A simple note for system design.
From System Design Interview by Alex Xu
- K-V Store
- Unique ID Generator
- URL Shortener
- Web Crawler
- Notification System
- News Feed System
- CHAT SYSTEM
- SEARCH AUTOCOMPLETE SYSTEM
- DESIGN YOUTUBE / video sharing platform
- DESIGN GOOGLE DRIVE
K-V Store
Design scopes
- The size of a key-value pair is small: less than 10 KB.
- Ability to store big data.
- High availability: The system responds quickly, even during failures.
- High scalability: The system can be scaled to support large data set.
- Automatic scaling: The addition/deletion of servers should be automatic based on traffic.
- Tunable consistency.
- Low latency.
CAP Theorem
Check the detailed explanation if not familiar with CAP theorem.
-
CP (consistency and partition tolerance) systems: a CP key-value store supports consistency and partition tolerance while sacrificing availability.
-
AP (availability and partition tolerance) systems: an AP key-value store supports availability and partition tolerance while sacrificing consistency.
-
CA (consistency and availability) systems: a CA key-value store supports consistency and availability while sacrificing partition tolerance. Since network failure is unavoidable, a distributed system must tolerate network partition. Thus, a CA system cannot exist in real-world applications.
System Components
- Data partition: split the data into smaller partitions and store them in
multiple servers
- Distribute data across multiple servers evenly
- Minimize data movement when nodes are added or removed
- Using consistent hashing to distribute data
- Automatic scaling: servers could be added and removed automatically depending on the load.
- Heterogeneity: the number of virtual nodes for a server is proportional to the server capacity. For example, servers with higher capacity are assigned with more virtual nodes.
- Data replication: data must be replicated asynchronously over N servers, where N is a configurable parameter
- after a key is mapped to a position on the hash ring, walk clockwise from that position and choose the first N servers on the ring to store data copies.
- With virtual nodes, the first N nodes on the ring may be owned by fewer than N physical servers. To avoid this issue, we only choose unique servers while performing the clockwise walk logic.
- Consistency: Using Quorum consensus to guarantee consistency
- Definitions:
- R: read quorum of size R
- W: write quorum of size W
- N: the total number of nodes
- If R = 1 and W = N, the system is optimized for a fast read.
- If W = 1 and R = N, the system is optimized for fast write.
- If W + R > N, strong consistency is guaranteed (Usually N = 3, W = R = 2).
- consistency model:
- Strong consistency
- Weak consistency: subsequent read operations may not see the most updated value
- Eventual consistency: this is a specific form of weak consistency. Given enough time, all updates are propagated, and all replicas are consistent. Adopted by Dynamo and Cassandra
- Definitions:
- Inconsistency resolution: Versioning and vector clocks
- Versioning: treating each data modification as a new immutable version of data
- Vector clocks: a [server, version] pair associated with a data item. It can be used to check
- represented by D([S1, v1], [S2, v2], …, [Sn, vn]), where D is a data item, v1 is a version counter, and s1 is a server number, etc.
- If data item D is written to server Si
- Increment vi if [Si, vi] exists
- Otherwise, create a new entry [Si, 1]
- set a threshold for the length, if it exceeds the limit, the oldest pairs are removed
- Handling failures
- Failure detection: gossip protocol
- Each node maintains a node membership list, which contains member IDs and heartbeat counters.
- Each node periodically increments its heartbeat counter
- Each node periodically sends heartbeats to a set of random nodes, which in turn propagate to another set of nodes
- Once nodes receive heartbeats, membership list is updated to the latest info
- If the heartbeat has not increased for more than predefined periods, the member is considered as offline
- temporary failure handling
- replica set: a set of nodes that store the same data. Any strict quorum standards should be performed on the replica set.
- sloppy quorum: Instead of enforcing the quorum requirement, the system chooses the first W healthy servers for writes and first R healthy servers for reads on the hash ring. Offline servers are ignored.
- hinted handoff: If a server is unavailable due to network or server failures, another server will process requests temporarily. When the down server is up, changes will be pushed back to achieve data consistency.
- permanent failure handling
- anti-entropy protocol: Merkle tree
- check the detailed structure of Merkle tree if needed
- Merkle tree is used for inconsistency detection and minimizing the amount of data transferred
- Failure detection: gossip protocol
- System architecture diagram
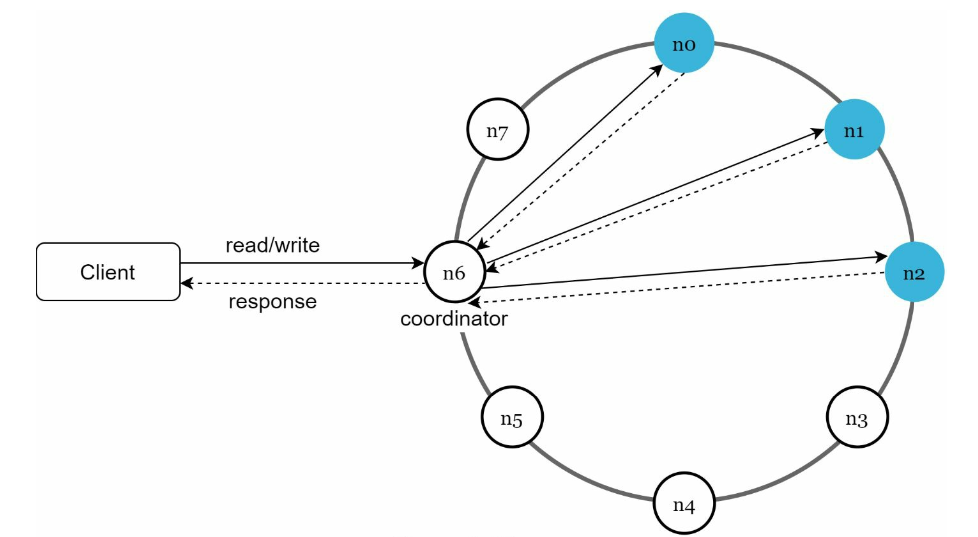
- Clients communicate with the key-value store through simple APIs: get(key) and put(key, value).
- A coordinator is a node that acts as a proxy between the client and the key-value store.
- Nodes are distributed on a ring using consistent hashing.
- The system is completely decentralized so adding and moving nodes can be automatic.
- Data is replicated at multiple nodes.
- There is no single point of failure as every node has the same set of responsibilities.
- Write path
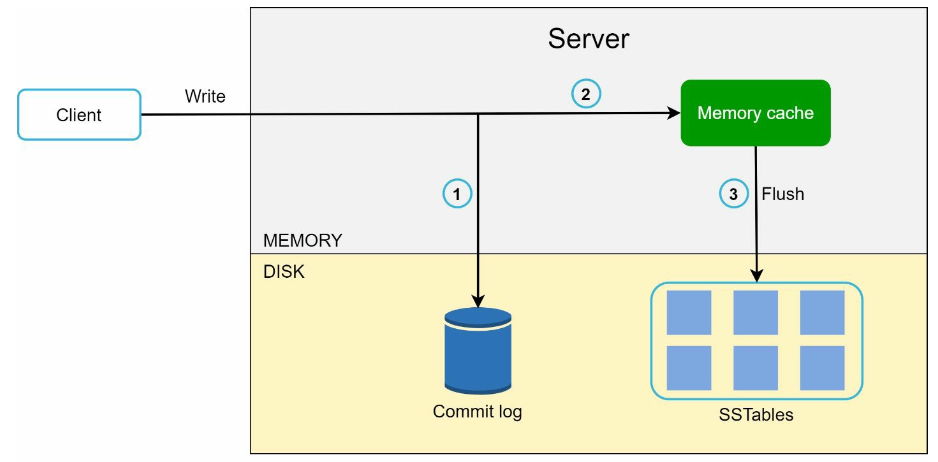
- write request is persisted on a commit log file
- Data is saved in the memory cache
- When the memory cache is full or reaches a predefined threshold, data is flushed to SSTable on disk
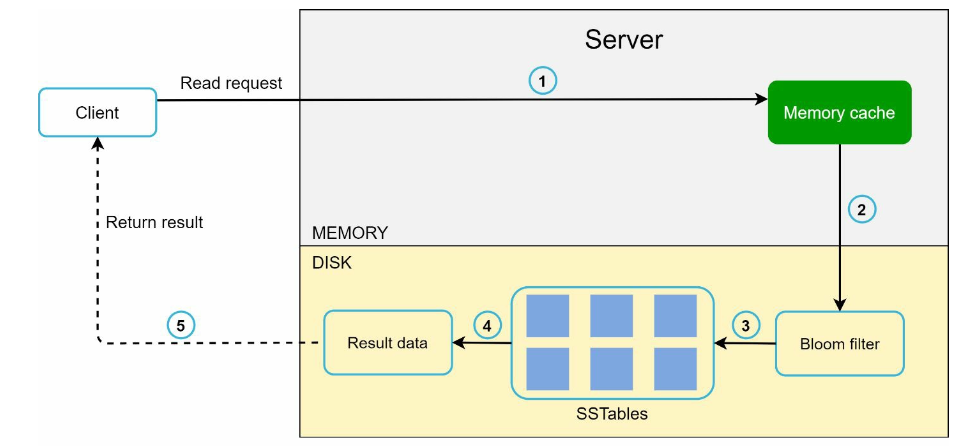
- Read path
Unique ID Generator
Requirements
- IDs must be unique.
- IDs are numerical values only.
- IDs fit into 64-bit.
- IDs are ordered by date.
- Ability to generate over 10,000 unique IDs per second.
Probable solutions
Multi-master replication
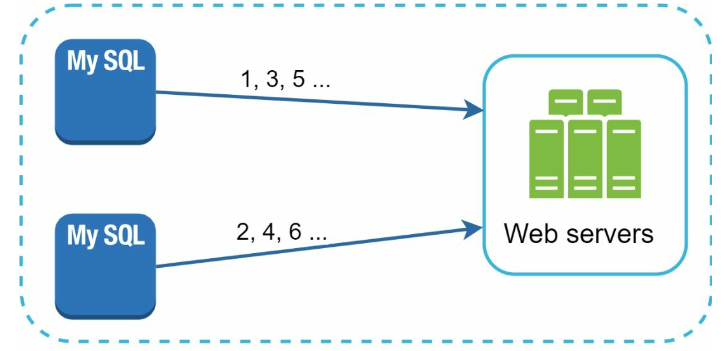
- uses the databases’ auto_increment feature
-
increase it by k, where k is the number of database servers in use
- Hard to scale with multiple data centers
- IDs do not go up with time across multiple servers.
- It does not scale well when a server is added or removed.
UUID
-
let each web server contain an UUID generator
- Pros:
- Generating UUID is simple. No coordination between servers is needed so there will not be any synchronization issues.
- The system is easy to scale because each web server is responsible for generating IDs they consume. ID generator can easily scale with web servers.
- Cons:
- IDs are 128 bits long, but our requirement is 64 bits.
- IDs do not go up with time.
- IDs could be non-numeric.
Ticket server
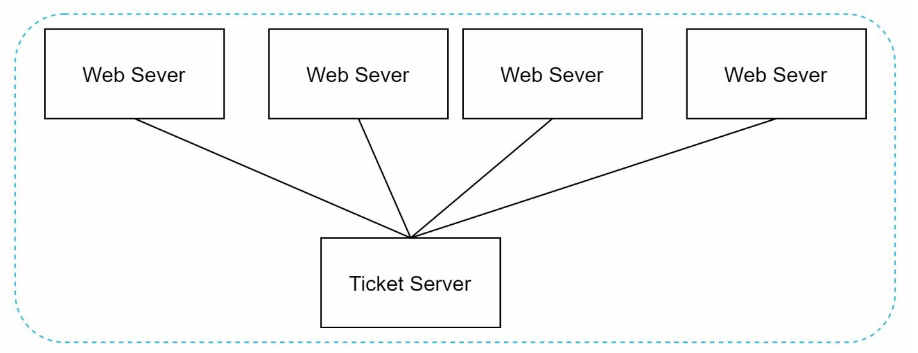
- Single point of failure.
Snowflake

- Sign bit: 1 bit. It will always be 0. This is reserved for future uses. It can potentially be used to distinguish between signed and unsigned numbers.
- Timestamp: 41 bits. Milliseconds since the epoch or custom epoch. We use Twitter snowflake default epoch 1288834974657, equivalent to Nov 04, 2010, 01:42:54 UTC.
- Datacenter ID: 5 bits, which gives us 2 ^ 5 = 32 datacenters.
- Machine ID: 5 bits, which gives us 2 ^ 5 = 32 machines per datacenter.
- Sequence number: 12 bits. For every ID generated on that machine/process, the sequence number is incremented by 1. The number is reset to 0 every millisecond.
Furhter problems
- Clock synchronization: Network Time Protocol (NTP)
- Section length tuning
- High availability
URL Shortener
API Design
- URL shortening: POST
- URL redirection: GET
Redirecting
changes the short URL to the long URL with 301 redirect
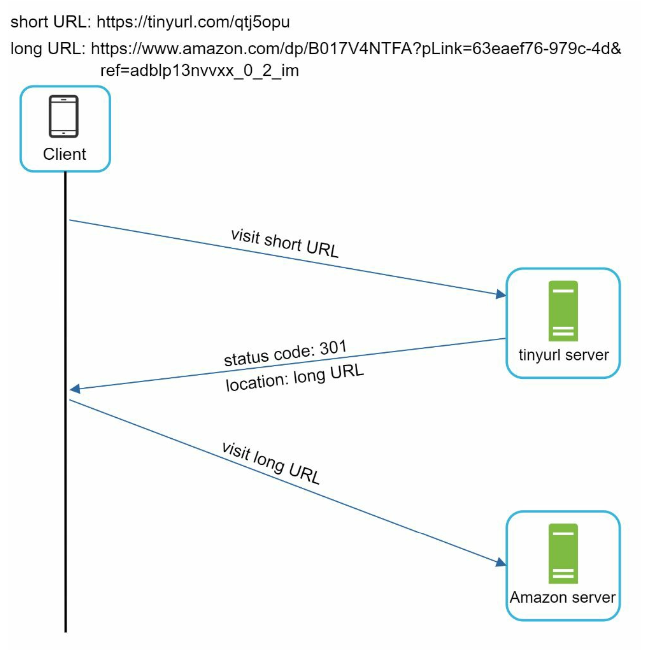
- 301 vs 302
- 301: permanent redirect, subsequent requests for the same URL will not be sent to the URL shortening service.
- 302: temporary redirect, subsequent requests for the same URL will be sent to the URL shortening service first.
- For server load considerations, 301 is preferred.
- For analytics, 302 is preferred.
Shortening
Using Hashing
- Each longURL must be hashed to one hashValue.
- Each hashValue can be mapped back to the longURL.
