(N, A, B, C)
for (int i=0; i<N; i++) {
A[i] = B[i] + C[i];
}
}
The above two code snippets are doing the same thing
- directive-name: the name of the directive
- parallel: create a team of threads
- for: distribute loop iterations among threads
- sections: distribute sections among threads
- section: define a section of code to be executed by a single thread
- single: execute a block of code in a single thread
- only one thread executes the block, no guarantee which thread
#pragma omp single
- master: execute a block of code in the master thread
- only the master thread executes the block
#pragma omp master
- target: offload code to a target device
- critical: ensure that only one thread executes a block of code at a time
#pragma omp critical (name)
- atomic: ensure that a block of code is executed atomically
#pragma omp atomic [read | write | update | capture]- read expression:
v = x; - write expression:
x = expr; - update expression:
x++; - capture expression:
V = x++;
- read expression:
- Ensure a specific storage location is updated atomically
- clause: a directive-specific option
- private: private variables
- shared: shared variables
- reduction: reduction variables
reduction(reduction-identifier: list) - collapse: collapse nested loops into one loop
- at least 2
- ordered: enforce order inside a loop
- ordered directives are executed same way as the sequential loop would execute them (one at a time)
- Each loop iteration may execute at most one ordered directive
- example
void work(int i) { printf(“i = %d\n”, i); } // ... int i; #pragma omp parallel for ordered for (i=0; i < 20; i++) { #pragma omp ordered work(i); //Each iteration of the loop has 2 ordered clauses! #pragma omp ordered work(i+100); }void work(int i) { printf(“i = %d\n”, i); } // ... int i; #pragma omp parallel for ordered for (i=0; i < 20; i++) { if (i <= 10) { #pragma omp ordered work(i); } if (i > 10) { //two ordered clauses are mutually exclusive #pragma omp ordered work(i+100); } } //if we change (i > 10) to (i > 9), it becomes invalid
- Type of variables
- shared: shared among all threads
- private: each thread has its own copy
- firstprivate: private copy initialized with the value of the original variable
- lastprivate: private copy value of last iteration is copied back to the original variable
- reduction: variable that is the target of a reduction operation performed by the loop, e.g., sum
- example:
#include <omp.h> { int sum = 0; #pragma omp parallel for default(shared) private(i) reduction(+:sum) for(i=0; i<n; i++) sum = sum + A[i]; }#include <omp.h> { int sum = 0; int local_sum[num_threads]; #pragma omp parallel for default(shared) private(i) for(i=0; i<n; i++) local_sum[thread_id] = local_sum[thread_id] + A[i]; for(i=0; i<num_threads; i++) sum += local_sum[i]; }so basically, these two code snippets are doing the same thing, and the
reductionclause allocate a copy of ‘sum’ per thread and combine per-thread copies into original ‘sum’ at the end
- example:
- Barriers
- implicit after each parallel section
- use
nowaitclause to avoid barrier#include <omp.h> //… { //… #pragma omp for default(shared) private(i) nowait for(i=0; i<n; i++) A[i]= A[i]*A[i]- 3.0; }
OpenMP API functions
omp_get_num_threads(): return the number of threads in the current teamomp_set_num_threads(): set the number of threads to be used in the next parallel regionomp_init_lock(): initialize a simple lockomp_set_lock(): acquire a simple lockomp_unset_lock(): release a simple lock
OpenMP SCHEUDLE directive
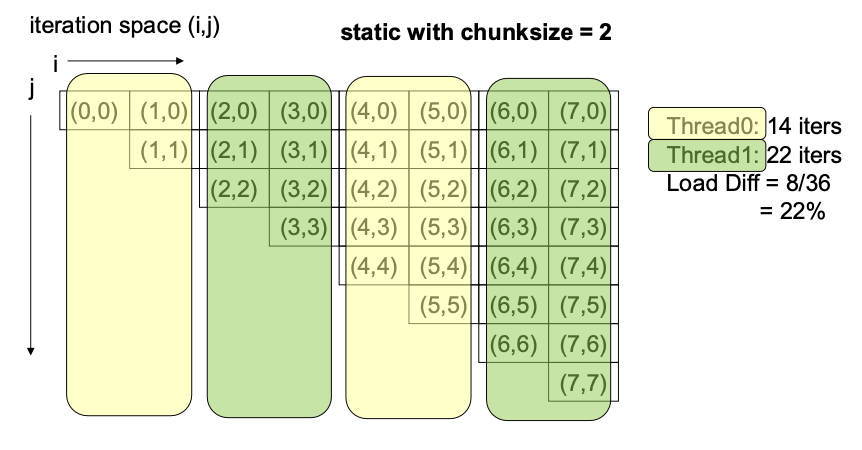
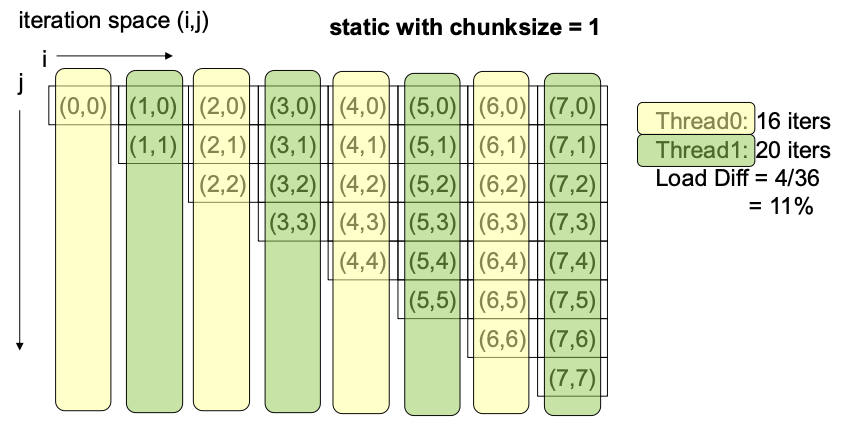
StaticDynamic: tasks and central task queueGuided: except that the task sizes are not uniform, early tasks are exponentially larger-
Runtime: Check the environment variableOMP_SCHEDULEat run time to determine what scheduling to use SCHEDULE(Static | Dynamic | Guided | Runtime, chunksize)sum = 0; pragma omp parallel for reduction(+:sum) schedule(static, n/p) { for (i=0; i<n; i++) for (j=0; j<i; j++) sum = sum + a[i][j]; print sum; }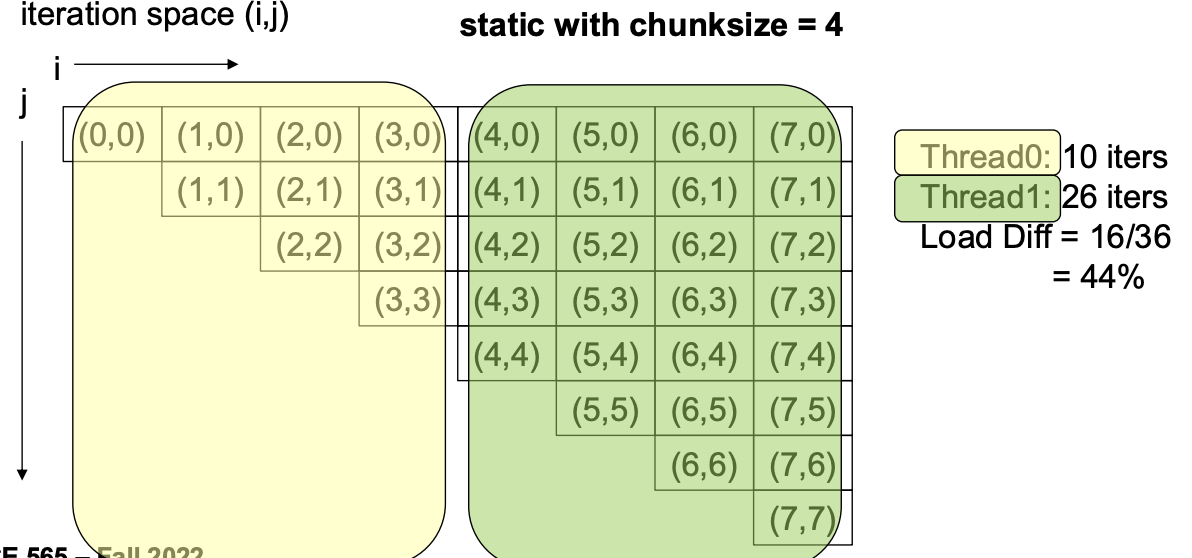