Using Database
- memory resources are limited and expensive
- relational database
Handle collisions
- most existing Hash functions produce too-long hash values
- shorten hash results might have collisions
- How to fix:
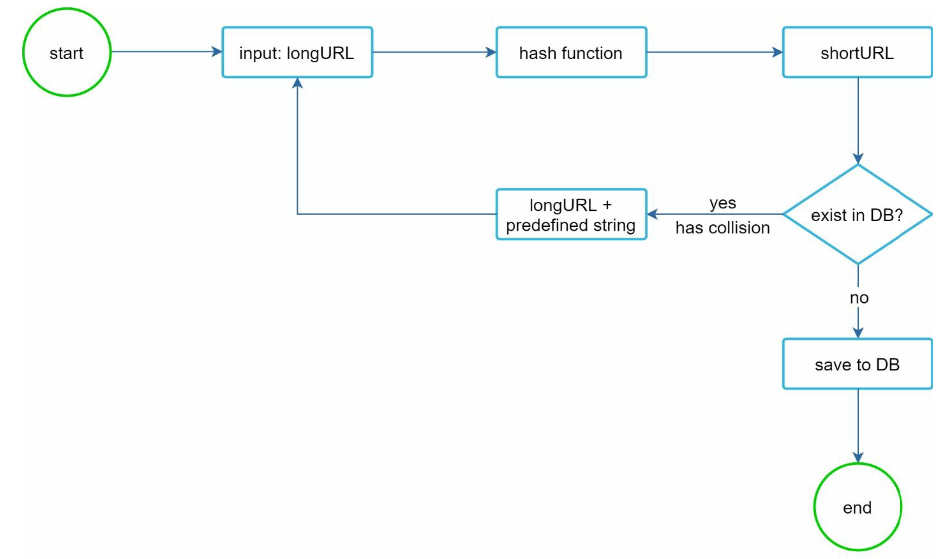
- frequently check the database for collisions can be expensive
- use bloom filters
Use Base62 conversion
- check the detailed explanation if not familiar with Base62 conversion
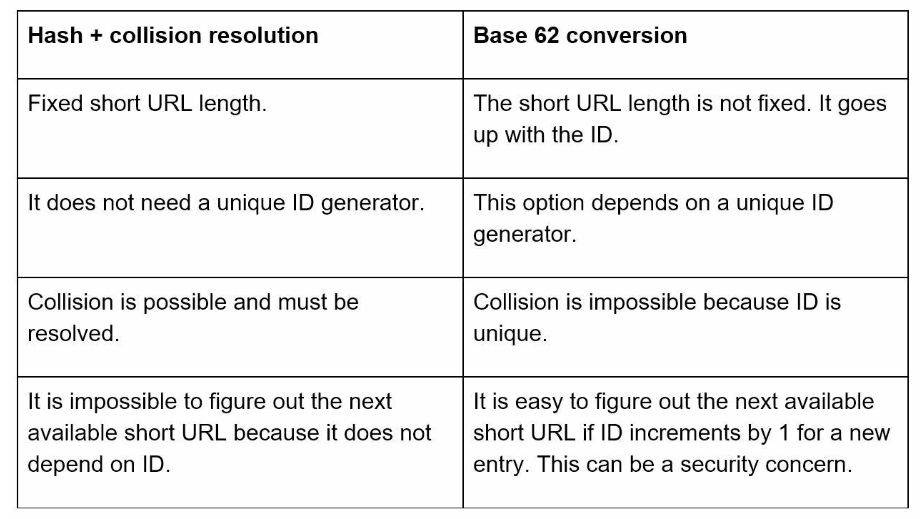
Possible process
- Assuming the input longURL is: https://en.wikipedia.org/wiki/Systems_design
- Unique ID generator returns ID: 2009215674938.
- Convert the ID to shortURL using the base 62 conversion. ID (2009215674938) is converted to “zn9edcu”.
- Save ID, shortURL, and longURL to the database
Web Crawler
Possible Requirements
- used for search engine indexing
- 1 billion pages per month
- HTML only
- ignore duplicate pages
- store page content up to 5 years
High-level design
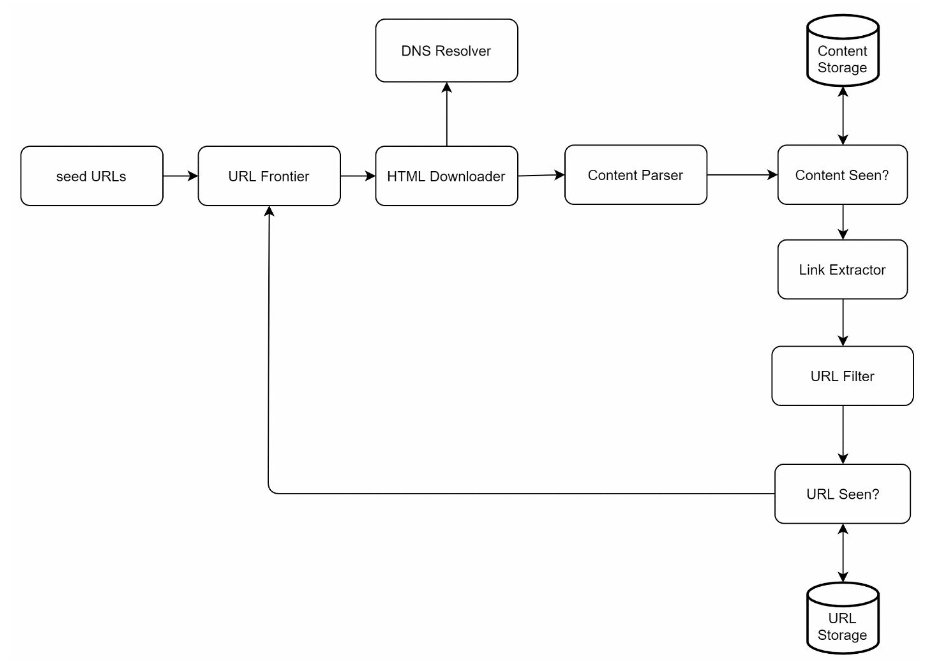
Pick Seed URLs
- use seed URLs as a starting point for the crawl process
- based on locality
- based on topics
URL Frontier
component that stores URLs to be downloaded is called the URL Frontier: FIFO
HTML Downloader
download web pages
DNS resolver
URL must be translated into an IP address before downloading
Content Parser
parse the content of the web page, seperate component from crawling process
Content Seen Detector
Using Hash values to compare the content of the web page
Content Storage
disk + memory
URL Extractor
URL filter
URL Seen Detector
Bloom filter / Hash table
Way of Traverse
- BFS with FIFO
- Most links from the same web page are linked back to the same host. If download web pages in parallel, servers will be flooded with requests. This is considered as “impolite”.
- Standard BFS does not take the priority of a URL into consideration. Might need to prioritize URLs according to their page ranks, web traffic, update frequency, etc.
URL Frontier
A URL frontier is a data structure that stores URLs to be downloaded.
ensure politeness, URL prioritization, and freshness
- Politeness: avoid sending too many requests to the same host
- A delay can be added between two download tasks
- maintain a mapping from website hostnames to download (worker) threads
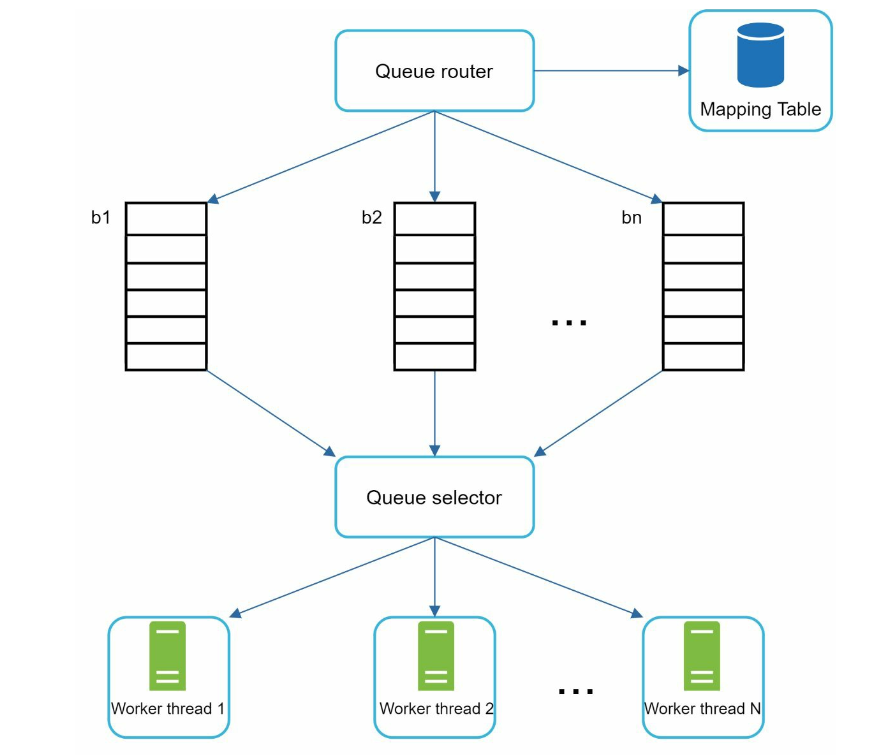
- Queue router: It ensures that each queue (b1, b2, … bn) only contains URLs from the same host.
- Mapping table: It maps each host to a queue.
- FIFO queues b1, b2 to bn: Each queue contains URLs from the same host.
- Queue selector: Each worker thread is mapped to a FIFO queue, and it only downloads URLs from that queue. The queue selection logic is done by the Queue selector.
- Worker thread 1 to N. A worker thread downloads web pages one by one from the same host. A delay can be added between two download tasks.
- Priority:
- PageRank, website traffic, update frequency
- Prioritizer: It takes URLs as input and computes the priorities
- Queue selector: Randomly choose a queue with a bias towards queues with higher priority
- Queues with high priority are selected with higher probability
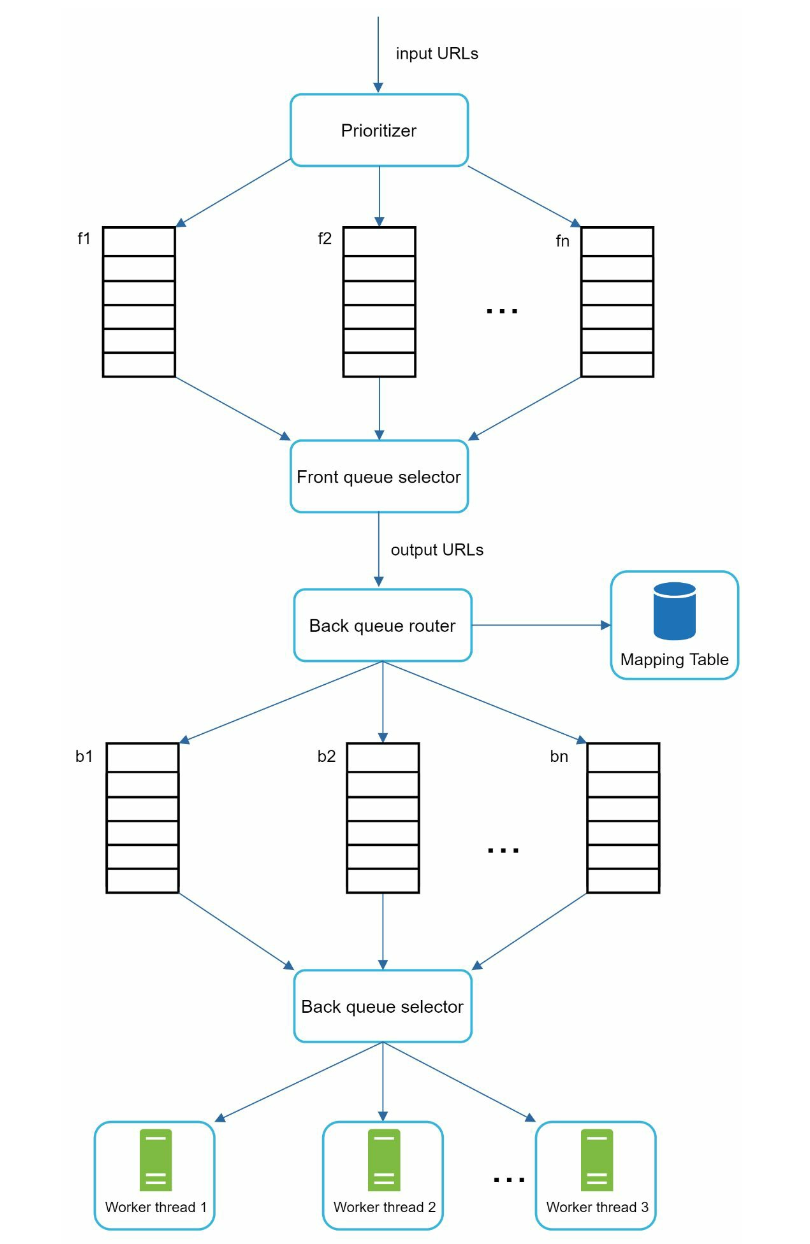
- Freshness:
- Recrawl based on web pages’ update history.
- Prioritize URLs and recrawl important pages first and more frequently.
HTML Downloader
Robots Exclusion Protocol
- robots.txt: standard used by websites to communicate with crawlers
- Before attempting to crawl a web site, a crawler should check its corresponding robots.txt first and follow its rules.
Performance optimization
- Distributed crawl: crawl jobs are distributed into multiple servers, URL space is partitioned into smaller pieces
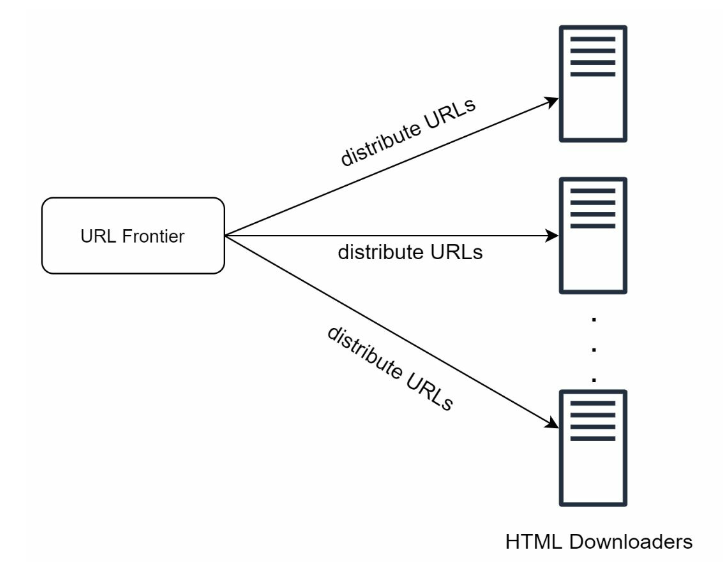
- Cache DNS Resolver
- Once a request to DNS is carried out by a crawler thread, other threads are blocked until the first request is completed.
- Maintaining our DNS cache to avoid calling DNS frequently is an effective technique for speed optimization.
- Our DNS cache keeps the domain name to IP address mapping and is updated periodically by cron jobs.
- Locality
- Distribute crawl servers geographically.
- When crawl servers are closer to website hosts, crawlers experience faster download time.
- Short timeout
- a maximal wait time is specified
Extensibility
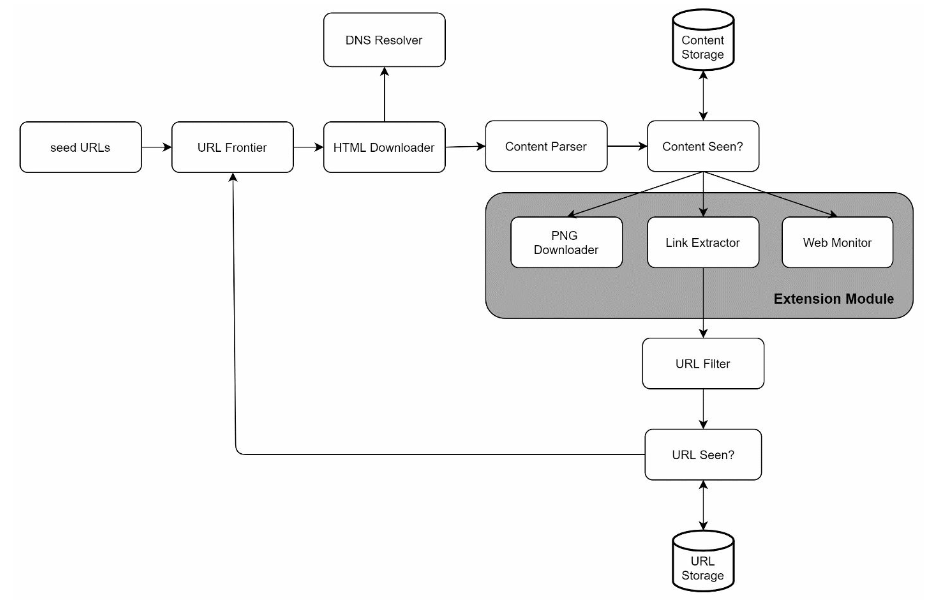
- PNG Downloader module is plugged-in to download PNG files.
- Web Monitor module is added to monitor the web and prevent copyright and trademark infringements.
Notification System
Main Components
- Different types of notifications
- Contact info gathering flow
- Notification sending/receiving flow
iOS push notification
- provider
- Device token: a unique identifier for the device
- Payload: a JSON dictionary that contains a notification’s payload.
- APNs
- iOS device
Android push notification
Instead of using APNs, Firebase Cloud Messaging (FCM) is commonly used to send push notifications to android devices.
SMS message
Third-party SMS services:
- Twilio
- Nexmo
Third-party email services:
- SendGrid
- Amazon SES
Contact info gathering flow
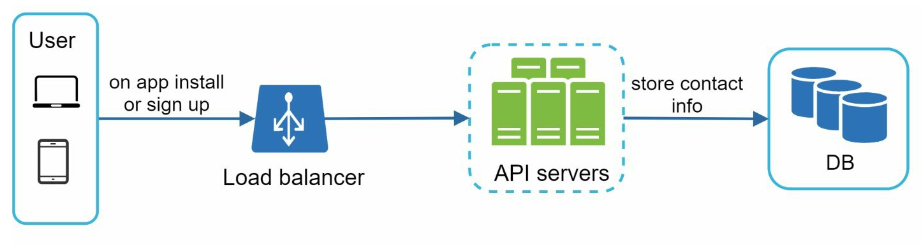
- for relational database, use user table, user_id as primary key, and device table, user_id as foreign key
- a user can have multiple devices
Notification sending flow
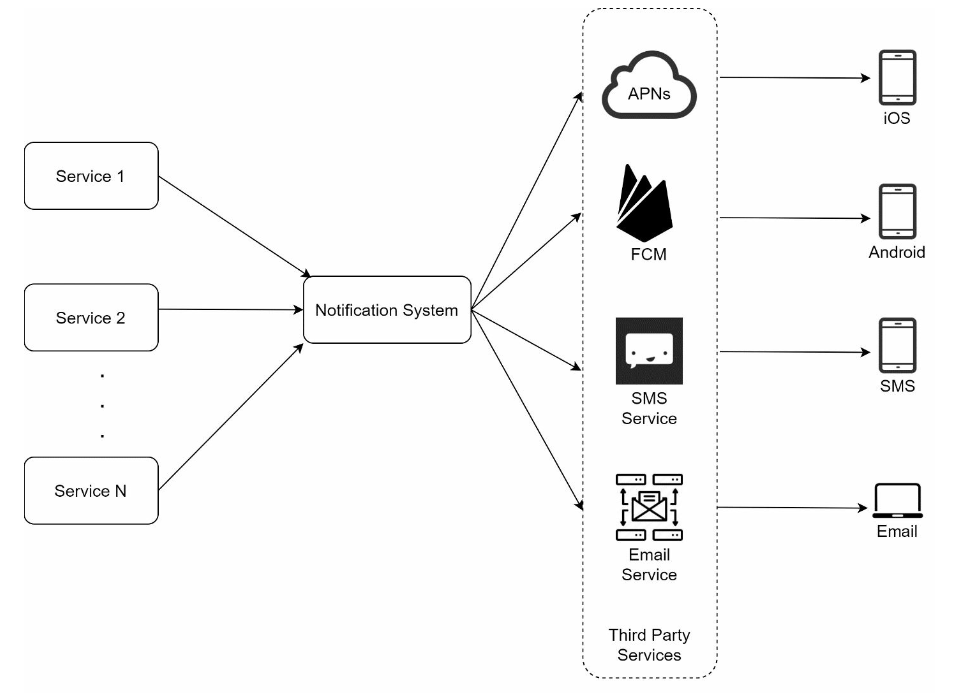
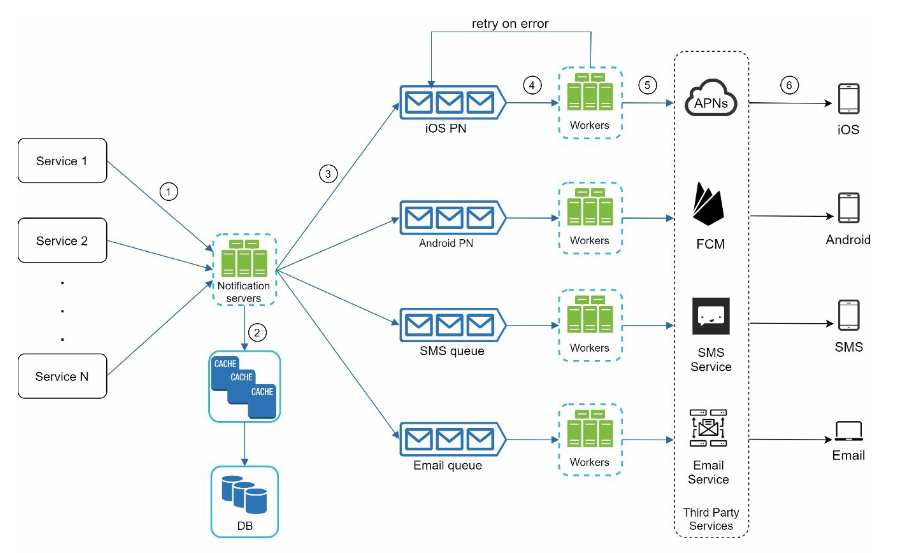
- service: a micro-service, a cron job, or a distributed system that triggers notification sending events
- Notification system
- provides APIs
- basic validation of contact info
- send notifications to message queues
- Query the database or cache to fetch data needed to render a notification
- Third-party services
- extensibility matters
- service availability problems
- Cache & Database: User info, device info, notification templates, Settings
- Message queues: decouple & buffer
- Worker: simple logic, send notifications
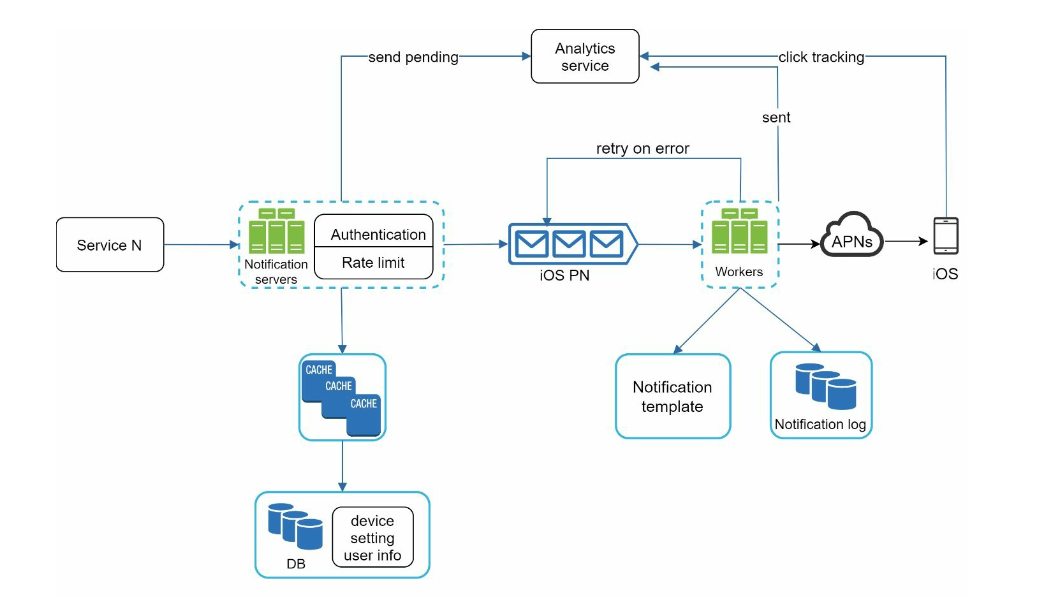
Reliability
- notification should be never-lost
- database persistence: workers can hold notification log database
- retry mechanism
- exactly-once: can’t ensure exactly-once delivery
- dedupe mechanism: use Event ID to ensure idempotency
Addtional considerations
- template reusing
- notification settings
- give users fine-grained control over notification settings
- use setting table to store user settings
- rate limiting
- retry mechanism
- security
- appKey
- appSecret
- monitor queue
- total number of queued notifications should be controlled
- Event tracking
- “bury the point”
News Feed System
requirements
- user can publish a post and see her friends’ posts on the news feed page
- feed is sorted mainly by reverse chronological order
- 10 million DAU
- contain media files, including both images and videos
high-level design
- Feed publishing: a user publishes a post, corresponding data is written into cache and database. A post is populated to her friends’ news feed.
- Newsfeed building: assume the news feed is built by aggregating friends’ posts in reverse chronological order.
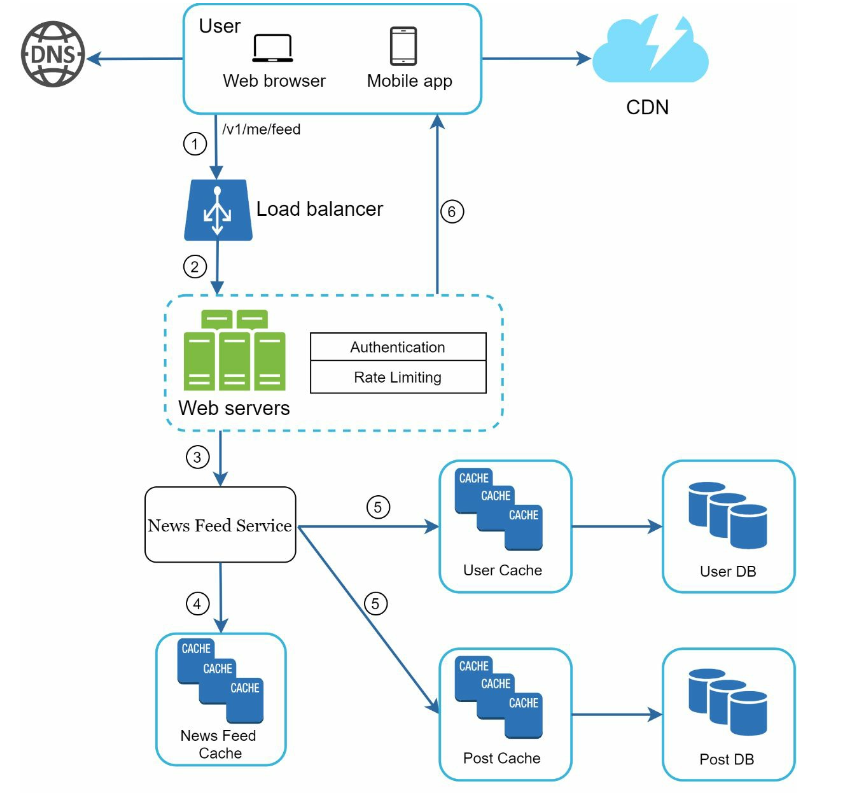
Feed publishing
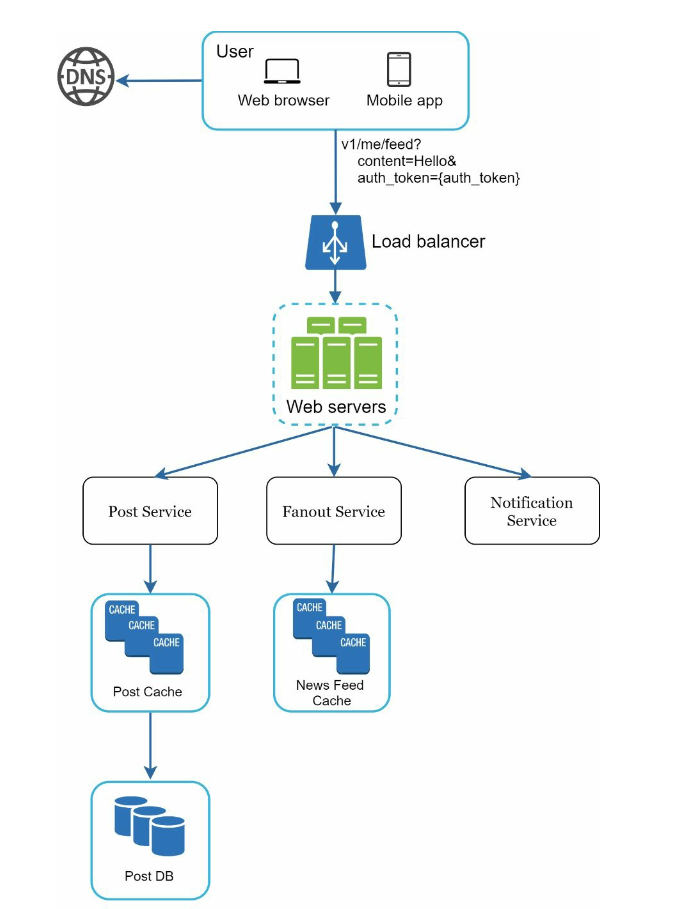
- Post service: persist post in the database and cache.