OpenMP Memory Model
- relaxed-consistency
- Each thread can have its own temporary view of memory
- thread’s temporary view of memory is not required to be consistent with memory
- Update to shared memory from one thread may not be seen by the other thread “immediately”
- shared memory
- All threads share a single store called memory
- May not actually represent RAM
Ensure Consistent View of Memory
flush: ensure that all threads have a consistent view of memory#pragma omp flush(list)listis a comma-separated list of variables- example
#pragma omp parallel { //… #pragma omp flush(A) //… } - orders:
- Those before the flush complete before the flush executes
- Those after the flush complete after the flush executes
- Flushes with overlapping flush-sets cannot be reordered
void thread1() { shared_var = 42; #pragma omp flush(shared_var) } void thread2() { int local_var; #pragma omp flush(shared_var) local_var = shared_var; printf("Thread 2 reads shared_var: %d\n", local_var); }
OpenMP Task Directive
#pragma omp task [clause[ [,] clause]...]
- Generates a task for a thread in the team to run
- When a thread enters the region it may
- Immediately execute the task, or
- Defer its execution (another thread may be assigned the task)
- clauses:
- if, final, untied, default, mergeable, private, firstprivate, shared
if: When expression is false, generates an undeferred taskfinal: When expression is true, generates a final task- All tasks within a final task are included
- Included tasks are undeferred and also execute immediately in the same thread
untied: Task is not tied to the thread that created itmergeable: Task can be merged with the current task
- Three Logical Task Concepts:
- Deferred Task: generates a new task, Put the task on the task queue for any thread to execute
- Undeferred Task: suspends its current task, executes newly encountered task, may resume its previously suspended task
- Included Task: simply merges the task into its current task
Parallel Programming Issuses
- Correctness
- Result preservation
- Synchronization points and types
- Variable partitioning
- Performance
- Task granularity
- Syncronization granularity
- Lack of utilization of reduction variables
Result Preservation
- example: rounding problem of floating-point numbers, the order of summation can affect the result, which is a problem in parallel programming
Synchronization Points and Types
- Race Condition
Variable Partitioning
- example
#pragma omp parallel for shared(b,temp) private(a,c) for (i=0; i<N; i++) { temp = b[i] + c[i]; a[i] = a[i] * temp; }- c should be shared but declared private
- storage overhead
- outcome is non-deterministic, depends on whether the private c is initialized to the global c
- a should be shared but declared private
- storage overhead
- outcome non-deterministic, depends on whether the private a is merged into the global a
- temp should be declared private but declared shared
- wrong output due to threads overwriting temp
- c should be shared but declared private
Parallel Task Granularity

- Easy way to increase parallel thread granularity: parallelize the outer loop rather than the inner loop
- But must watch out for load balance
Syncronization Granularity
- Linked list example:
- coarse-grained: lock the entire list
- fine-grained: lock each node
Inherent vs. Artifactual Communication
Overhead and Scalability factors in parallel programming
- Important metric:
- communication to computation ratio
- Use this to infer the scalability of a parallel program
- inherent communication
- Caused by task-to-process mapping
- actual communication
- Caused by process-to-processor mapping
Communication-to-Computation Ratio

Here in the example we assume three different ways to map the nodes into processors. Each side of the square indicate N elements.