- Fanout service: push new content to friends’ news feed. Newsfeed data is stored in the cache for fast retrieval.
- Notification service: inform friends that new content is available and send out push notifications.
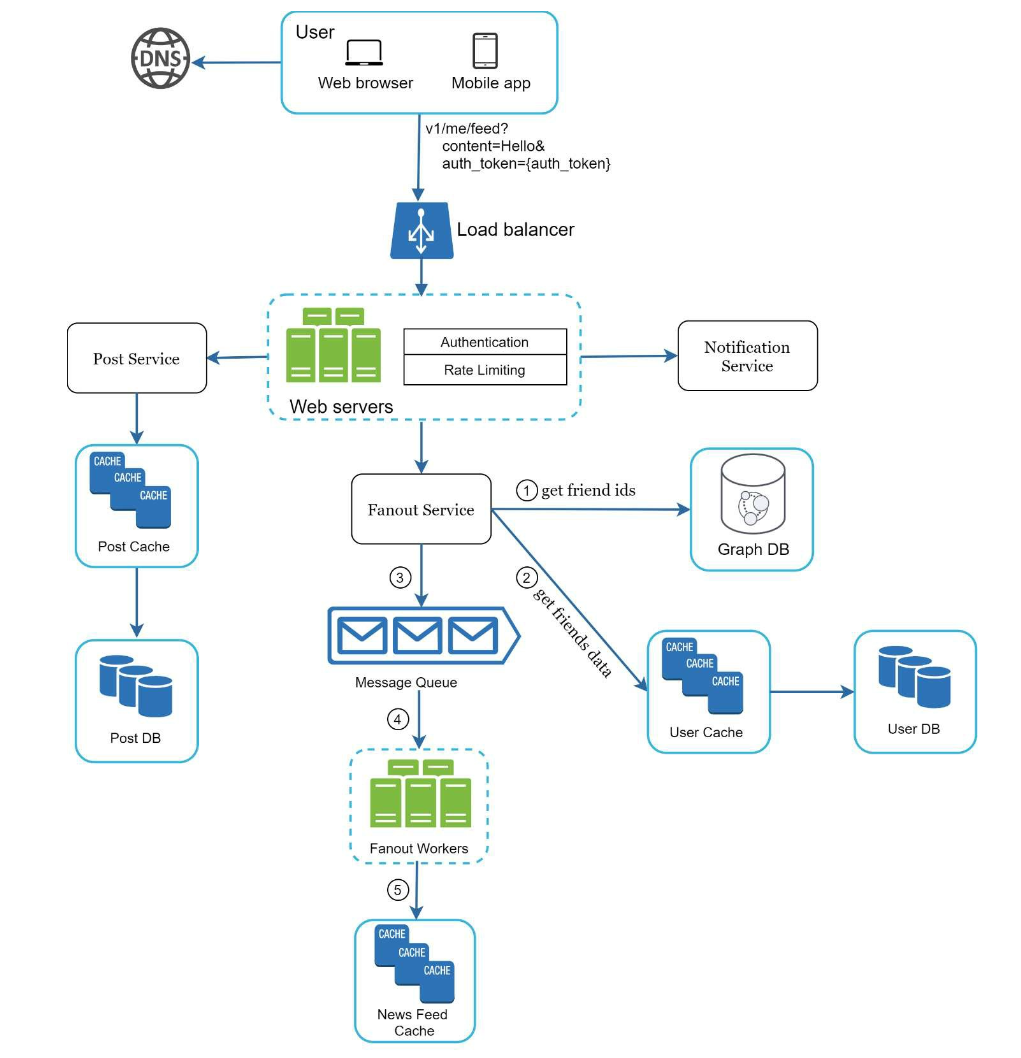
- fanout service
- fanout on write (also called push model): A new post is delivered to friends’ cache immediately after it is published
- Pros:
- news feed is generated in real-time and can be pushed to friends immediately
- Fetching news feed is fast
- Cons:
- hotkey problem: a user has a large number of friends, fetching the friend list and generating news feeds for all of them are slow and time consuming
- For inactive users or those rarely log in, pre-computing news feeds waste computing resources
- Pros:
- fanout on read (also called pull model): The news feed is generated during read time. This is an on-demand model.
- Pros:
- For inactive users or those who rarely log in, fanout on read works better because it will not waste computing resources on them
- Data is not pushed to friends so there is no hotkey problem
- Cons:
- Fetching the news feed is slow as the news feed is not pre-computed
- Pros:
- Pratical Solution: Hybrid model
- push model for the majority of users
- pull model for celebrity users or those with a large number of friends
- Consistent hashing is a useful technique to mitigate the hotkey problem as it helps to distribute requests/data more evenly
- fanout on write (also called push model): A new post is delivered to friends’ cache immediately after it is published
Newsfeed building
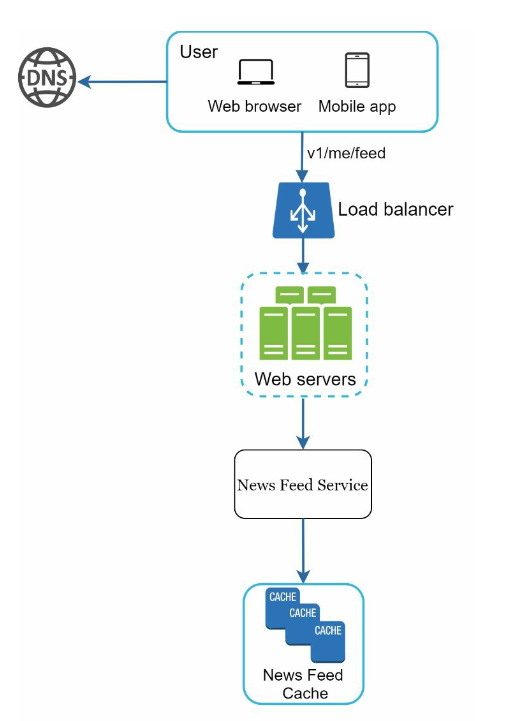
- Newsfeed service: news feed service fetches news feed from the cache.
- Newsfeed cache: store news feed IDs needed to render the news feed.
Newsfeed cache
like <post_id, user_id> mapping table
CHAT SYSTEM
Requirements
- support both 1 on 1 and group chat
- support 50 million daily active users (DAU)
- group member limit: maximum of 100 people
- only supports text messages
- text length should be less than 100,000 characters long
- chat history persistence
- Multiple device support
High-level design
Use basic client-server architecture:
- Server
- receives messages
- relays messages to the intended recipients
- store if not online
choice of network protocols
- Sender side
Uses HTTP to initially send messages to the server.
- use keep-alive header
- maintain a persistent connection
- reduces the number of TCP handshakes
- Receiver side
- Polling: Client periodically asks the server if there are any new messages.
- costly
- consume server resources and bandwidth
- Long polling: a client holds the connection open until there are actually new messages available or a timeout threshold has been reached
- Sender and receiver may not connect to the same chat server. HTTP based servers are usually stateless. If you use round robin for load balancing, the server that receives the message might not have a long-polling connection with the client who receives the message.
- A server has no good way to tell if a client is disconnected.
- It is inefficient. If a user does not chat much, long polling still makes periodic connections after timeouts
- WebSocket: bi-directional and persistent, port 80 or 443
- starts its life as a HTTP connection and could be “upgraded” via some well-defined handshake to a WebSocket connection
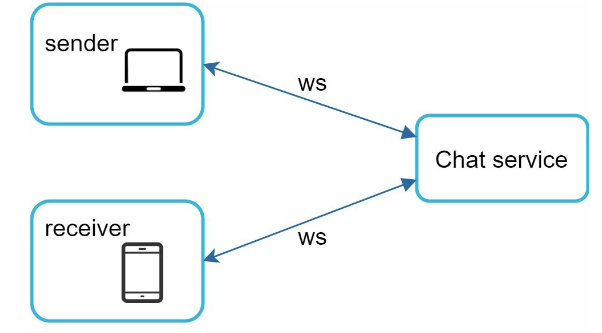
General Design
Note: everything else does not have to be WebSocket (sign up, login, user profile, etc)
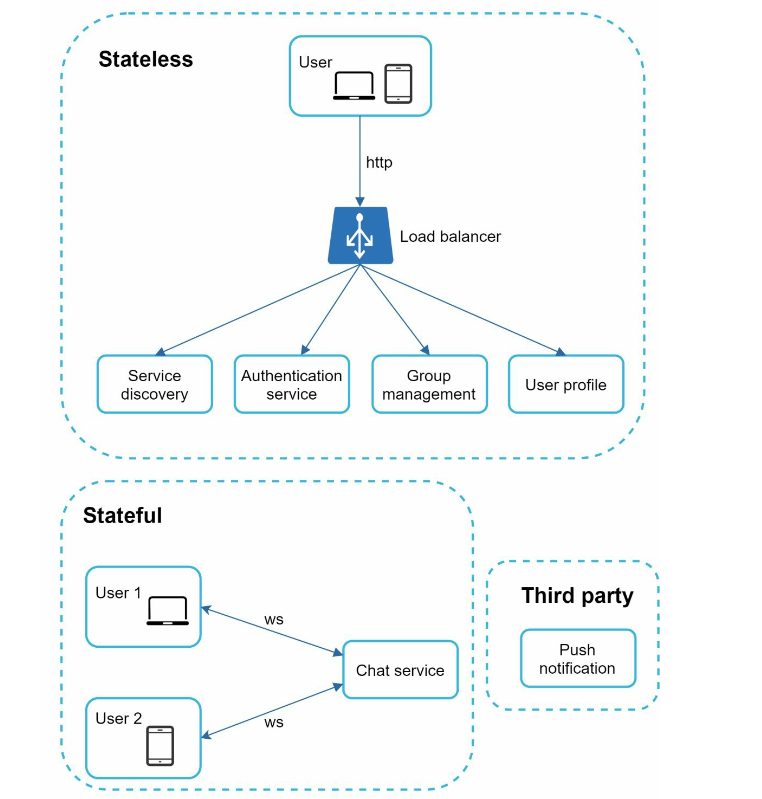
- service discovery: give the client a list of DNS host names of chat servers that the client could connect to
- chat service: only stateful service
- stateful because each client maintains a persistent network connection to a chat server
adjusted version without single-server problem:
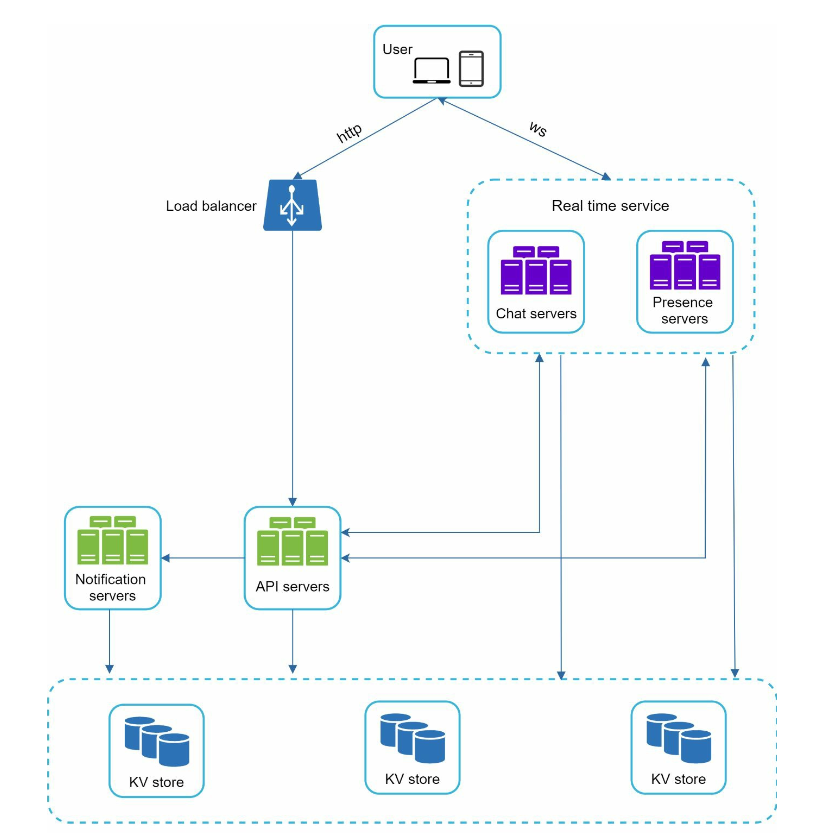
- chat servers: message sending/receiving
- presence servers: online/offline status
- API servers: everything stateless
- user login, signup, change profile, etc
- KV store: chat history, for scenarios like offline user comes online
Storage
Relational or NOSQL database?
- check data types
- generic data: user profile, setting, user friends list
- relational database
- chat history data:
- enormous
- only recent data is frequently accessed
- users might use features require random access (search, view your mentions, jump to specific messages)
- Read Write Ratio (R/W) is 1:1 for 1 on 1 chat
- Use KV store for chat history
- easy horizontal scaling
- very low latency to access data
- Relational databases do not handle long tail of data well
- Most existing services use KV store for chat history
- generic data: user profile, setting, user friends list
Data Model


explanation about message ID:
- IDs must be unique
- IDs should be sortable by time, meaning new rows have higher IDs than old ones
approach:
- global ID generation: snowflake
- local sequence number generator: because maintaining message sequence within one-on-one channel or a group channel is sufficient
Deep Dive
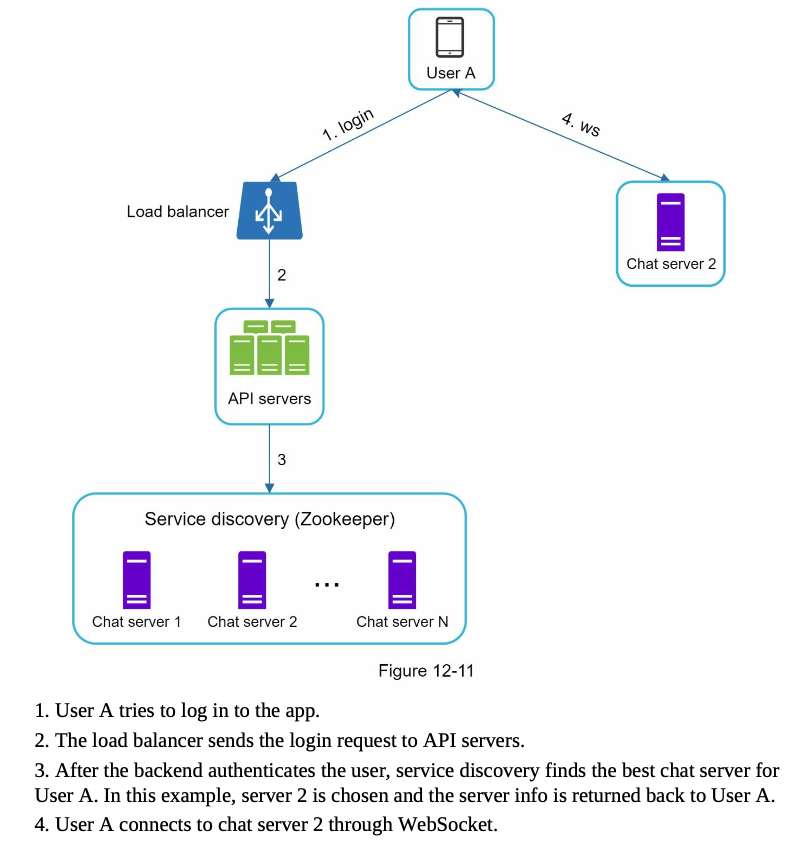
Service discovery
recommend the best chat server for a client
- Apache Zookeeper
- use znodes to store chat server IP addresses
- each chat server registers its IP address to Zookeeper
- check more details about zookeeper in Common Sense for Distributed System
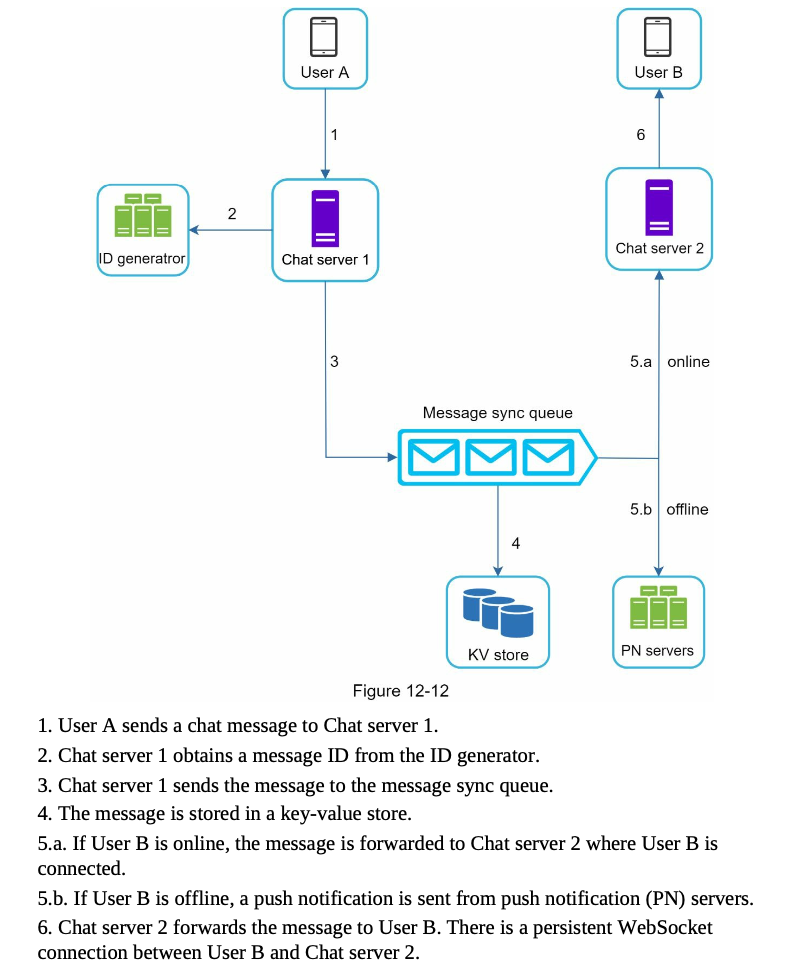
Message flows
Message synchronization across multiple devices
each device keeps track of the last message ID it has received
fetch messages with IDs greater than the last message ID from KV store through chat server
small group chat flow
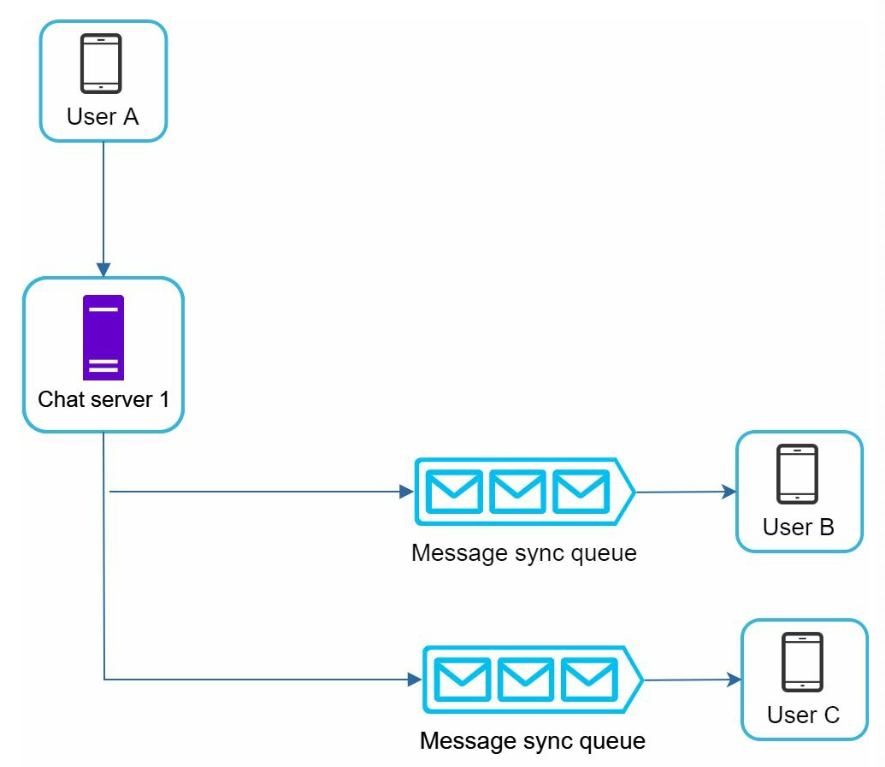
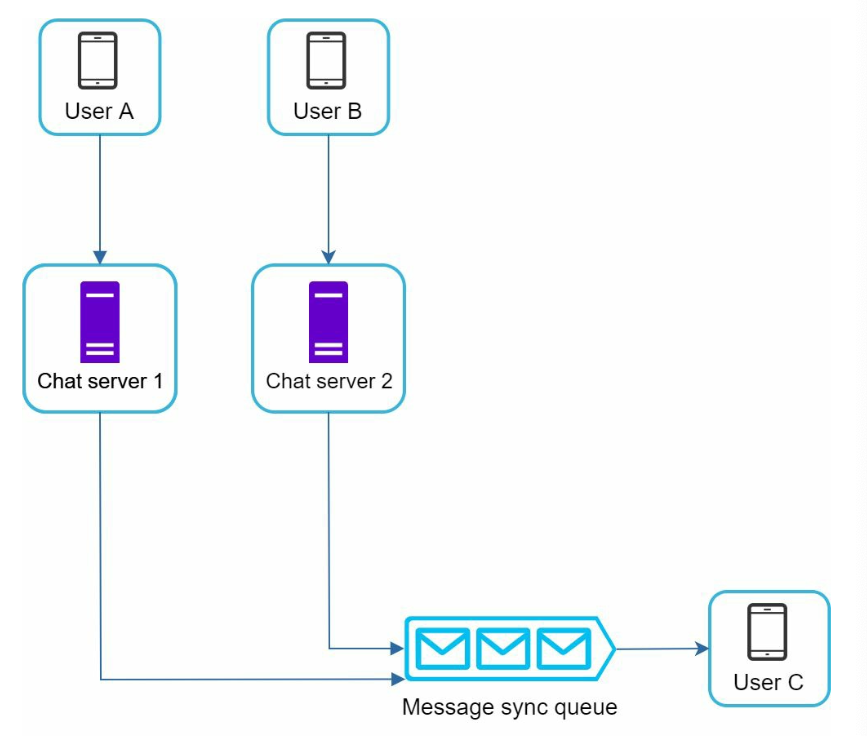
- message from User A is copied to each group member’s message sync queue
- simplifies message sync flow as each client only needs to check its own inbox
- group number is small, storing a copy in each recipient’s inbox is not too expensive
- for groups with a lot of users, storing a message copy for each member is not acceptable
- Each recipient has an inbox (message sync queue) which contains messages from different senders.
Online presence
presence server: managing online status and communicating with clients through WebSocket
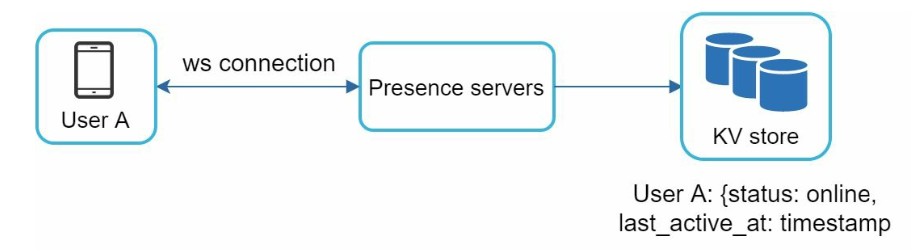

- User login
- After a WebSocket connection is built between the client and the real-time service
- save online status and timestamp
- User logout
- User disconnection
- Updating online status on every disconnect/reconnect would make the presence indicator change too often because of the unstable network connection
- use heartbeat instead: from client to server
- alike low-pass filter
- Online status fanout
- publish-subscribe model
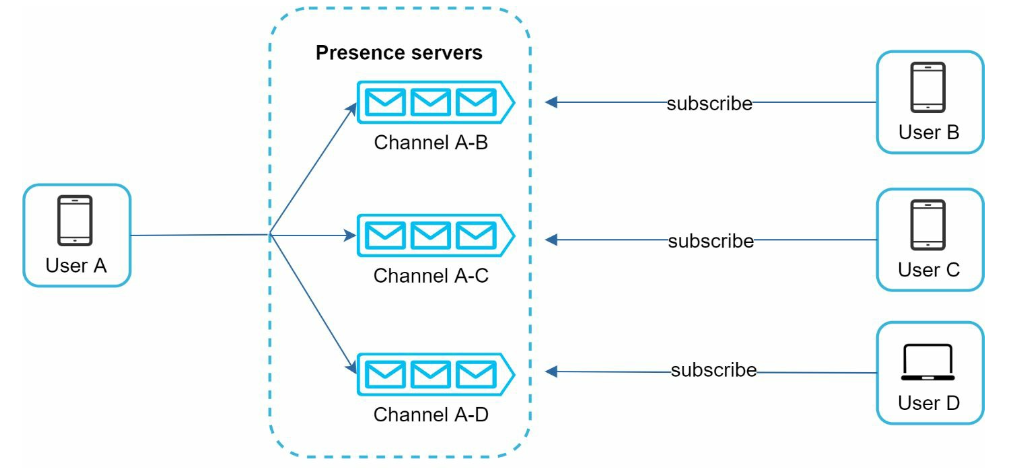
- The communication between clients and servers is through real-time WebSocket
SEARCH AUTOCOMPLETE SYSTEM
search autocomplete system / design top k / design top k most searched queries
Basic Requirements
- matching only supported at the beginning of the query
- 5 suggestions determined by popularity
- no spell check or correction
- suppose all queries are lowercase alphabetic characters
- 10 million DAU
- Fast response time
- relevant results
- Scalable: handle high traffic
High-level design
- Data gethering: gathers user input queries and aggregates them in real-time ( not pratical for large data set )
- Query Service: Given a search query or prefix, return 5 most frequently searched terms
Deep Dive
Trie / prefix tree
check the detailed explanation if not familiar with Trie
leetcode: 208 Implement Trie (Prefix Tree)
- a trie example with frequency count in leaf nodes:
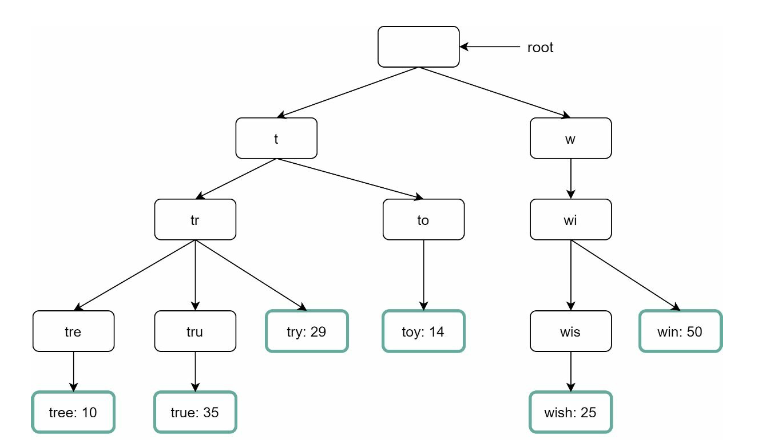
time complecity for get top k most frequent queries:
O(p) + O(c) + O(clogc)
O(p): find the prefixO(c): c is the number of children of the prefix node, Traverse the subtree from the prefix node to get all valid childrenO(c * log(c)): sort the children and get top k
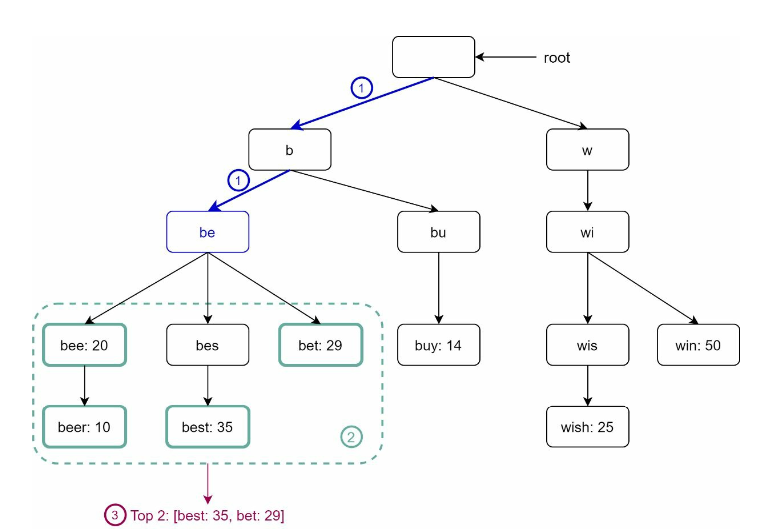
- Step 1: Find the prefix node “tr”.