-
Block-wise partitioning
\[CCR = \frac{\text{Comm}}{\text{Comp}} = \frac{\frac{4n}{\sqrt{p}}}{\frac{n^2}{p}} = \frac{4 \sqrt{p}}{n}\] -
Row-wise partitioning
\[CCR = \frac{\text{Comm}}{\text{Comp}} = \frac{\frac{2n}{\sqrt{p}}}{\frac{n^2}{p}} = \frac{2p}{n}\]
Memory Hierachy Issue
key to performance: spatial and temporal locality at each hierarchy level
- Registers, caches, local memory, remote memory (topology)
- Lower level: higher size, higher communication cost
Exploiting Spatial Locality at Page Level
- Page distribution policy in NUMA:
- Single node: all pages in a single node, lack of spatial locality, contention
- Round-robin: pages are allocated in consecutive nodes, lack of spatial locality, lower contention
- First touch: pages are allocated in the node where the first write occurs, better spatial locality, lower contention
- Page Migration: Monitor and migrate pages at runtime
Syncronization
- Race Condition
- Result of computation by concurrent threads depends on the precise timing of the execution of an instruction sequence by one thread relative to another
- Non-deterministic result
- Global Event Synchronization
BARRIER (name, nprocs):Thread will wait at barrier call until nprocs threads arrive- Built using lower level primitives
- Heavyweight operation
- Groups Event Synchronization
- Synchronize across a subset of all parallel processes
- Done using flags or barriers
- Basic concept of producers and consumers
- Single producer, multiple consumer
- Multiple producer, single consumer
- Multiple producer, multiple consumer
- Synchronize across a subset of all parallel processes
- Point-to-point Event Synchronization
- thread notifies another thread so it can proceed
- Typical in producer-consumer behavior
- Concurrent programming on uniprocessors: semaphores
- semaphores or monitors or variable flags
- thread notifies another thread so it can proceed
Pthread
- POSIX pthreads: a standard for thread creation and management
- Basic Usage:
#include <pthread.h>gcc -o p_test p_test.c -lpthread
- Create a pthread:
int pthread_create(pthread_t *thread, pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);pthread_tis the thread identifierpthread_attr_tis the thread attributesstart_routineis the function to be executed by the threadargis the argument to the function- example
pthread_t *thrd = (pthread_t*)malloc(sizeof(pthread_t)); pthread_create(thrd, NULL, &do_work_fcn, NULL); //Or pthread_t thrd; pthread_create(&thrd, NULL, &do_work_fcn, NULL);
- Pthread Destruction
pthread_join(pthread_t thread, void **retval);- Blocks the calling thread until the specified thread terminates
retvalis the return value of the thread
pthread_exit(void *value_ptr);- Terminates the calling thread
value_ptr:Provides value_ptr to any pending pthread_join() call
- Pthread Mutex
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutex_attr);pthread_mutex_lock(&mutex);pthread_mutex_trylock(&mutex);pthread_mutex_unlock(&mutex);pthread_mutex_destroy(&mutex);
- Pthread Condition Variable
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *cond_attr);pthread_cond_wait(&cond, &mutex);pthread_cond_signal(&cond);pthread_cond_broadcast(&cond);pthread_cond_destroy(&cond);- Always used in conjunction with a mutex lock
void *thr_func1(void *arg) { /* thread code blocks here until MAX_COUNT is reached */ pthread_mutex_lock(&count_lock); while (count < MAX_COUNT) pthread_cond_wait(&count_cond, &count_lock); pthread_mutex_unlock(&count_lock); /* proceed with thread execution */ pthread_exit(NULL); } /* some other thread code that signals a waiting thread that MAX_COUNT has been reached */ void *thr_func2(void *arg) { pthread_mutex_lock(&count_lock); /* some code here that does interesting stuff and modifies count */ if (count == MAX_COUNT) { pthread_mutex_unlock(&count_lock); pthread_cond_signal(&count_cond); } else { pthread_mutex_unlock(&count_lock); } pthread_exit(NULL); }