- Step 2: Traverse the subtree to get all valid children. In this case, nodes [tree: 10], [true: 35], [try: 29] are valid.
- Step 3: Sort the children and get top 2. [true: 35] and [try: 29] are the top 2 queries with prefix “tr”.
problem: worst-scenario need to traverse the whole tree
optimization:
- Limit the max length of a prefix
- cache top search queries at each node
- each node keeps track of the top k most frequent queries
- example:
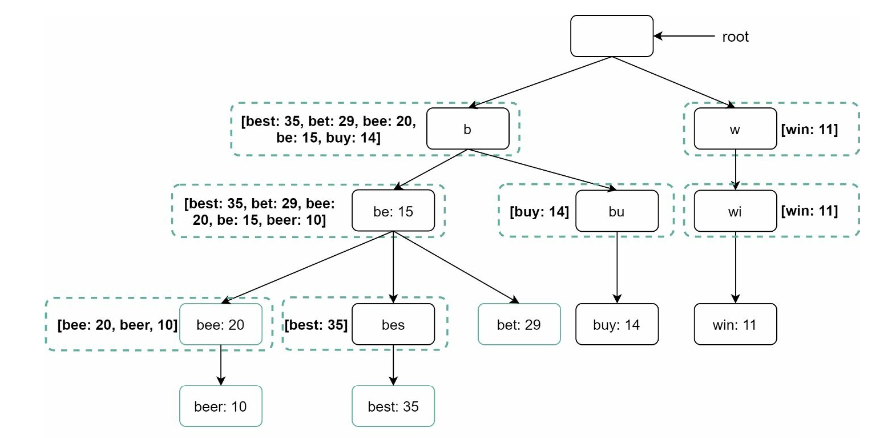
- time complexity:
O(1)
Data gathering
realtime data gathering is not pratical
- Users may enter billions of queries per day. Updating the trie on every query significantly slows down the query service.
- Top suggestions may not change much once the trie is built.
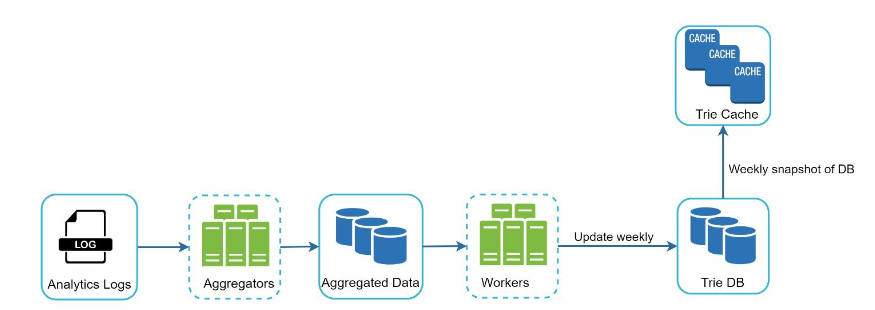
- Analytics Logs: stores raw data about search queries, append-only, not indexed
- Aggregators: aggregate search queries on the demand of real-time
- Aggregated data: queries with frequency count and timestamp
- Workers: build the trie data structure and store it in Trie DB asynchronously
- Trie Cache: distributed cache system that keeps trie in memory for fast read, takes weekly snapshots of Trie DB
- Trie DB: persistent storage for trie
- Document store: store the serialized snapshots of the trie periodically into database like MongoDB
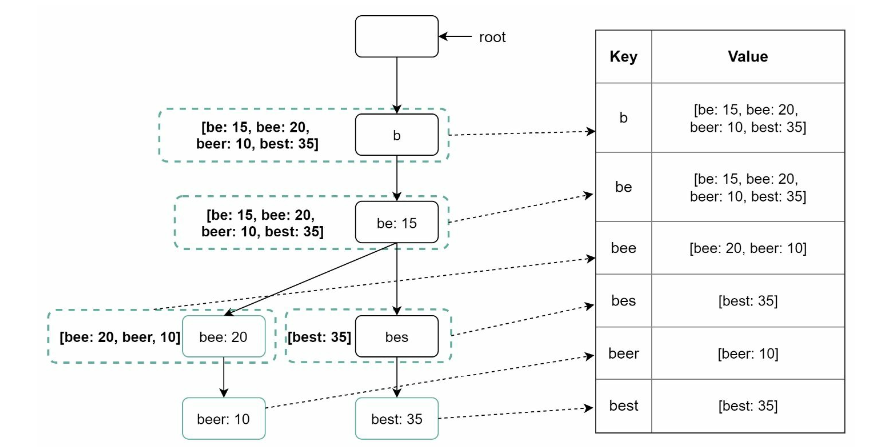
- KV store: transform the trie into a hash table form:
Query Service
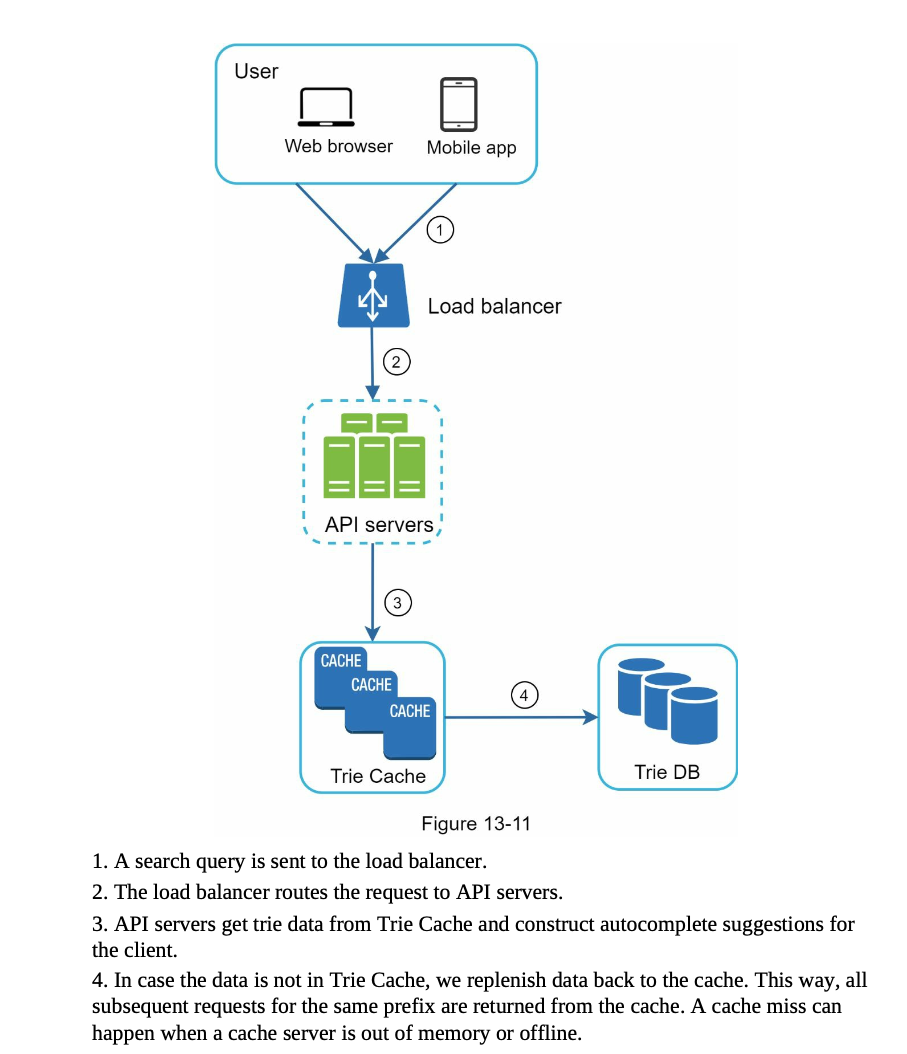
- use ajax to send request that won’t refresh the page
- use browser cache to store autocomplete suggestions (with cache-control header: max-age, private)
- data sampling: only sample a small percentage of queries
Trie Operation
- Update:
- Update the trie weekly. Replace the old trie with the new one.
- Update individual trie node directly. only do this when trie is relatively small. also don’t forget to update all the ancestors
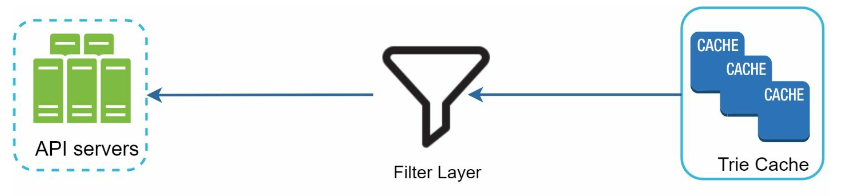
- Delete:
- add a filter layer in front of the Trie Cache to filter out unwanted suggestions.
- Unwanted suggestions are removed physically from the database asynchronically so the correct data set will be used to build trie in the next update cycle.
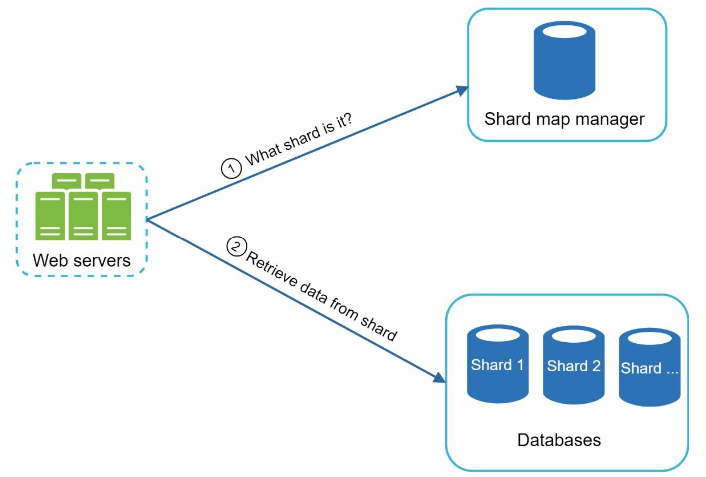
Scale the storage
Sharding problem: uneven distribution of words
- use a shard map manager to manage the shards: use a lookup database for storing trie
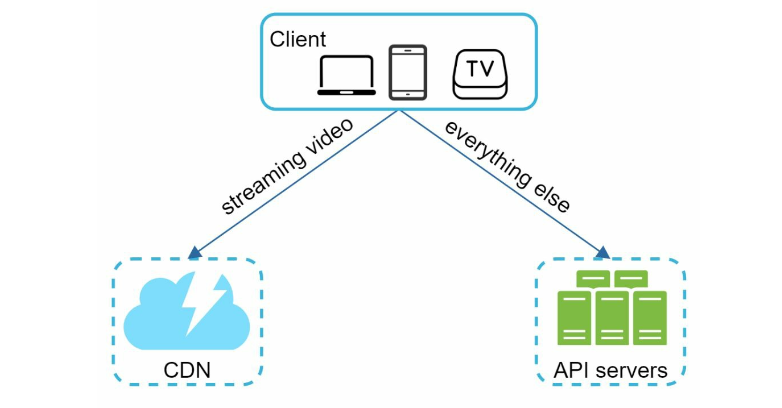
Further questions:
- multiple languages
- use unicode characters
- different search queries across regions
- build different tries and store in CDNs for response time
- real-time search queries
- Reduce the working data set by sharding
- Change the ranking model and assign more weight to recent search queries
- Stream processing data
DESIGN YOUTUBE / video sharing platform
Basic Requirements
- users can upload videos and watch videos
- 5 million DAU
- average daily spent time: 30 minutes
- international user support
- accepts most of video resolutions and formats
- encryption required
- maximum video size: 1 GB
-
utilize existing cloud service
- Ability to upload videos fast
- Smooth video streaming
- Ability to change video quality
- Low infrastructure cost
- High availability, scalability, and reliability requirements
- Clients supported: mobile apps, web browser, and smart TV
High-level design
- video uploading flow
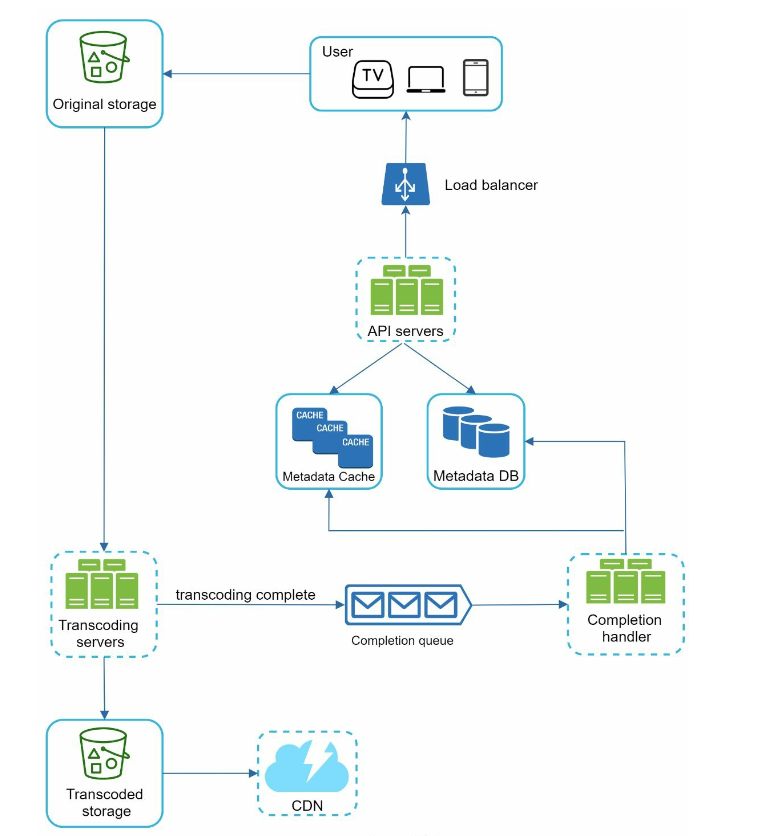
- Metadata DB: Video metadata are stored in Metadata DB.
- Metadata cache: For better performance, video metadata and user objects are cached
- Original storage: A blob storage system is used to store original videos.
- Transcoding servers: converting a video format to other formats (MPEG, HLS, etc), which provide the best video streams possible.
- Transcoded storage: It is a blob storage that stores transcoded video files
- CDN: Videos are cached in CDN.