- Pthread Barrier
- ` pthread_barrier_t barrier = PTHREAD_BARRIER_INITIALIZER(count);`
int pthread_barrier_init(pthread_barrier_t *barrier, const pthread_barrierattr_t *attr, unsigned count);int pthread_barrier_wait(pthread_barrier_t *barrier);
Parallel Programming for Linked Data Structures
- Split traversal step from processing step(s)
- Master thread traverses the list
-
Creates a child thread to process each node as required
- Parallel Strategy
- Global lock approach
- Each operation logically has two steps
- Traversal
- Modification
- perform the traversal in parallel, but list modification in a critical section
IntListNode_Insert(node *p) { /* perform traversal */ acq_write_lock(); /* then check validity: (1) nodes still there, (2) link still valid */ /* if not valid, repeat traversal */ /* if valid, modify list */ if (prev->next != p || prev->deleted || p->deleted) /* repeat list traversal step */ else /* insert node */ //… rel_write_lock(); }
- Each operation logically has two steps
- Fine-grained lock approach
- Associate each node with a lock (read, write)
- (Read and write) operations execute in parallel except when they conflict on some nodes
- Deadlocks can be avoided by imposing a global lock acquisition order
- Careful ordering of lock acquisition must be enforced: always acquire locks for nodes from left to right in list
void Insert(pIntList pList, int x) { int succeed; // traversal code to find insertion point succeed = 0; do { acq_write_lock(prev); acq_read_lock(p); if (prev->next != p || prev->deleted || p->deleted) { rel_write_lock(prev); rel_read_lock(p); //Repeat traversal; return if not found } else succeed = 1; } while (!succeed) newNode->next = p; if (prev != NULL) prev->next = newNode; else pList->head = newNode; rel_write_lock(prev); rel_read_lock(p); }
- Careful ordering of lock acquisition must be enforced: always acquire locks for nodes from left to right in list
- Global lock approach
Memory Consistency
- Cache Coherence
- deals with ordering of writes to a single memory location
- only needed for systems with caches
- Memory consistency
- deals with ordering of reads/writes to all memory locations
- concerns systems with or without caches
Programmers’ Intuition
- Program order expectation
- programmers expect that the order in which memory accesses are executed in a thread follows the order in which they occur in the source code
- Atomicity expectation
- An expectation that a read/write happens instantaneously/instantly with respect to all processors
-
Memory accesses coming out of a processor should be performed in program order, and each of them should be performed atomically
- Sequential Consistency
- programmers’ expectations have been found to fit closely to Sequential Consistency (SC)

Building SC systems
- Program order
- compiler does not reorder memory accesses
- Declare critical variables as volatile
- Atomicity
- Execute one memory access one at a time, in program order
-
Performance: Limited by Strict Ordering Requirements

Relaxed Consistency Models
Allows “some” memory accesses to be reordered or overlapped
- Safety Nets
- Fence instruction ensures ordering between preceding load/store and following load/store
- Relaxed consistency models
- Processor Consistency (PC)
- Weak ordering (WO)
- Acquire / Release Consistency (RC)
- Lazy Release Consistency (LRC)
Implementation of Memory Fence
- Fence ensures that mem ops that are younger are not issued until the older mem ops have globally performed
- Wait until all older writes have been posted on the bus
- Wait until all older reads have completed
- Flush the pipeline to avoid issuing younger mem ops early
Processor Consistency (PC)

Lock Free Data Structures
C++ Memory Model Support
In C++ 11:
std::atomic<T>: atomic operations on type Tload(),store()- Default mode for loads/stores to atomics is sequential consistency
- Likely expensive to enforce
- compiler may just insert fences (memory barriers)
std::memory_order_relaxed- Atomicity is provided, but any reordering is possible
- Much Faster
std::memory_order_acquire- Atomicity is provided, and also ordering
- less overhead in a general program
- Default mode for loads/stores to atomics is sequential consistency
Lock-Free Data Structures
class LinkedList {
class Node{
public:
const int data;
std::atomic<Node *> next;
Node(int d): data(d), next(nullptr) { }
Node(int d, Node * n): data(d), next(n) { }
~Node() { }
};
std::atomic<Node*> head;
//...
};
Lock-Free LinkedList::addFront
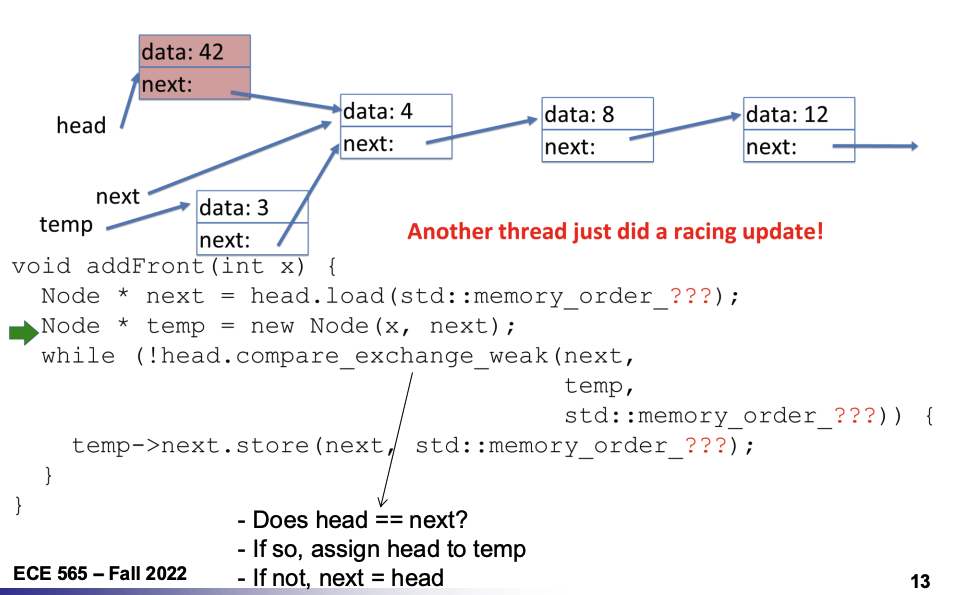
std::memory_order_acq_relforhead.compare_exchange_weak()-
Acquire and Release Semantics
- Acquire semantics
- Ensures that all memory operations before the acquire operation are completed before the acquire operation
- Release semantics
- Ensures that all memory operations after the release operation are completed after the release operation
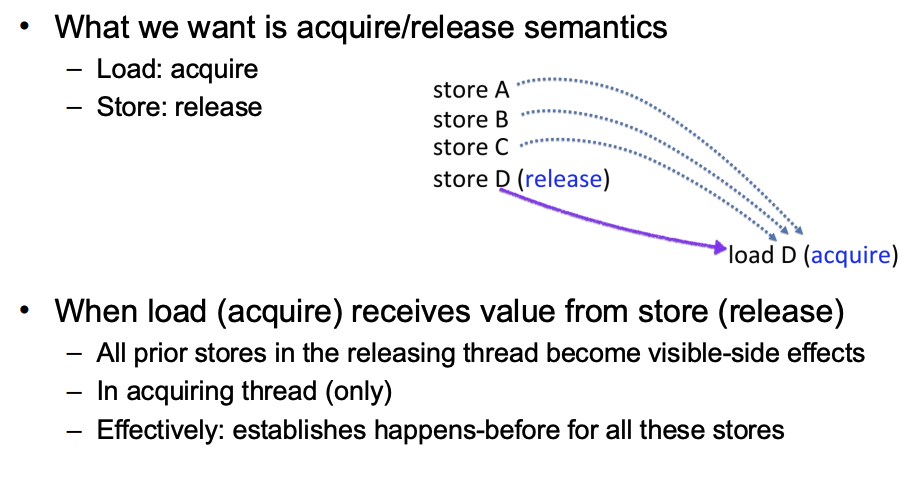
- Acquire semantics
-
std::memory_order_acq_rel- Both acquire and release semantics
- Acquire semantics for the load: can see all memory writes before the load
- Release semantics for the store: momery operations of current thread are visible to other threads after the store
- Why
std::memory_order_acq_rel?- Load: will read head pointer, need to ensure head is the latest value (Acquire)
- Store: If head is updated successfully, need to ensure that all memory operations of current thread are visible to other threads (Release)
- Both acquire and release semantics
-
std::memory_order_relaxedfortemp->next.store- temp is private to the thread
- next step is CAS with
std::memory_order_acq_rel, will ensure that the store is visible to other threads - So we can use
std::memory_order_relaxedhere
std::memory_order_relaxedforhead.load()- CAS will perform acquire, and fail if head is changed
- so simply load head with
std::memory_order_relaxed
Lock-Free LinkedList::addSorted

- Why not use
std::memory_order_seq_cstfor all operations?- right for correctness, but too expensive
Lock-Free LinkedList::removeFront

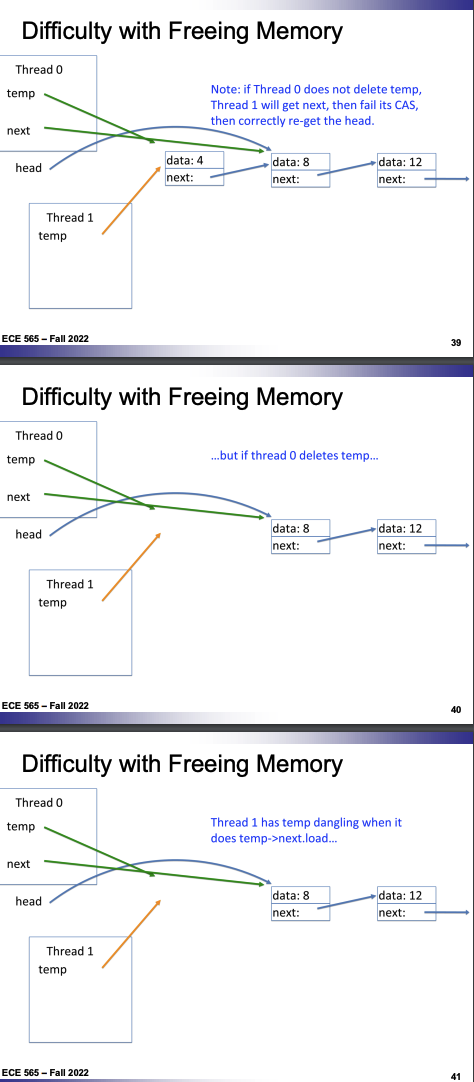
- Difficult to clean up memory
- Delete later as no other thread still references it
- Possibility for recycle: only if no other thread is referencing it
- Solutions:

- GC
- Stop the world
- Consider root sets from all threads
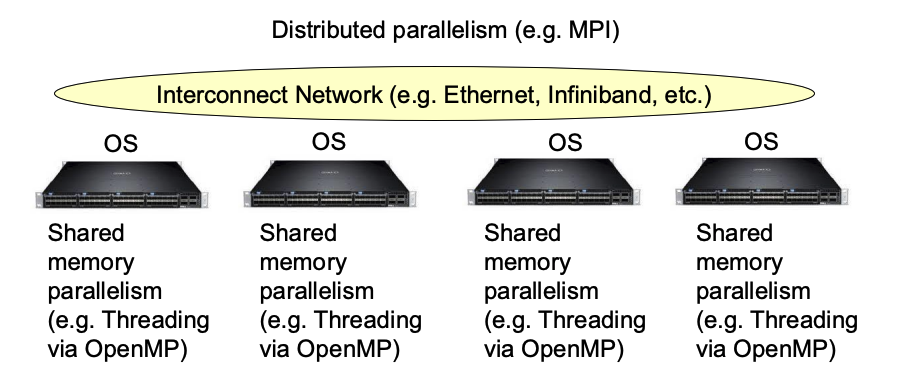
Programming for Clusters
Distributed vs. Shared Memory
- Shared memory
- Communication: implicit
- Synchronization: explicit
- Distributed (clusters)
- Communication: explicit
- Synchronization: implicit
MPI (Message Passing Interface)
A language-independent communication protocol for parallel-computers
- Provides explicit message passing between nodes
- Uses SPMD computation model
- Single program, multiple data
- Multiple instances of a single program
- All work on different data at the same time
- MPI facilitates data communication between processes
- Program could run on one machine or cluster of machines
- one machine: using MPI for IPC
- cluster: using MPI for network communication
- MPI Functions
// Initialize MPI int MPI_Init(int *argc, char **argv) // Determine number of processes within a communicator int MPI_Comm_size(MPI_Comm comm, int *size) // Determine processor rank within a communicator int MPI_Comm_rank(MPI_Comm comm, int *rank) // Exit MPI (must be called last by all processors) int MPI_Finalize() // Send a message int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) // Receive a message int MPI_Recv(void *buf, int count, MPI_Datatype datatype,int source, int tag, MPI_Comm comm, MPI_Status *status)MPI_Comm: communicator,MPI_COMM_WORLDfor global channelMPI_Datatype: enum for data type, likeMPI_INTdest/source: The “rank” of the process to send a message to / receive from- Both MPI_Send and MPI_Recv are blocking calls
- tag allows for message organization, like filtering