- Completion queue: MQ that stores information about video transcoding completion events
- flow for upload actual video
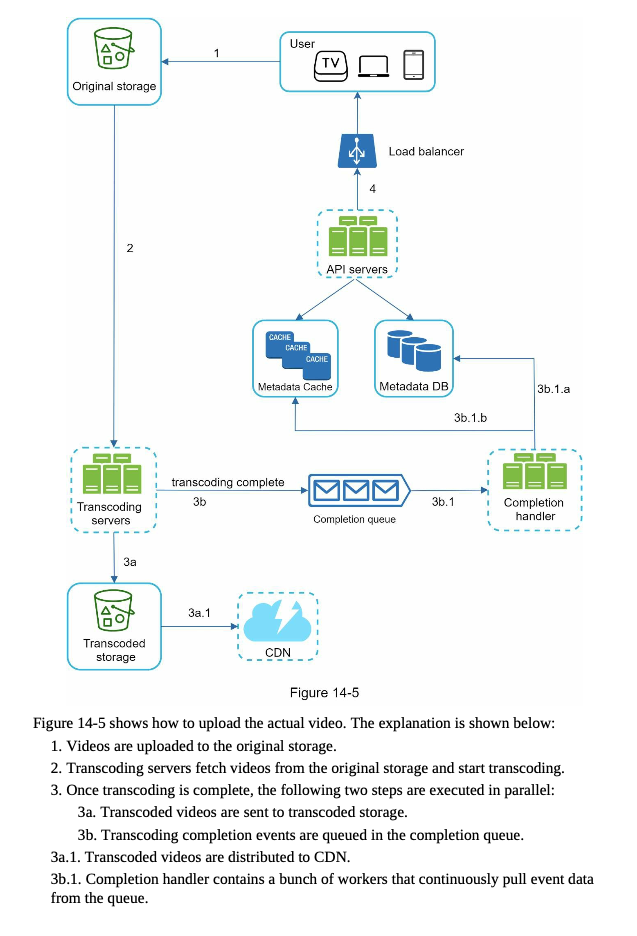
- API servers inform the client that the video is successfully uploaded and is ready for streaming
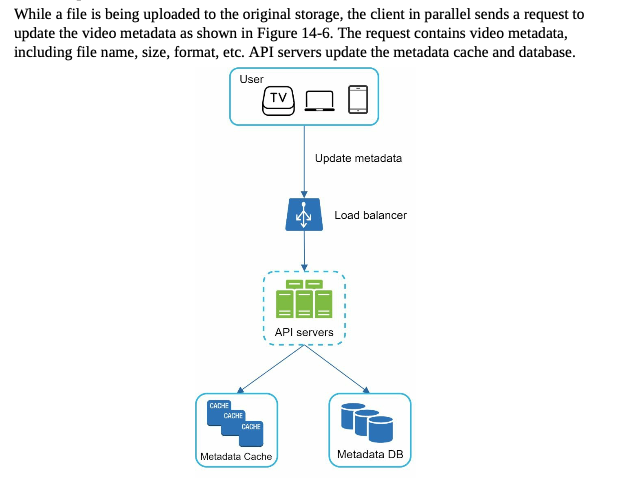
- update metadata
- Video streaming flow
- streaming protocols
- MPEG–DASH: Dynamic Adaptive Streaming over HTTP, Moving Picture Experts Group
- Apple HLS. HLS stands for “HTTP Live Streaming”
- Microsoft Smooth Streaming.
- Adobe HTTP Dynamic Streaming (HDS).
- Videos are streamed from CDN directly
- streaming protocols
Design deep dive
Video transcoding
- container: like a basket that contains the video file, audio, and metadata.
- codec: an algorithm that compresses and decompresses video and audio data, like H.264, VP9, etc.
- DAG model:
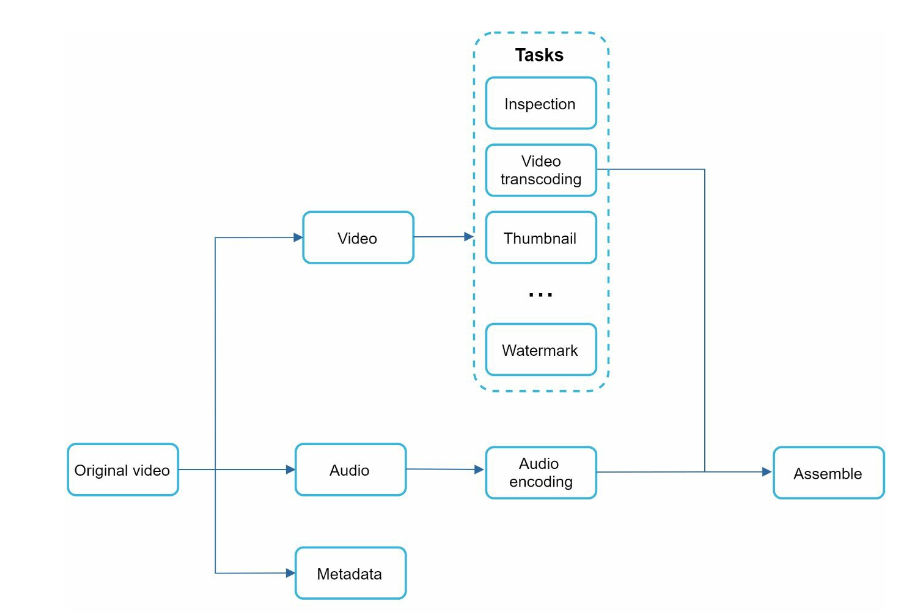
Video transcoding architecture
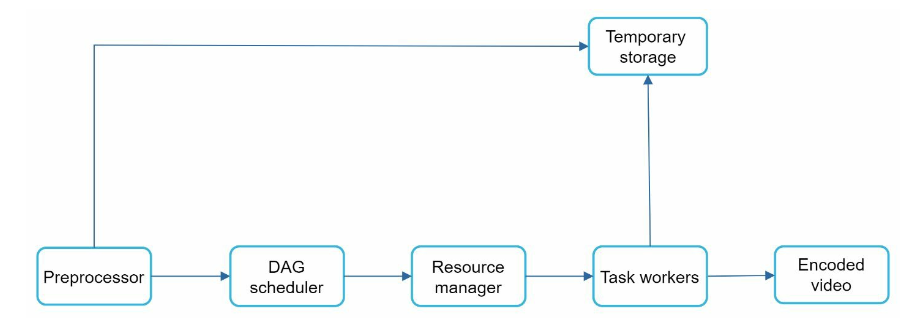
- preprocessor:
- Video splitting: Video stream is split or further split into smaller Group of Pictures (GOP) alignment. GOP is a group/chunk of frames arranged in a specific order. Each chunk is an independently playable unit, usually a few seconds in length.
- Some old mobile devices or browsers might not support video splitting. Preprocessor should ensure GOP alignment for old clients.
- DAG generation, processor generates DAG based on configuration files client programmers write.
- cache data: preprocessor is a cache for segmented videos, preprocessor stores GOPs and metadata in temporary storage. If video encoding fails, the system could use persisted data for retry operations.
- DAG Scheduler:
- DAG scheduler splits a DAG graph into stages of tasks and puts them in the task queue in the resource manager
- resource manager:
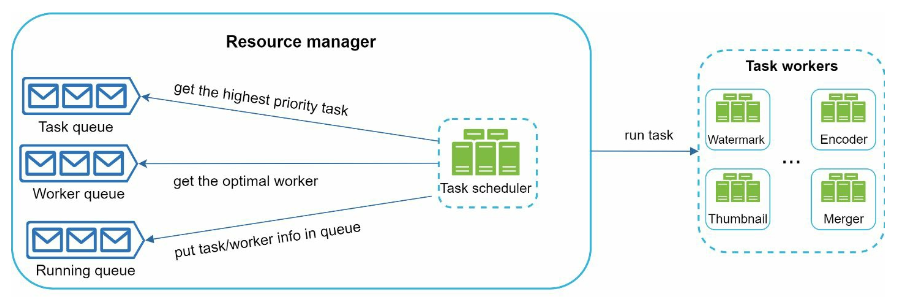
- Task queue: a priority queue contains tasks to be executed.
- Worker queue: a priority queue that contains worker utilization info.
- Running queue: It contains info about the currently running tasks and workers running the tasks
- Task scheduler: It picks the optimal task/worker, and instructs the chosen task worker to execute the job
- The resource manager works as follows:
- The task scheduler gets the highest priority task from the task queue.
- The task scheduler gets the optimal task worker to run the task from the worker queue.
- The task scheduler instructs the chosen task worker to run the task.
- The task scheduler binds the task/worker info and puts it in the running queue.
- The task scheduler removes the job from the running queue once the job is done.
- Task workers
- Task workers run the tasks which are defined in the DAG
- Temporary Storage
- Data in temporary storage is freed up once the corresponding video processing is complete.
Optimization
Speed optimization:
- parallelize video uploading
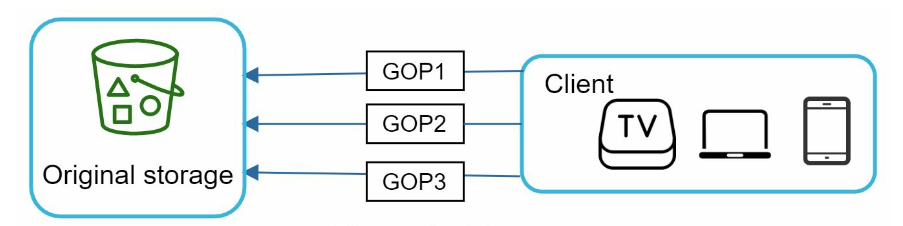
- split a video into smaller chunks by GOP alignment
- allows fast resumable uploads when the previous upload failed
- speed up the upload process by uploading multiple chunks in parallel
- place upload centers close to users
- setting up multiple upload centers across the globe
- parallelism everywhere
- make the system more loosely coupled: introduce message queues
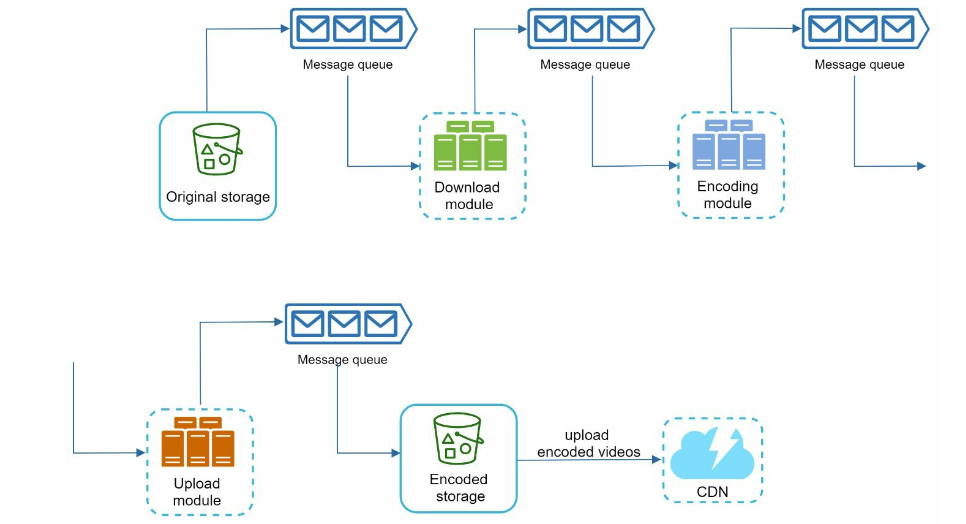
- parallelization for each step in the whole process
- make the system more loosely coupled: introduce message queues
Safety optimization
- use pre-signed URLs (this name is from AWS S3)
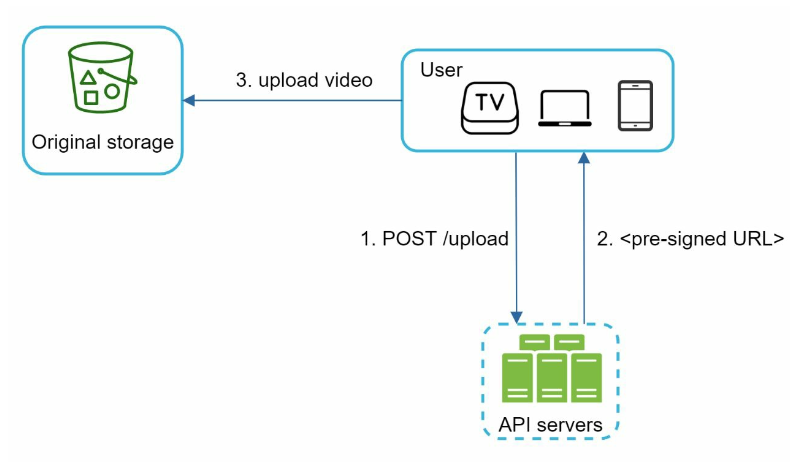
- pre-signed URL gives the access permission to the object identified in the URL
- protect videos copyright
- DRM (Digital Rights Management): Apple FairPlay, Google Widevine, Microsoft PlayReady
- AES encryption: encrypt a video and configure an authorization policy. The encrypted video will be decrypted upon playback.
- Visual watermarking
Cost-saving optimization
- Only serve the most popular videos from CDN and other videos from our high capacity storage video servers
- For less popular content, we may not need to store many encoded video versions. Short videos can be encoded on-demand.
- Some videos are popular only in certain regions. There is no need to distribute these videos to other regions.
- Build your own CDN like Netflix and partner with Internet Service Providers (ISPs).
Error handling
- Recoverable error: retry the operation a few times, If the task continues to fail and the system believes it is not recoverable, it returns a proper error code to the client.
- Non-recoverable error: stops the running tasks associated with the video and returns the proper error code to the client
DESIGN GOOGLE DRIVE
Basic Requirements
- Add files. The easiest way to add a file is to drag and drop a file into Google drive.
- Download files.
- Sync files across multiple devices. When a file is added to one device, it is automatically synced to other devices.
- See file revisions.
- Share files with your friends, family, and coworkers
-
Send a notification when a file is edited, deleted, or shared with you.
- Reliability. Reliability is extremely important for a storage system. Data loss is unacceptable.
- Fast sync speed. If file sync takes too much time, users will become impatient and abandon the product.
- Bandwidth usage. If a product takes a lot of unnecessary network bandwidth, users will be unhappy, especially when they are on a mobile data plan.
- Scalability. The system should be able to handle high volumes of traffic.
- High availability. Users should still be able to use the system when some servers are offline, slowed down, or have unexpected network errors.