- Simple Example
-
#include <stdio.h> #include <mpi.h> int main (int argc, char *argv[]) { int rank, size; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); //get current process id MPI_Comm_size(MPI_COMM_WORLD, &size); //get number of processes printf(“Hello World from process %d of %d\n”, rank, size); MPI_Finalize(); return 0; } - Controller-worker paradigm
- Controller (rank 0) process: Creates strings, Sends them to worker processes
- Worker processes: Modify their string, Send it back to the master
-
- MPI Compile and Run:
- Compile
mpirun -np <num_processors> <program> mpiexec -np < num_processors> <program> # a synonym - Start processes
> mpicc hello_mpi.c > mpirun -np 4 a.out 0: We have 4 processors 0: Hello 1! Processor 1 reporting for duty 0: Hello 2! Processor 2 reporting for duty 0: Hello 3! Processor 3 reporting for duty - By default, MPI chooses lowest-latency communication resource available; shared memory in this case
- MPMD (Multiple Program, Multiple Data) execution
mpirun -np 2 a.out : -np 2 b.out- launches a single parallel application
- All in the same MPI_COMM_WORLD
- Ranks 0 and 1 are of instances a.out
- Ranks 2 and 3 are of instances b.out
- Compile
- Performance
- bottleneck is the message passing
- much longer latency and much less B/W
MapReduce
MapReduce framework does several things
- Runs tasks in parallel
- Manages communication and data transfers
- Provides redundancy and fault tolerance
OverView
- Consists of two functional operations: map and reduce
- Map: applies a function to an iterable data set
- Reduce: applies a function to an iterable data set cumulatively
- Map
- Split the input into multiple pieces
- Pieces are processed as (key, value) pairs
- Mapper function uses these (key, value) pairs outputs another set of (key, value) pairs
- Reduce
- Collects the input from the previous map
- May be on different nodes and require copying
- Merge-sorts the input
- So that key-value pairs for a given key are contiguous
- Reads the input sequentially and splits values into lists of values with the same key
- Passes this data (keys and lists of values) to your reduce method (in parallel) and concatenates results
- Collects the input from the previous map
- Combine
- Optional step
- Could do reduce step for in-memory values after map
Programming for Accelerators w/ Directives
Jacobi Iteration
Iteratively converges to correct value (e.g. Temperature), by computing new values at each point from the average of neighboring points.
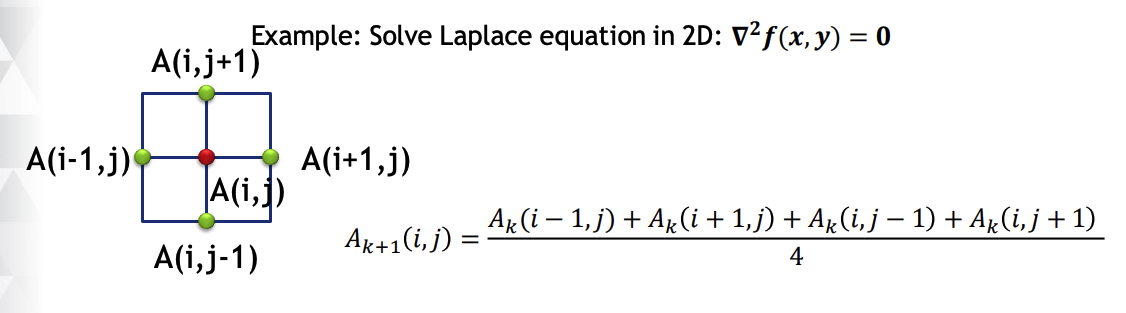
update all values until convergence
- original code
while ( err > tol && iter < iter_max ) { //Convergence Loop err=0.0; for( int j = 1; j < n-1; j++) { for(int i = 1; i < m-1; i++) { Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); err = max(err, abs(Anew[j][i] - A[j][i])); } } for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; } } iter++; }
CPU-Parallelism
- CPU-Parallelism
while ( error > tol && iter < iter_max ) { error = 0.0; #pragma omp parallel for reduction(max:error) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); error = fmax( error, fabs(Anew[j][i] - A[j][i])); } } #pragma omp parallel for for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; } } if(iter++ % 100 == 0) printf("%5d, %0.6f\n", iter, error); } - Reduce time of thread creation
while ( error > tol && iter < iter_max ) { error = 0.0; #pragma omp parallel { #pragma omp for reduction(max:error) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); error = fmax( error, fabs(Anew[j][i] - A[j][i])); } } #pragma omp barrier #pragma omp for for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; } } } if(iter++ % 100 == 0) printf("%5d, %0.6f\n", iter, error); }
OpenMP Target Directives
Offloads execution and associated data from the CPU to the GPU
- The target device owns the data, accesses by the CPU during the execution of the target region are forbidden.