Basic Design
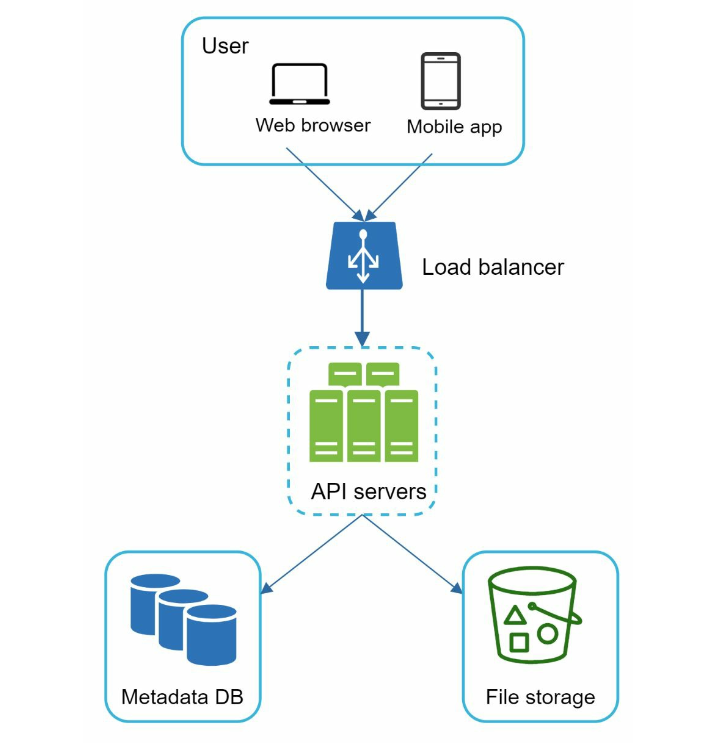
- file storage: AWS S3, files are replicated in two separate geographical regions
Sync Conflict
- Two users edit the same file at the same time
- Solution:
- the first version that gets processed wins
- the version that gets processed later receives a conflict
- system presents both copies of the same file: user 2’s local copy and the latest version from the server. User 2 has the option to merge both files or override one version with the other.
High-level design
Detailed Design
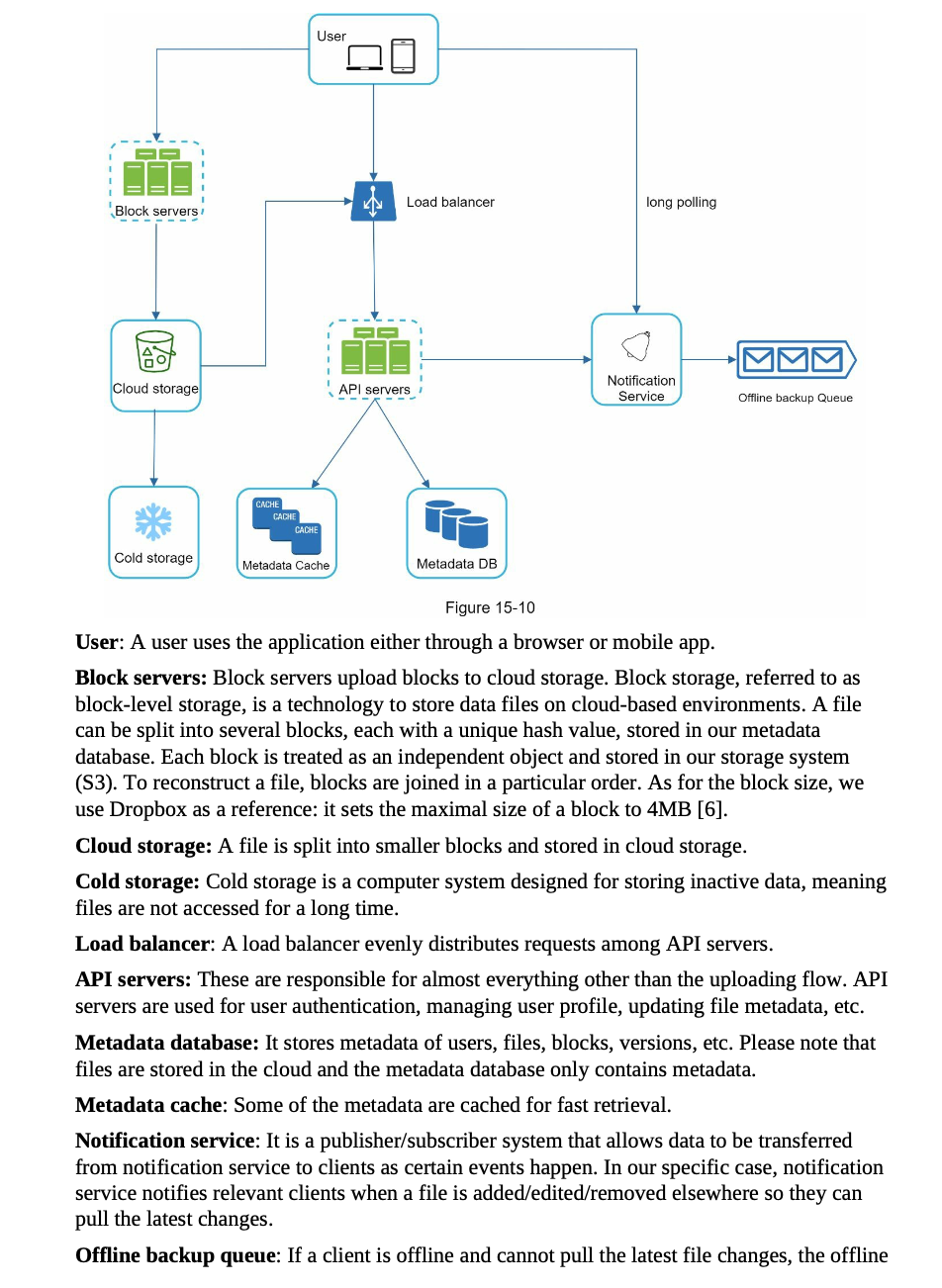
Block servers
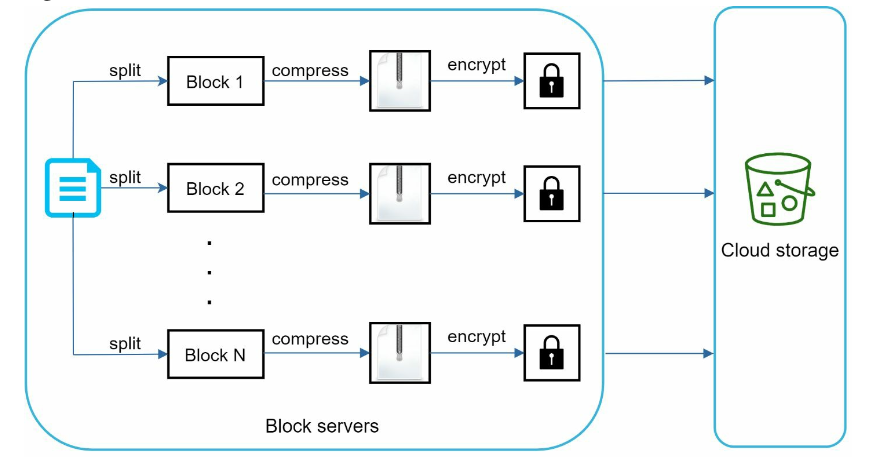
- A file is split into smaller blocks.
- Each block is compressed using compression algorithms.
- To ensure security, each block is encrypted before it is sent to cloud storage.
- Blocks are uploaded to the cloud storage.
Block servers are used to minimize the amount of network traffic being transmitted, especially in following situations:
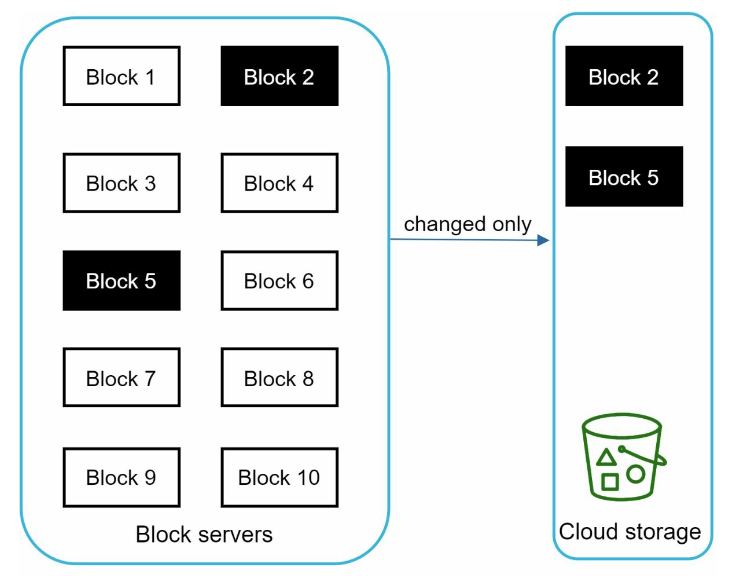
- Delta sync. When a file is modified, only modified blocks are synced instead of the whole file using a sync algorithm.
- Compression. Applying compression on blocks can significantly reduce the data size. Like gzip and bzip2 are used to compress text files.
Consistency requirements (metadata db)
Memory caches adopt an eventual consistency model by default, which means different replicas might have different data.
To achieve strong consistency, we must ensure the following:
- Data in cache replicas and the master is consistent.
- Invalidate caches on database write to ensure cache and database hold the same value.
Achieving strong consistency in a relational database is easy because it maintains the ACID (Atomicity, Consistency, Isolation, Durability) properties. However, NoSQL databases do not support ACID properties by default. ACID properties must be programmatically incorporated in synchronization logic. In our design, we choose relational databases because the ACID is natively supported.
Possible Metadata DB schema

upload flow
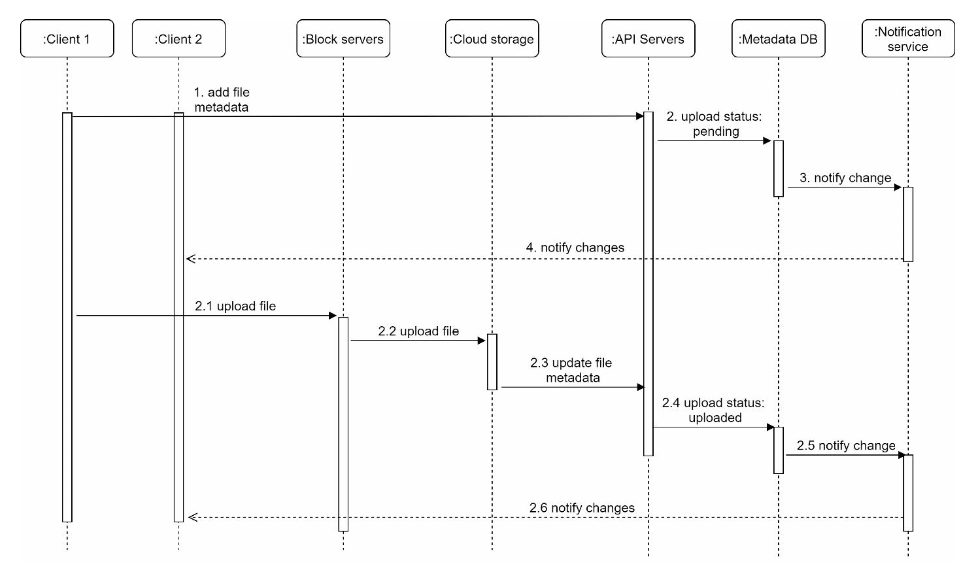
edit flow is alike
Download flow
Download flow is triggered when a file is added or edited elsewhere.
Two ways a client can know a file is added or edited by another client:
- Notification system: If client is online
- If client A is offline while a file is changed by another client, data will be saved to the cache. When the offline client is online again, it pulls the latest changes.
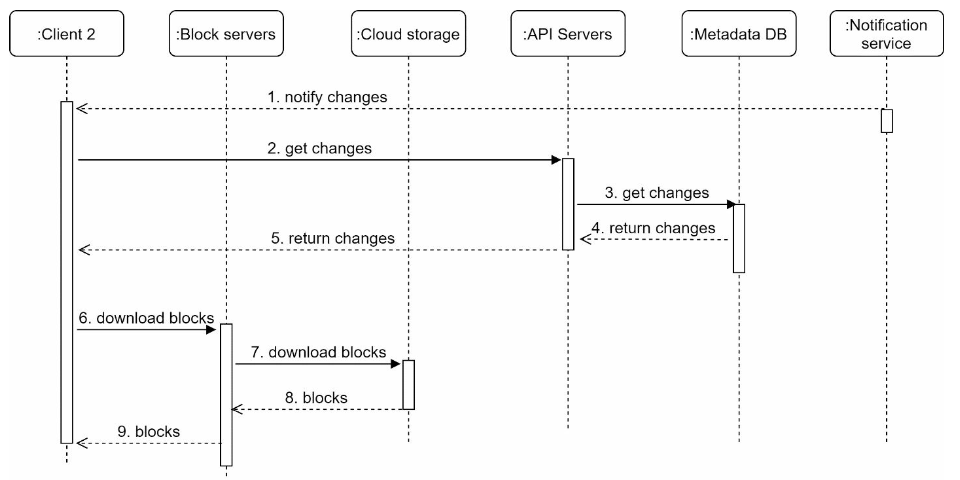
Notification service
purpose: maintain file consistency, any mutation of a file performed locally needs to be informed to other clients to reduce conflicts
- Long polling: better choice
- Communication for notification service is not bi-directional
- WebSocket is suited for real-time bi-directional communication such as a chat app. For Google Drive, notifications are sent infrequently with no burst of data
- WebSocket
Save storage space
- De-duplicate data blocks. Eliminating redundant blocks at the account level is an easy way to save space. Two blocks are identical if they have the same hash value.
- Adopt an intelligent data backup strategy
- Set a limit for maximum file versions: If the limit is reached, the oldest version will be replaced with the new version.
- Keep valuable versions only: To avoid unnecessary copies, we could limit the number of saved versions. We give more weight to recent versions.
- Moving infrequently used data to cold storage. (which is cheaper, like AWS Glacier)
Failure handling
- Load balancer failure: If a load balancer fails, the secondary would become active and pick up the traffic. Load balancers usually monitor each other using a heartbeat, a periodic signal sent between load balancers. A load balancer is considered as failed if it has not sent a heartbeat for some time.
- Block server failure: If a block server fails, other servers pick up unfinished or pending jobs.
- Cloud storage failure: S3 buckets are replicated multiple times in different regions. If files are not available in one region, they can be fetched from different regions.
- API server failure: It is a stateless service. If an API server fails, the traffic is redirected to other API servers by a load balancer.
- Metadata cache failure: Metadata cache servers are replicated multiple times. If one node goes down, you can still access other nodes to fetch data. We will bring up a new cache server to replace the failed one.
- Metadata DB failure.
- Master down: If the master is down, promote one of the slaves to act as a new master and bring up a new slave node.
- Slave down: If a slave is down, you can use another slave for read operations and bring another database server to replace the failed one.
- Offline backup queue failure: Queues are replicated multiple times. If one queue fails, consumers of the queue may need to re-subscribe to the backup queue.