- Data used within the region may be implicitly or explicitly mapped to the device.
- All of OpenMP is allowed within target regions, but only a subset will run well on GPUs.
Target the GPU
-
implicitly

-
explicitly

allocclause: allocate memory on the devicetoclause: copy data from host to devicefromclause: copy data from device to hosttofromclause: copy data from host to device and backmapclause: map data to the device
GPU Basics (Nvidia specific)
- GPUs are composed of 1 or more independent parts, known as Streaming Multiprocessors (“SMs”)
- Threads are organized into threadblocks.
- Threads within the same theadblock run on an SM and can synchronize.
- Threads in different threadblocks (even if they’re on the same SM) cannot synchronize.
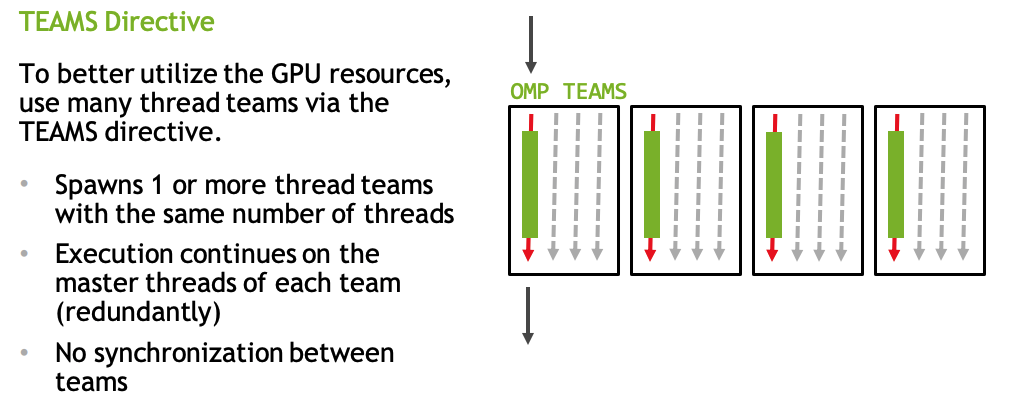
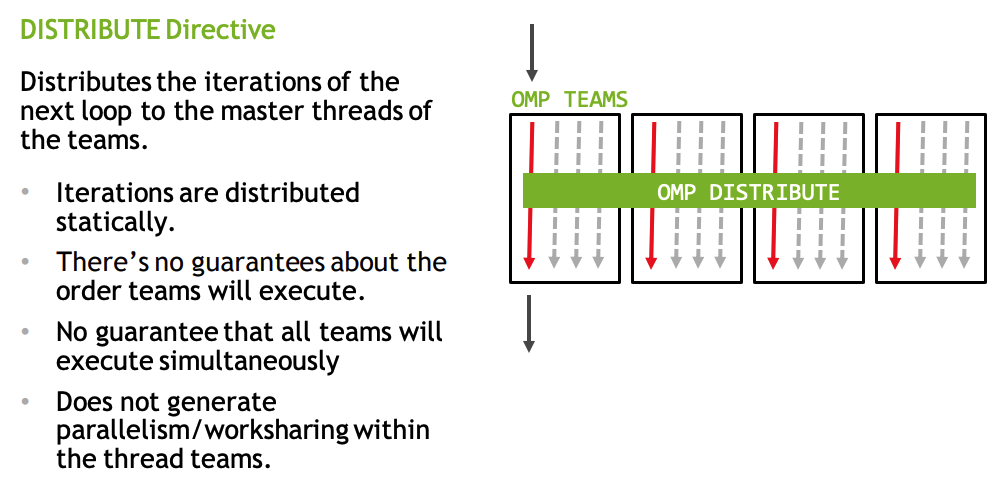
OpenMP Teams

#pragma omp target data map(alloc:Anew) map(A)
while ( error > tol && iter < iter_max )
{
error = 0.0;
#pragma omp target teams distribute parallel for reduction(max:error)
for( int j = 1; j < n-1; j++)
{
for( int i = 1; i < m-1; i++ )
{
Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]);
error = fmax( error, fabs(Anew[j][i] - A[j][i]));
}
}
#pragma omp target teams distribute parallel for
for( int j = 1; j < n-1; j++)
{
for( int i = 1; i < m-1; i++ )
{
A[j][i] = Anew[j][i];
}
}
if(iter % 100 == 0) printf("%5d, %0.6f\n", iter, error);
iter++;
}
- map only once for the entire loop
- spawns thread teams
- Distributes iterations to those teams
- Workshares within those teams
- parallel here will generate implicit barriers.
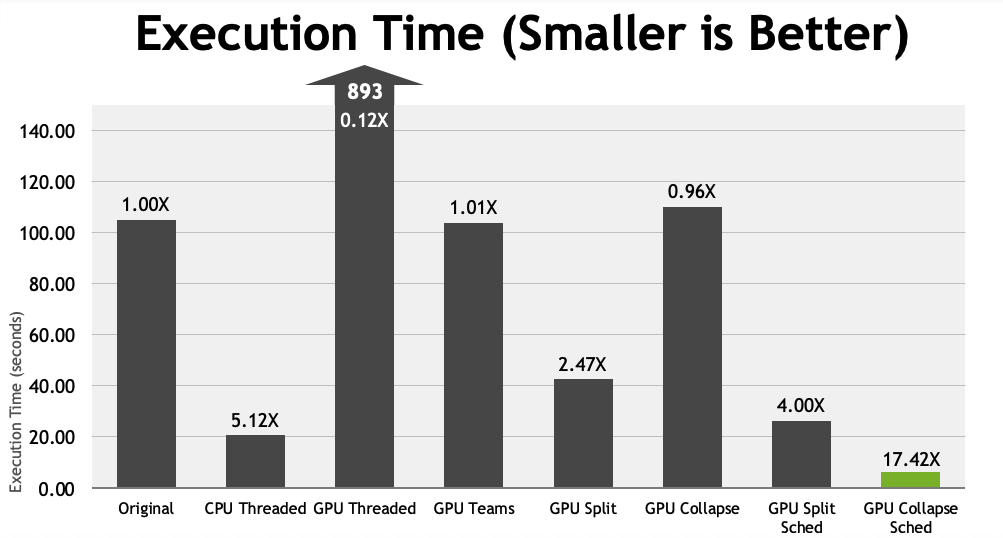
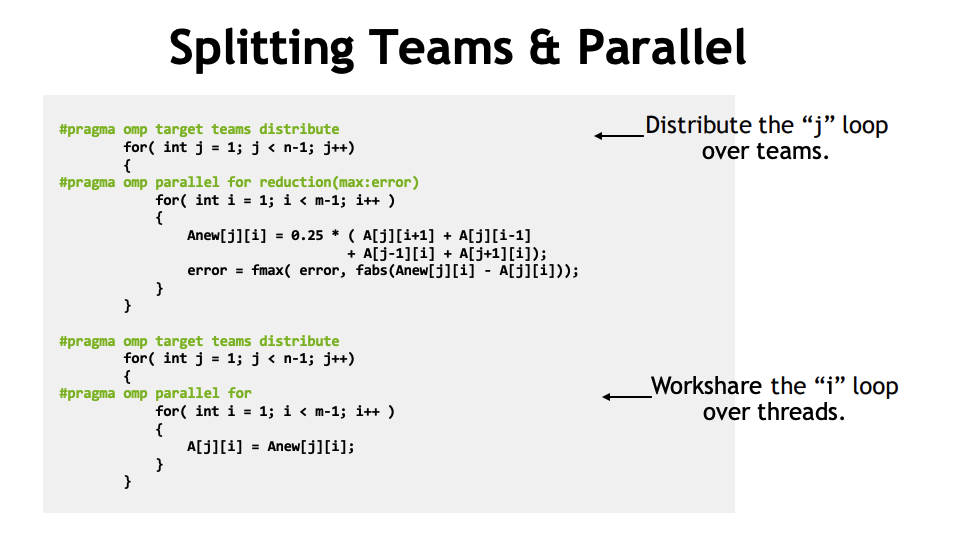
Increasing Parallelism
Currently both our distributed and workshared parallelism comes from the same loop.
- We could move the PARALLEL to the inner loop
- We could collapse them together The
COLLAPSE(N)clause - Turns the next N loops into one, linearized loop.
- This will give us more parallelism to distribute, if we so choose.
Also like this (same effect):

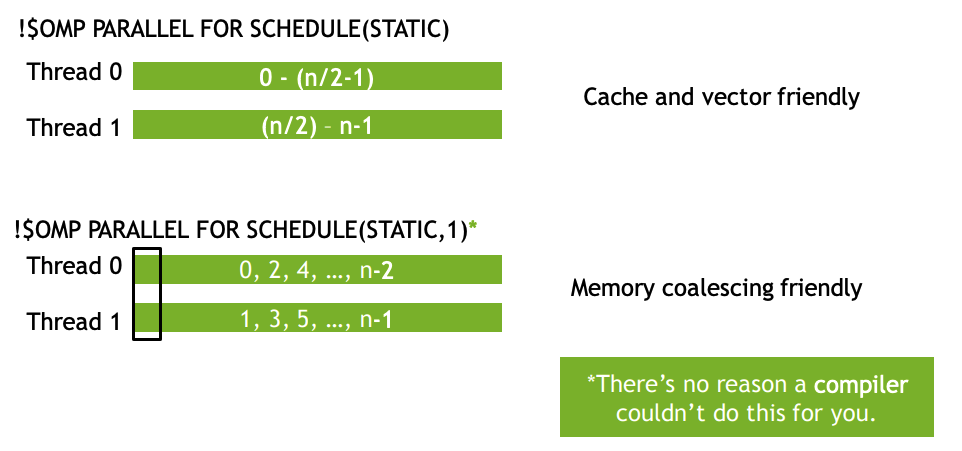
Improve Loop Scheduling
Most OpenMP compilers will apply a static schedule to workshared loops, assigning iterations in N / num_threads chunks.
- Each thread will execute contiguous loop iterations, which is very cache & SIMD friendly
- This is great on CPUs, but bad on GPUs The SCHEDULE() clause can be used to adjust how loop iterations are scheduled.
#pragma omp target teams distribute
for( int j = 1; j < n-1; j++)
{
#pragma omp parallel for reduction(max:error) schedule(static,1)
for( int i = 1; i < m-1; i++ )
{
Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]);
error = fmax( error, fabs(Anew[j][i] - A[j][i]));
}
}
#pragma omp target teams distribute
for( int j = 1; j < n-1; j++)
{
#pragma omp parallel for schedule(static,1)
for( int i = 1; i < m-1; i++ )
{
A[j][i] = Anew[j][i];
}
}
- Assign adjacent threads adjacent loop iterations
or with collapse:

result: