Introduction
This is a note for some basic concepts in distributed system.
Table of Contents
- Introduction
- Table of Contents
- RPC
- Primary-Backup Replication
- MapReduce
- Chord
- CDN
- Raft
- Existing fault tolerance
- Theorem Discussion
- RSM Consensus with 5 assumptions
- Raft Overview
- Zookeeper
- Bitcoin
- Ethereum
- Google File System
- Big Table
RPC
- Calls a procedure at a different address space
- Transfer of both control and data across a communication network
Key Points
- stubs: automatically generated by a program called lupine
from interface module
- An interface module is a list of procedure calls together with the types of their arguments and results
- Today, we call this “interface module” interface description and the corresponding language, interface description language, e.g., protobuf
- Binding: Check to make sure that the procedure descriptions match between the client and the server
Primary-Backup Replication
Failure model
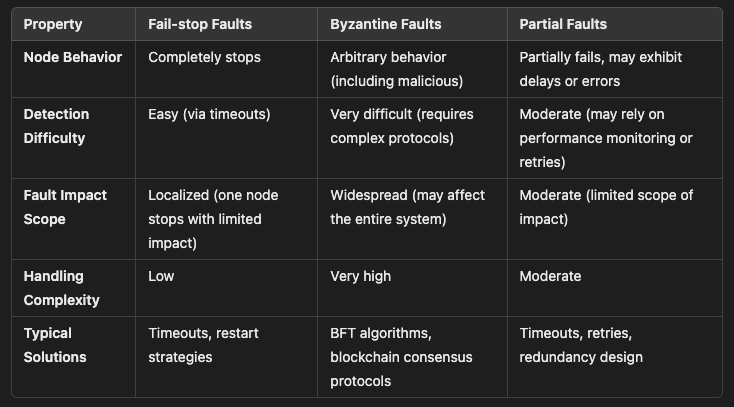
- Fail-stop faults: node/parts/processes stop executing but do not exhibit Byzantine behavior
- Stop executing
- Detectable
- No Byzantine behavior
- Hardware failure: power outage, CPU overheating, network cable tripped
- Kernel panic
- Byzantine faults: arbitrary behavior
- Bugs, adversaries, attacker
- Malicious: The node may attempt to disrupt the entire system intentionally.
- Complexity: These faults are among the most challenging to handle as they require the system to tolerate the worst-case scenario.
- Needs other methods: Byzantine fault tolerance, blockchain
- Higher-scale deployment -> more failures -> less reliable
- Needs to assume different replicas fail independently
Replicate Methods
State transfer
- Primary sends replicas the state of the primary
Replicated state machine
- State changes are “mostly” deterministic
- Primary sends replicas the external events
-
External events are smaller than states in terms of size
- Replicas must agree on a sequence of actions.
- A replicated log or ledger of requests (commands, ops).
- Strong ordering condition: important rule to ensure consistency and convergence
- Necessary for convergence: ensure all replicas end up in the same state
- Sufficient for convergence: for a deterministic program, if all replicas start in the same state and execute the same sequence of requests, they will end up in the same state.
- How to ensure a sequence?
- Consensus Algorithm
- Linearizability and Sequential Consistency
- Log Replication
- Timestamps
- Leader-Based Architecture
- Distributed Locks
- Conflict-Free Replicated Data Types (CRDTs)
Replication Layer Choice
- Application-level replication
- Need careful application designs
- Virtual Machine
- make non-fault-tolerant application become fault-tolerant in a transparent way
Virtual Machine
- Hypervisor: VMM
- Slide a hypervisor within/underneath the host OS kernel. (New OS layer: also called virtual machine monitor VMM)
- Run multiple guest VM instances on a shared computer
- Each VM is a sandboxed/isolated context for any entire OS
- VM instance “looks the same” to guest OS as a physical machine
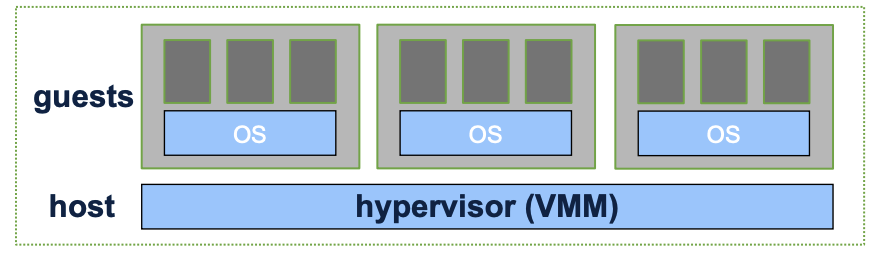
Why Virtual Machine?
- Sharing resources
- Isolation between different workloads
- able to Run a different OS for legacy applications
- checkpoint and migration
Design Details
- low overhead
- runtime performance
- low network B/W usage
- Easy to use
- Automated replication and failure recovery
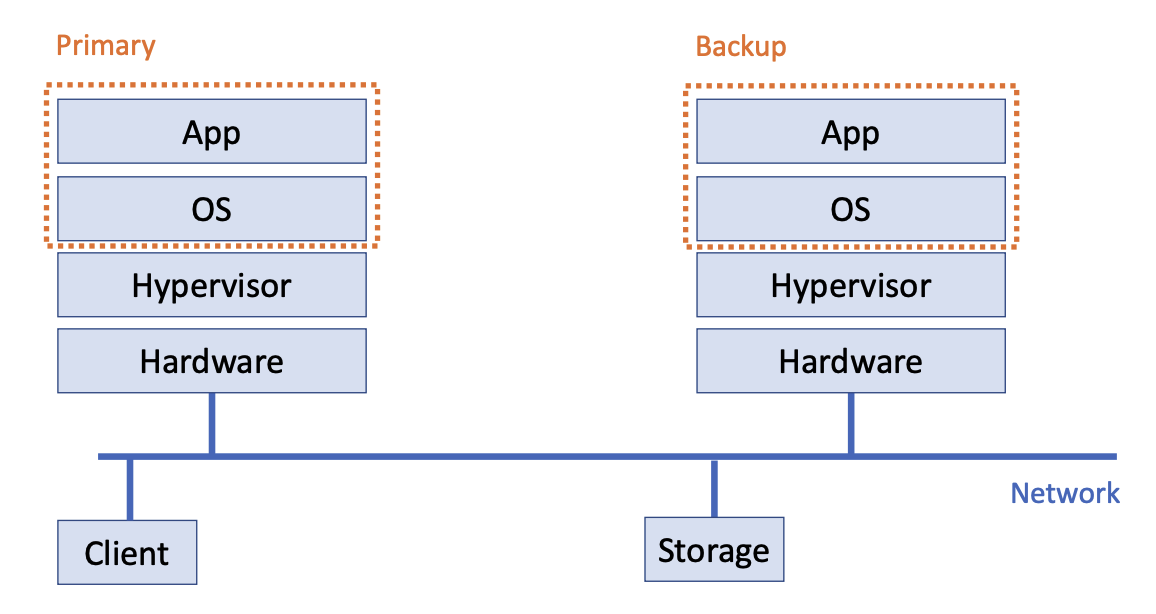
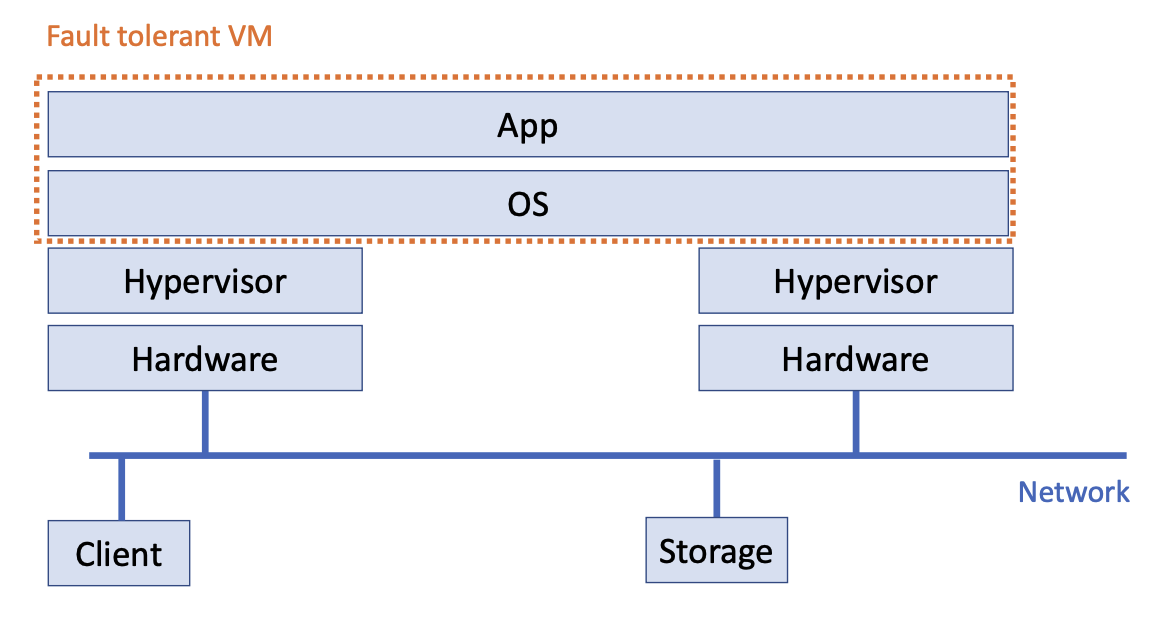
- Ideal Status:
- If two deterministic state machines are started in the same initial state and provided the exact same inputs in the same order, then they will go through the same sequences of states and produce the same outputs
How it runs with no failure
- Keep primary and backup in sync
- Log Inputs and non-deterministic events
- Network packets
- Interrupts
- Special operations (e.g., read clock time)
- Assumption: VM has a single core
- Primary can output to the client
- Backup’s output is dropped at the hypervisor

- if the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is entirely consistent with all outputs that the primary VM has sent to the external world
- An external observer cannot “sense” the failure of the primary
Logging
- Inputs will be logged
- Network packets received
- Non-deterministic events will be logged
- log the exact instruction at which the event occurred
- requires support from hardware
- Special instructions’ return value must be logged
Output requirement
- Output rule: the primary VM may not send an output to the external world, until the backup VM has received and acknowledged the log entry associated with the operation producing the output
- Delay response from the primary to the client
- The backup must have all the information (i.e., log entries) needed to generate the output that the primary will generate
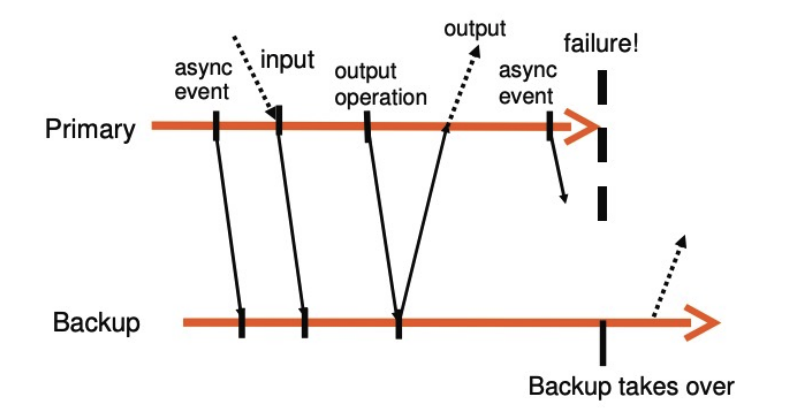
- The backup must have all the information (i.e., log entries) needed to generate the output that the primary will generate
-
Output Rule does not say anything about stopping the execution of the primary VM. We need only delay the sending of the output, but the VM itself can continue execution
- Output rule: a relaxation from truthy synchronized states
- allows for an efficient implementation of a primary-backup replication system
Failure Detection
- Heartbeat messages between primary and backup
- Split Brain Problem: What if both primary and backup believe that they are the primary?
- Test-and-set on shared storage (similar to a acquire lock)
MapReduce
Real dull stuff, simply skip it.
Chord
Peer-to-peer distributed protocol
- System model
- Load balancing: data is evenly distributed across node based on a hash function
- Decentralization: no node is more important than any other
- Scalability: operations should have logarithmic cost with respect to the number of nodes
- Availability: handle node joins and failures
- Flexible naming: no constraints on the structure of keys
- What Chord is for
- lookup (Key) -> IP address
- Notifies applications change of set of keys the node is responsible for
- What’s not Chord’s responsibility
- Authentication, caching, replication, user-friendly naming
- Example of Chord in Software
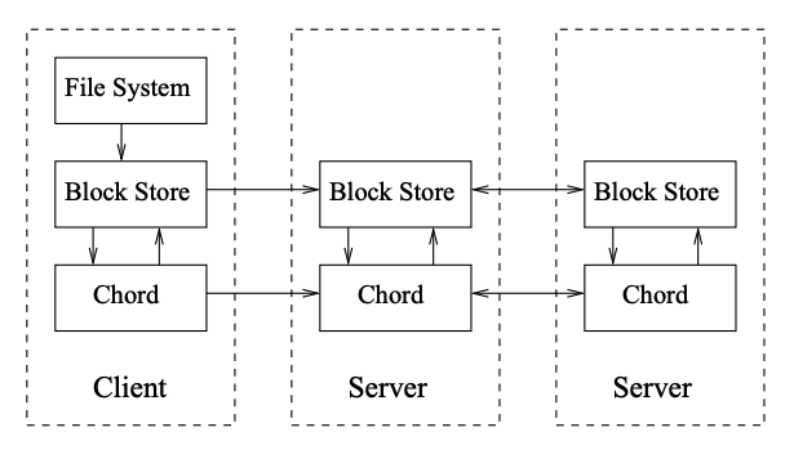
Consistent Hashing
Chord uses consistent hashing to assign keys to nodes
Nnodes andKkeys- each node is responsible for at most
(1+ε)K/Nkeys - node joins or leaves requires
O(K/N)key changes hands - How to reduce
ε?- Increase the number of virtual nodes
- More effective load balancing
- Better hash function
- each node is responsible for at most
InterNode Communication
Node receives a message, it will forward the message to the node responsible for the key
- Choice: Every node knows of all other nodes
O(N)Routing table size- Lookup time:
O(1)
- Choice: Every node knows its successor in the ring
- Routing table size:
O(1) - Lookup time:
O(N)
- Routing table size:
- Chord: Every node knows
O(log N)other nodes- pointers in the routing table point to the successor node of
2^i-th position in the ring 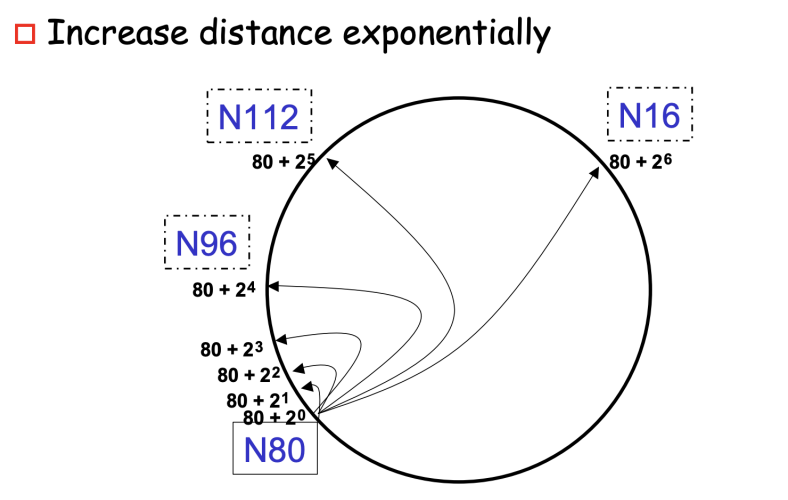
- pointers in the routing table point to the successor node of
Finger table

- Theorem 2: with high probability, the number of nodes that must be contacted to find a successor in an N-node network is
O(log N)
New Node Join
- New node
Njoins the network- Initialize the predecessor and fingers of node n
- Update the fingers and predecessors of existing nodes to reflect the addition of n
- Notify higher layer software so that it can transfer state associate with keys that node n is now responsible for
Step1: Initialize Finger Table of New Node
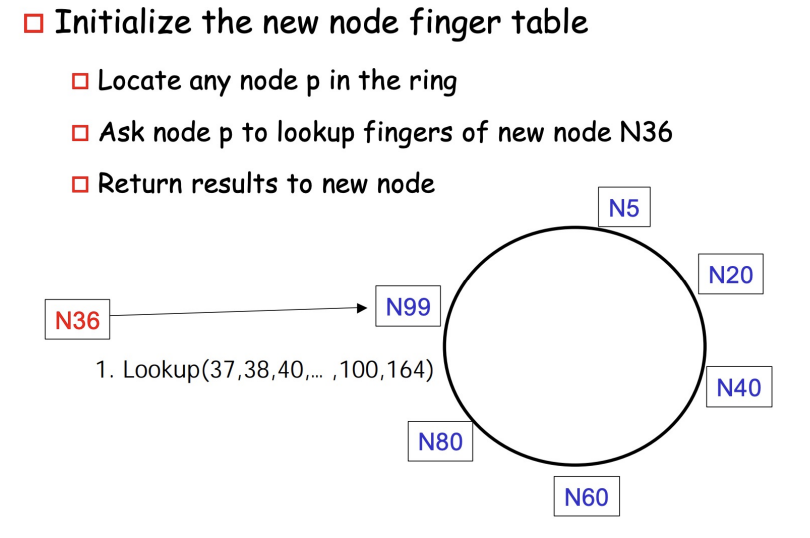
- utilize the existing node to look up the new node’s finger table
Step2: Update Finger Table of Existing Nodes
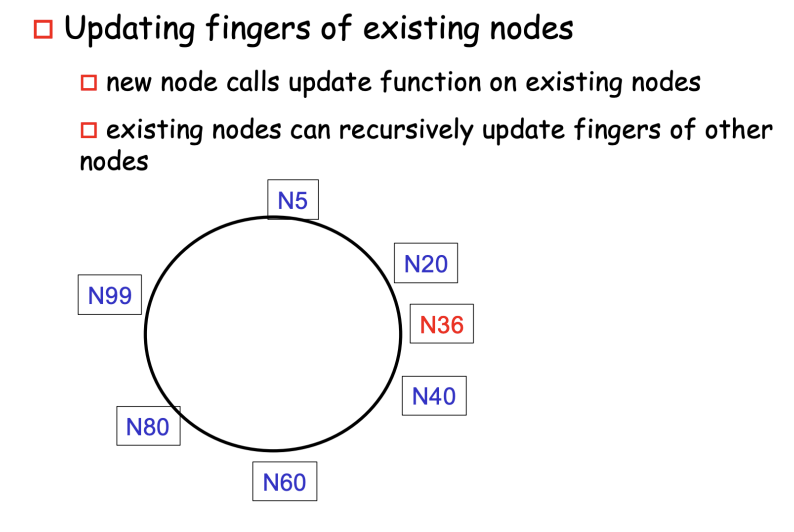
- recursively update the finger table of existing nodes to reflect the addition of the new node
Step:3 Transfer Keys
- Transfer keys to the new node from successor node
Stability During Node Join
- Approach:
- Predecessors and successors are maintained
- Fingers can be updated later
- Reason:
-
Theorem 4: once a node can successfully resolve a given query, it will always be able to do so in the future
-
Theorem 5: at some time after the last join, all successor pointers will be correct.
-
Performance during unstable period
-
Theorem 6: If we have a stable network of N nodes, adding another N nodes without finger tables, then lookup will still take
O(log N). -
The speed of updating finger tables only need to match the speed of growing network to double in size.
Node Failure Handling
- Node failure: a node is no longer reachable
- Approach:
- Use the successor list to detect node failure
- Each node keeps a
rlist of its successors - return the first live node in the successor list for find_successor query
- Theorem 7: with high probability, find_successor query will return the closest living successor
- Theorem 8: with high probability, find_successor query will return in
O(log N)
- Each node keeps a
- Heartbeat messages
- Use the successor list to detect node failure
CDN
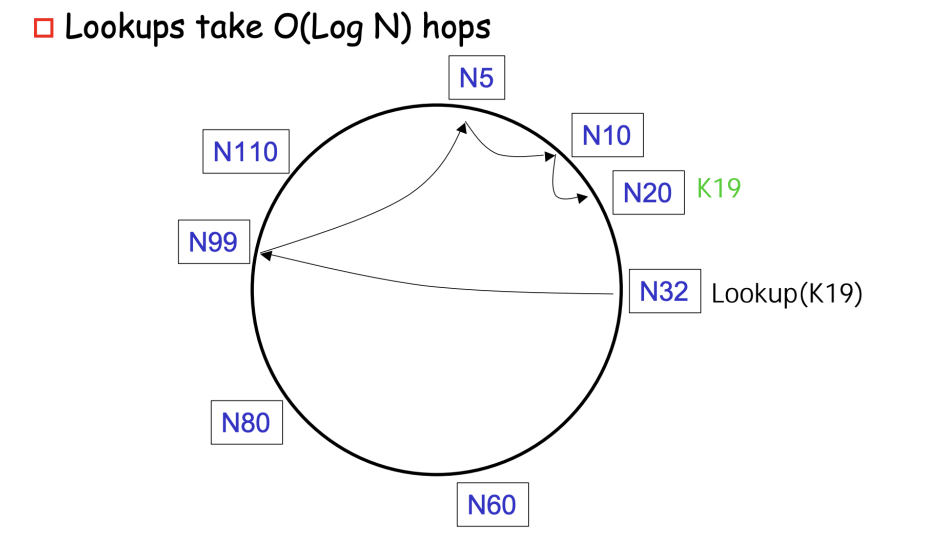
origin server -> CDN -> client
- origin server: the server that hosts the original content
- edge server: the server that hosts the cached content and is closer to the client
- CDN: a network of edge servers that cache content
Reverse Proxy
- A server that sits between the client and the origin server
- The client sends requests to the reverse proxy, which forwards the request to the origin server
- The reverse proxy caches the response from the origin server and returns it to the client
- Nginx, Apache, Varnish
- load balancing
- caching static content
- SSL termination
- safeguarding the origin server
- CDN can be seen as a network of reverse proxies
- Proxy server: edge server/ content server, “close to the eyeballs”
- Customer scale lease capacity from CDNas needed, “pay as you grow”
- Help absorb unexpected load from “flash crowds”/DDOS attacks
- Low capital expense, operational expense scales with delivered load
CDN Architecture
CDN Setup
- URL rewriting: change the URL of the request to point to the CDN
- DNS: resolve the domain name to the CDN
- Anycast:
- IP -> Server, route the request to the nearest edge server
- Allow multiple servers to share the same IP address
CDN Process
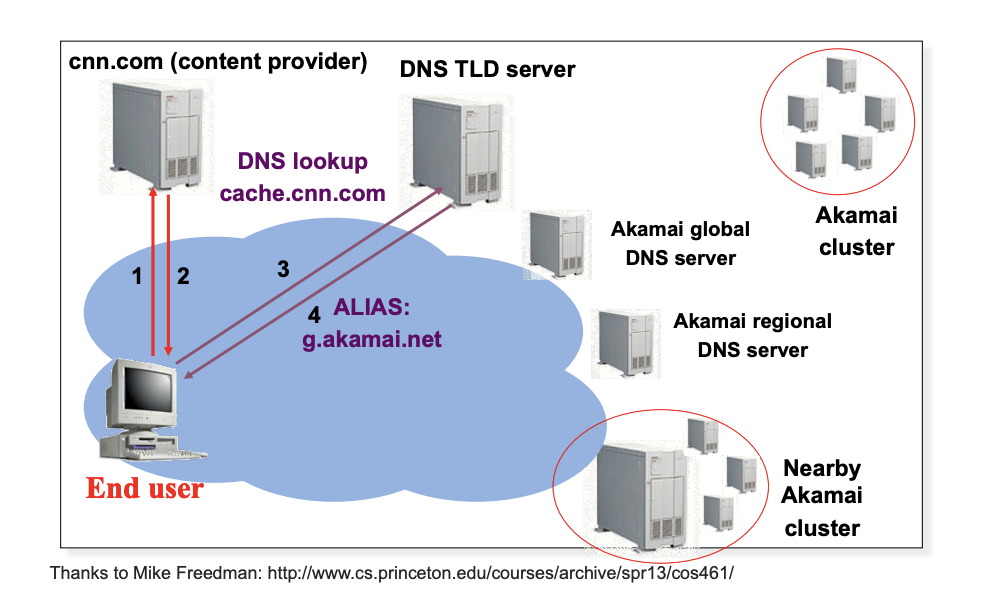
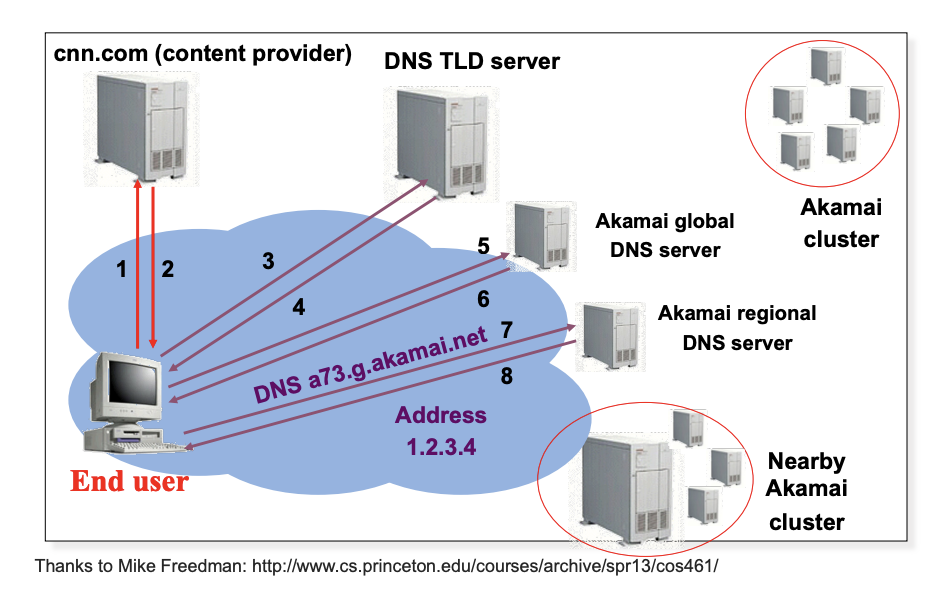
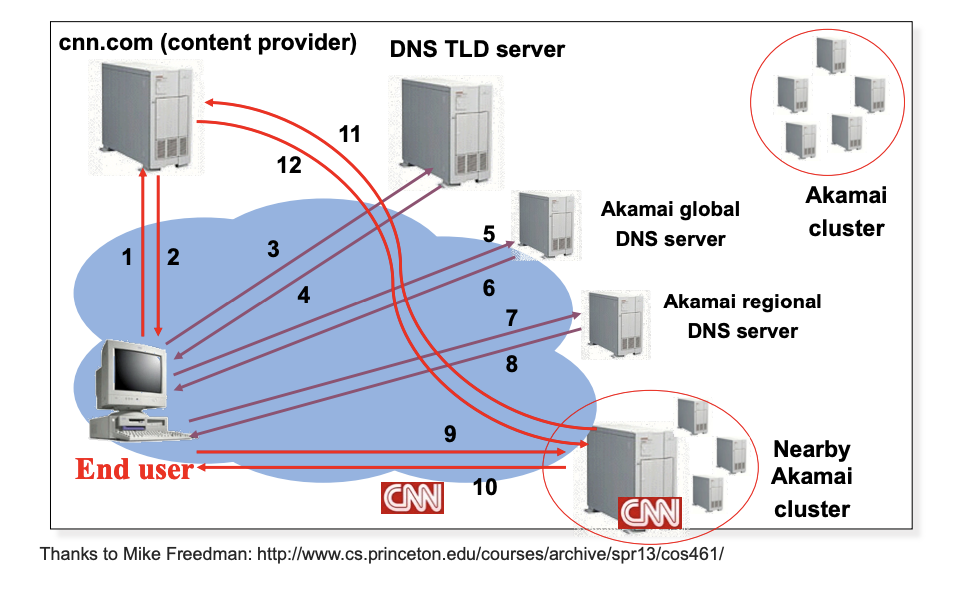
- Anycast part:
- process 5-7: global DNS -> regional DNS
- CNAME:
- process 1-2: give back ALIAS to the client

Request Mapping
- Request mapping: map the request to the optimal edge server
- Dynamically: based on the current load of the edge server
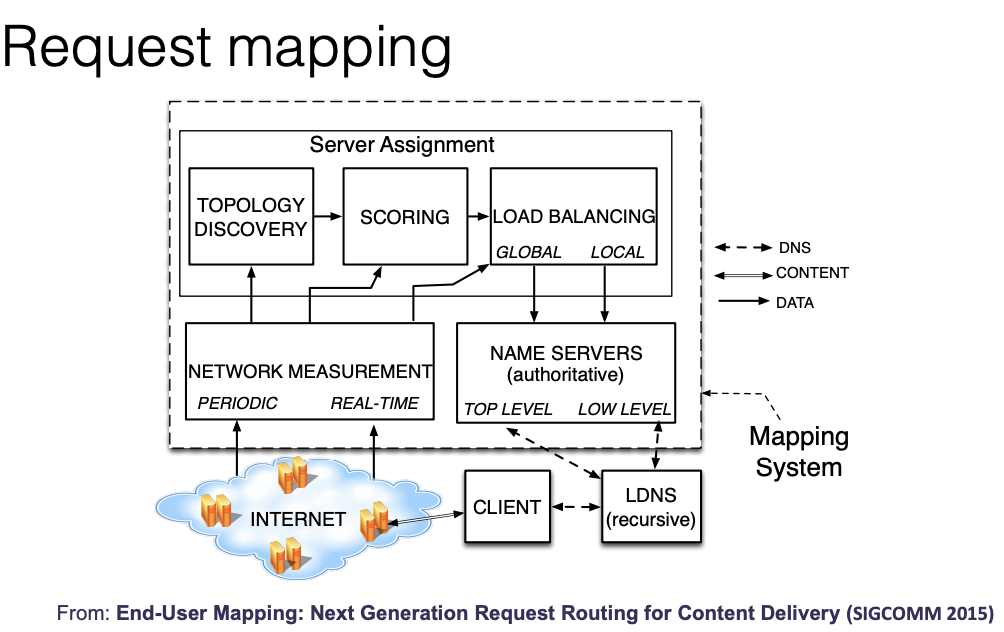
Performance OPtimization for static content
- Tiered distribution
- When an edge cluster does not have a piece of request content in cache, it retrieves that content from its parent cluster rather than the origin server
- Reduce the number of network connections the origin server needs to handle
- Overlay network for live streaming
- Using a cluster of servers call entrypoints to ensure data stream is reliably delivered to edge servers
Performance Optimization for dynamic content
- Distribuing application to the edge
- Allow developers to rent computation power from edge servers
- Content aggregation/transformation
- Static databases
- Data collection
Raft
Existing fault tolerance
- VM fault tolerance
- Primary-backup replication
- MapReduce
- Rerun failed tasks on different workers
- Requires a master to detect failed workers and initiate rerun of failed tasks
Stable leader: handling leader failure
- Leader sends a message to followers at regular intervals, even if there are no new op requests (heartbeat or ping or keepalive)
- Followers set timers. If timer fires with no heartbeat, abandon the leader and initiate leader election
Network partition problem
- Network partition: a network is split into two or more parts, and the parts cannot communicate with each other
- Could lead to multiple leaders
- Split brain problem: two parts of the network believe they are the leader
Theorem Discussion
Fischer-Lynch-Patterson
FLP: An asynchronous distributed system can be safe or live, but not both.
- Safety property: agreement/consistency
- Insist that “Nothing bad ever happens”
- Liveness property: termination/progress
- Insist that “Something good eventually happens”
- Availability can be seen as a liveness property (unbounded response time -> not available)
- No consensus can be guaranteed in an asynchronous system in the presence of failures
- Intuition: a “failed” process might just be “slow”, and can rise from the dead at exactly the wrong time
CAP Theorem
- Consistency: all nodes see the same data at the same time
- Availability: a guarantee that every request receives a response about whether it was successful or failed
- Partition tolerance: the system continues to operate despite network partitions
- CAP theorem:
- a distributed system can only guarantee two of the three properties
- It is impossible to implement an atomic data object that is available
- Proof: Partition the network. A write on one side is not seen by a read on the other side, but the read must return a response
Quorum-based Consensus
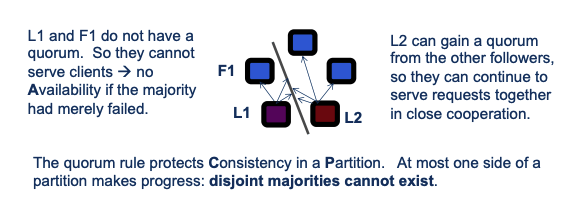
In order to lead and serve client requests, a leader L1 must continually receive votes from a majority of the group (a quorum)
- The quorum rule protects consistency (C) in a network partition
- at most one connected subgroup can serve requests.
- it sacrifices availability (A).
- If a majority of replicas fail, it might be safe for the survivors to serve clients.
- But they must not, because this case is indistinguishable from a network partition.
RSM Consensus with 5 assumptions
- Deterministic application service
- all nodes run the deterministic state machine, all replicas will end up in the same state if they start in the same state and execute the same sequence of requests
- Known configuration: fixed group of N=2f+1 replicas
- f is the number of faulty replicas
- N is the total number of replica nodes
- 2f+1 is the minimum number of replicas needed to tolerate f failures
- there should be at least f+1 correct replicas to make progress
- reason: with 2f+1 replicas, a majority of replicas is f+1, which is enough to make progress as quorum-based consensus requires
- Ready quorum: Available only if at most f failures and majority (f+1) are up and connected. Else keep trying!
- system is available only if a majority of replicas are up and connected
- if not enough replicas are up, consistency cannot be guaranteed
- Fail-stop faults: a failed replica is silent. Replicas run the same program and are faithful to it. Net may delay.
- assume that replicas do not exhibit Byzantine behavior
- Replicas run the same program and will obey the same protocol when they are not faulty
- Protocol should be designed to handle network delays
- Smart clients. On fail-over, clients switch and resync to the new leader. No lost/duplicate requests or responses.
- Clients must be able to detect leader switch and resync to the new leader
Early Attempts
- Paxos
- Viewstamped Replication
Raft Overview
Raft is a consensus algorithm for managing a replicated log
Normal Operation on rsm system using Raft
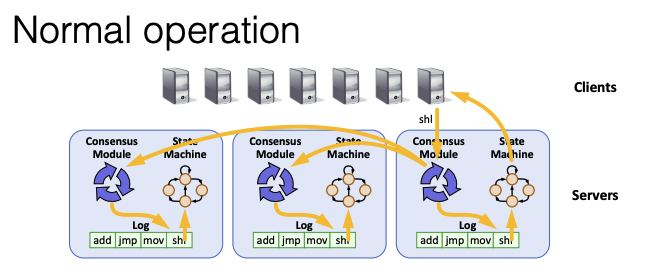
- Replicated log -> replicated state machine
- All servers execute same commands in same order
- Consensus module ensures proper log replication
- System makes progress as long as any majority of servers are up
- Failure model: fail-stop (not Byzantine), delayed/lost messages
State of Replicas
Leader:
accepts client requests, replicates log entries, and sends heartbeats to followers
- Upon election:
- send initial empty
AppendEntriesRPCs (heartbeat) to each server; - repeat during idle periods to prevent timeout and start new elections
- send initial empty
- If command received from client
- append entry to local log
- Use
AppendEntriesRPC to replicate log entry to followers - When responded by majority, commit entry and apply to state machine
- respond after entry applied to state machine
- Log management
- log replication:
- check follwers’
nextIndex, if last log index is bigger thannextIndex, sendAppendEntriesRPC with log entries starting atnextIndex- success: update
nextIndexandmatchIndexfor the follower - fail (inconsistency): decrement
nextIndexand retry, untilnextIndexis consistent with the leader
- success: update
- check follwers’
- log entry commit:
N> currentcommitIndexcommitIndexis the highest log entry index that the leader has committed
- a majority of
matchIndex≥NmatchIndexis the highest log entry index that the follower has replicated
- the term of the log entry at
Nis the current term- ensure that the log entry is replicated in the current term
- How to commit:
- update
commitIndextoN
- update
- log replication:
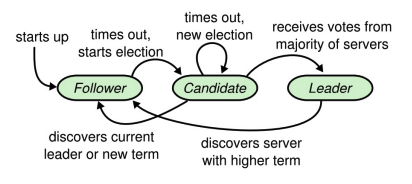
Followers:
replicate log entries, respond to requests from leader, and vote in elections
- If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate
Candidate:
- Nominate itself for leader, requests votes from followers, becomes leader if it receives votes from a majority of the group
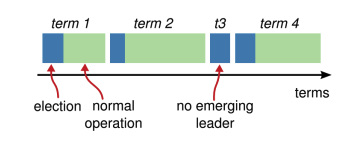
- term: a logical clock that represents the current leader
- leader election: increment term
- leader change: increment term
- term is used to ensure that only one leader is elected in a given term
Subproblems
Leader election
a new leader must be chosen when an existing leader fails
Log replication
the leader must accept log entries from clients and replicate them across the cluster, forcing the other logs to agree with its own.
Safety (State Machine Safety)
Property: if any server has applied a particular log entry to its state machine, then no other server may apply a different command for the same log index
other details

RPCS used in Raft
- AppendEntries RPC
- Leader sends log entries to followers
- Followers respond with success or failure
- also used as heartbeat
- RequestVote RPC
- Candidate requests votes from followers
- Followers respond with vote or no vote
- Idempotent: both RPCs are idempotent
Leader Election
- To begin an election, a follower increments its current term and transitions to candidate state.
- It then votes for itself and issues RequestVote RPCs in parallel to each of the other servers in the cluster
- A candidate continues in this state until one of three things
happens:
- (a) it wins the election
- (b) another server establishes itself as leader (sending out heartbeats)
- (c) a period of time goes by with no winner.
- Each server will vote for at most one candidate in a given term, on a first-come-first-served basis
- Once a candidate wins an election, it becomes leader. It then sends heartbeat messages to all of the other servers to establish its authority and prevent new elections.
- To prevent split votes, election timeouts are chosen randomly
from a fixed interval (e.g., 150-300ms).
- This way, servers will time out at different times, preventing them from starting elections as candidates at the same time
- Hopefully, one follower time out at a time
Leader: maintain log consistency
- The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower.
- When a leader first comes to power, it initializes all nextIndex values to the index just after the last one in its log.
- If a follower’s log is inconsistent with the leader’s, the AppendEntries consistency check will fail in the next AppendEntries RPC
- After a rejection, the leader decrements nextIndex and retries the AppendEntries RPC.
Election restriction
Problem: What if the candidate don’t have the committed log entries? (if the candidate becomes the leader, it may flush others’ committed log entries)
- Goal: A candidate wins the election unless its log contains all committed entries
- A RequestVote RPC includes information about the candidate’s log, and the voter denies its vote if its own log is more up-todate than that of the candidate.
- idea here: a committed log entry is replicated in a majority of servers ( at least f+1 servers). If a candidate need f+1 votes to win the election, these add up to 2f+2, which means at least 1 voter will have the committed log entry.
Committing entries from previous terms
- Delay commit for log entries from previous terms for new leader
- If a leader is elected and finds that log entries from previous terms are not committed, it can’t commit them immediately even if they are replicated in a majority of servers
- New leader must wait until it has replicated a log entry from its own term before committing log entries from previous terms
Correctness of Raft
Based on the Election restriction and Committing entries from previous terms rule, raft ensures that a committed log will always show up in the leader’s log eventually
Cluster membership changes
- Log entries are replicated to all servers in both configurations
- Any server from either configuration may serve as leader
- Agreement (for elections and entry commitment) requires separate majorities from both the old and new configurations
Non-volatile memory
- Follower should persist its vote for a candidate

Zookeeper
- When using an RSM library(like raft)
- very complex to use
- need to rethink about whether the application is actually a state machine, like how to integrate
- Using a coordination service
- Zookeeper
Raft: replicating computation Zookeeper: replicating state
Coordination Service
-
provide uable api (zookeeper’s goal)
-
implemented in a high-performance way
- Raft: asks every request to be processed in a Sequential manner, since the log is sequential. That will replicate the computation among all the replicas.
- more replicas -> more overhead
- Zookeeper: relaxed consistency
- more replicas -> more performance/speedup (zookeeper’s goal)
- Raft: asks every request to be processed in a Sequential manner, since the log is sequential. That will replicate the computation among all the replicas.
Data Model
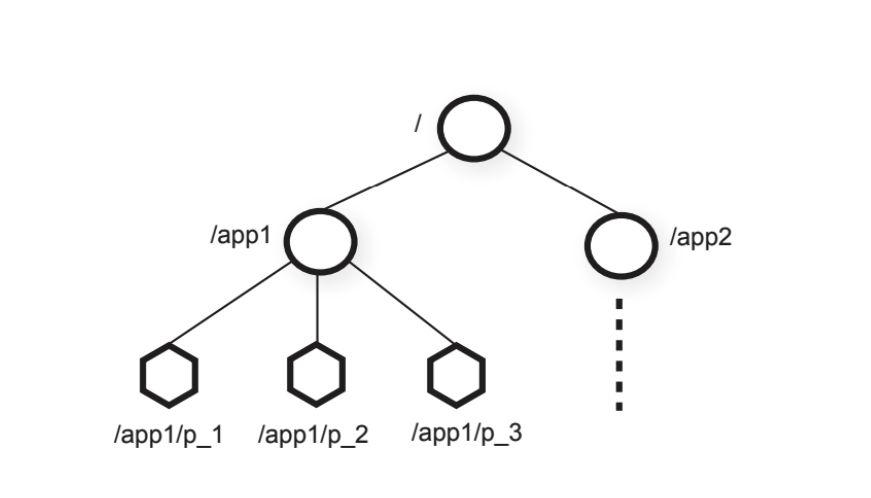
- Zookeeper utilize a hierarchical file system
- similar to a file system
- each node is called a znode, and can have children znodes
- zookeeper uses paths to identify znodes
Zookeeper Structure
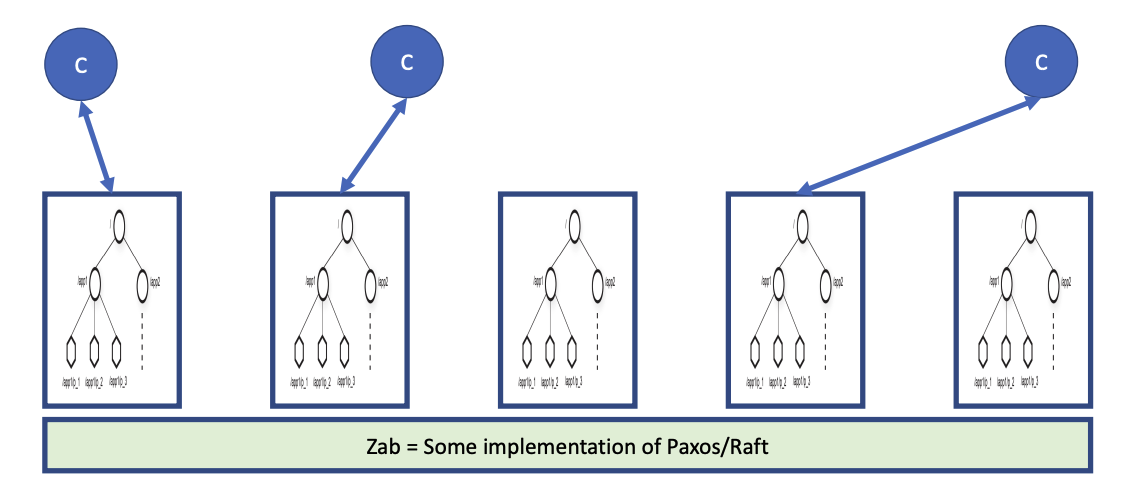
Two types of files
- Regular files: Creation or deletion must be explicit
- Ephemeral files: Automatically deleted when the client session ends
Operations on znodes
Create(path, data, flags)- Exclusive: only create if the znode does not exist
- flags:
- PERSISTENT: regular file
- EPHEMERAL: ephemeral file, ephemeral nodes won’t have children
- SEQUENTIAL: append a monotonically increasing counter to the znode name, this node can be PERSISTENT or EPHEMERAL
- CONTAINER: create a container znode, which will be deleted when all children are deleted
- PERSISTENT_SEQUENTIAL_WITH_TTL: create a PERSISTENT_SEQUENTIAL znode with a time-to-live
Delete(path, version)- only delete if the version matches(znodes.version == version)
Exists(path, watch)- watch: set to true, the client will be notified when the znode changes(create/delete)
GetData(path, watch)- will return entire data of the znode
SetData(path, data, version)- only update if the version matches(znodes.version == version)
GetChildren(path, watch)Sync()- force the server to sync with the leader
- returns when writes before sync are visible to the client
these apis are well tuned for concurrency and synchronization
- exclusive create: exactly one concurrent create returns success
- getData/setData: supports mini-transactions(atomicity)
- sessions automate actions when clients fail (like release locks on failure)
- watches: avoid polling
Linearizability
- At a high-level, we want a replicated system to behave as a single copy
- replications are just for fault tolerance
- clients should not feel the difference between a single copy and a replicated system
- Check the definition of linearizability on Internet

- Consisten
- Sequential
- Instantaneous(real-time)
- Atomic
- a kind of Strong Consistency
- Example of linearizability
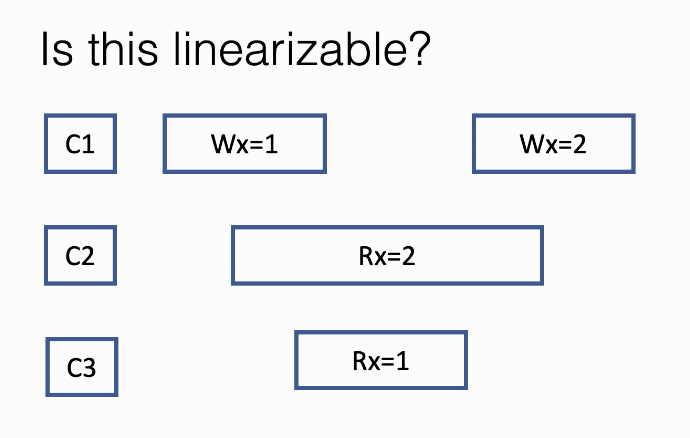
- C1: Write X = 1 and then Write X = 2
- C2: Read X, and the return moment X == 2
- C3: Read X, and the return moment X == 1
- all the operation can happen in any single point of the annotated time period (rectangle), generating a sequential history is like picking a point in the periods for each operation and connect them in a line
-
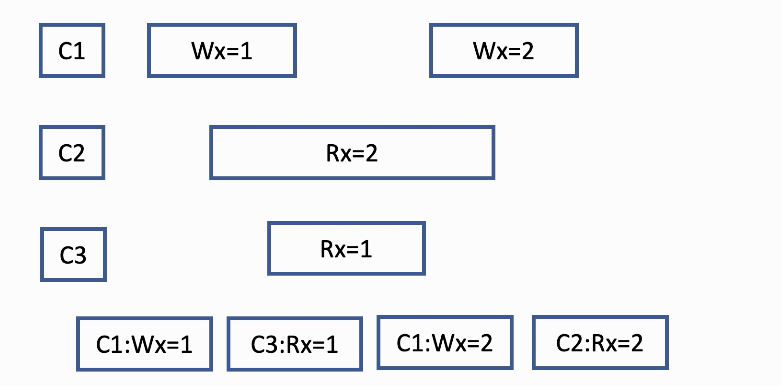
- This one violate the linearizability
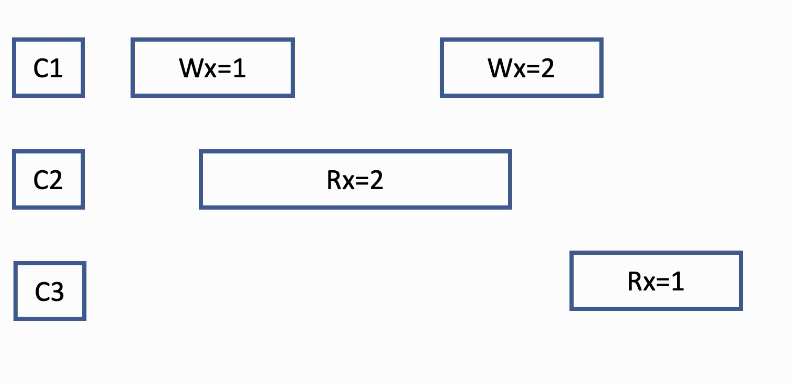
- according to linearizability’s second rule, C2’s read X should be placed ahead of C3’s read X
- And the only possible sequential history violates the rule
Sequential Consistency, Eventual Consistency and Strong Consistency
- Sequential Consistency:
- ensure all operations are visible to all clients in the same order(like write)
- but not guarantee the real-time result of the operation: client might see state before write operation propagated
- Eventual Consistency:
- ensure all the replicas will eventually converge to the same state
- no real-time consistency guarantee
- Strong Consistency:
- ensure all the operations are visible to all clients in the same order
- guarantee the real-time result of the operation
Raft provides linearizability
- all the operations are serialized by the log
- if operation a is after operation b, this means b is committed before a by the leader
- operation a is after operation b in the log
Zookeeper’s guarantee
- Sequential Consistency
- Eventual Consistency
-
Linearizable writes
- FIFO ordering for clients
- read may return stale data
- zookeeper allows read from every where, but write only from the leader
- for a single client, all the operations are processed in the order they are sent among all the nodes
- for different clients, the order of operations is not guaranteed
- read may return stale data
Replicated Database
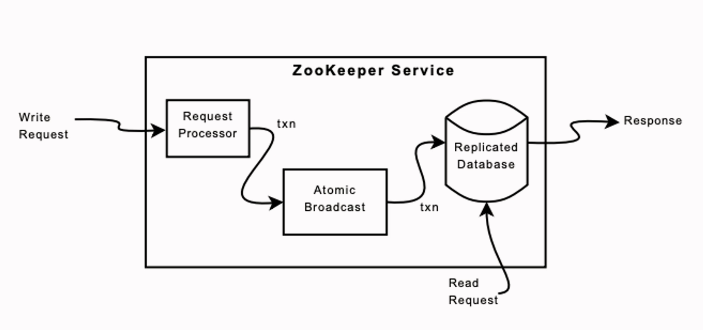
- ZooKeeper uses periodic snapshots and only requires redelivery of messages since the start of the snapshot.
- Snapshots are fuzzy since we do not lock the ZooKeeper state to take the snapshot
- The result may not correspond to the state of ZooKeeper at any point in time
- Since state changes are idempotent, we can apply them twice as long as we apply the state changes in order
How is FIFO client ordering ensured
- When a client sends a request, the replica returns zxid
- Zxid is the id of the last write
- Client keeps the most recent zxid and sends it along with a read request
- if replica is not updated till zxid, wait (hold the response until its the same up-to-date as client)
- Otherwise, return data from database
- as clients’ requests may not have latest zxid from other clients, there might still be stale reads
Read/Write Guarantee
- suppose we have configuration data in ZK that coordinator writes, but that many other ZK clients need to read and the data consists of a bunch of zknodes
C1:
Delete(“ready”)
Write f1
Write f2
Create(“ready”)
C2:
Exists (“ready”, watch = true)
Read f1
Read f2
- C1: delete the ready flag, rewrite f1, rewrite f2, and create the ready flag
- C2: watch the ready flag, read f1, read f2
- If the ready only serves as a lock, C2 can read a “bad configuration” (f1 and f2 are not consistent)
- If the ready is set with watch, C2 will be notified when the ready is modified, and handle the situation properly
Application of Zookeeper
Simple locks
Lock:
Create(“lock”, EPHEMERAL, watch=true)
Unlock:
Delete(“lock”)
- problem: will cause herd behavior
- all the clients will be notified when the lock is released
- all the clients will try to acquire the lock at the same time
Simple locks without herd effect
Lock:
n = create(l +”lock-”, EPHEMERAL|SEQUENTIAL)
While (true) {
C = getchildren(l, false)
If n is lowest znode in C, exit
P = znode in C ordered just before n
If exists(p, watch = true) wait for watch event
}
Unlock:
Delete(n)
like FIFO lock. The lock is acquired by the lowest znode, and the next znode will wait for the previous znode to be deleted
The while true here is to prevent the crush of the client that generated the previous znode.
Bitcoin
stronger fault tolerance
- what if Failed but still responding to heartbeats
- unable to detect directly
- what if Do not follow designed protocol?
- accidentally
- intentionally by malicious participants
Raft and Byzantine Fault Tolerance
- Node numbers should be
3f+1to toleratefByzantine faults- Quorum-based consensus requires
2f+1nodes: at leastf+1correct nodes to make progress - the union of two quorums is
2f+1 + 2f+1 - (3f+1) = f+1, meaning that at even there arefByzantine faults, there are still1correct node to make progress- Byzantine nodes can make arbitrary decisions among different quorums, making inconsistency
- shared correct node among different quorums will act like a bridge to ensure the spread of correct decisions
- correct nodes can detect Byzantine nodes and prevent them from leading to inconsistency
- Quorum-based consensus requires
Blockchains
- Achieving consensus against malicious participants
- No centralized trust, using a peer-to-peer network
- Proof of work
- Bitcoin
- Ethereum 1.0
- Proof of stake
- Ethereum 2.0
Challenges in Bitcoin
- Forgery
- don’t want anyone to forge money
- solved by digital signatures
- Double spending
- can’t spend the same money twice
- Theft
- Private keys can be stolen/lost if not stored appropriately
Digital Signatures
-
Sig(message, private key)-> Signature -
Verify(message, Signature, public key)-> True/False
Bitcoin account
An address names a principal: an entity that can own coin.
- A principal is a public key
- account owner is anyone with the matching private key
- owner may spend coin by publishing a signed statement (a “transaction”) to transfer it to another address
Example of spending money
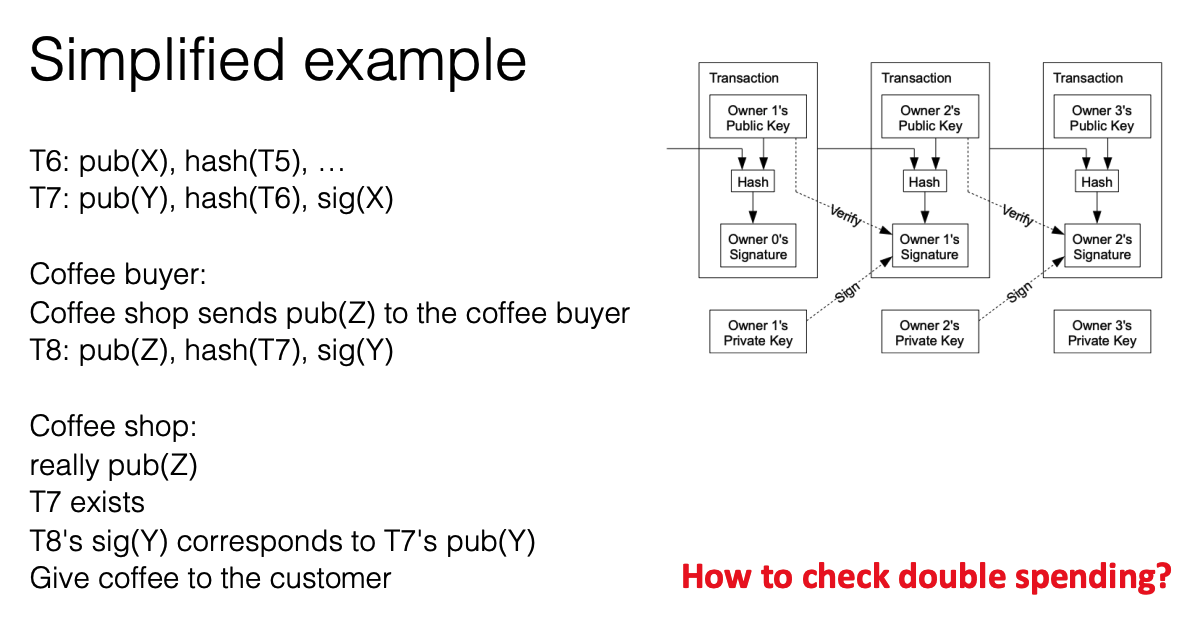
<Transaction>: <Receiver's Pub Key>, <Amount>, <Signature>- prior transaction acts as the proof of money ownership
How to check for double spending
Normally a central trusted party is needed to check for double spending
- a sequential, global order of all the transactions will be needed
- check the transaction log to see whether the coin is spent before
proof of work
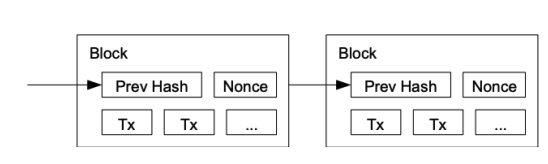
- Here T denotes the transaction, each block contains fixed number of transactions
- Bitcoin clients broadcast transactions to every miners in system
- Miners: maintain blockchain, create blocks and append
- Miners can try to add different transactions to the same block
- Miners try to append blocks to the blockchain. Each append requires finishing computational work
- Find a number x such that th ehash result have at least y leading zeros
Hash(Hash(previous block), Tx1, Tx2, Tx3, …., x)-> 0x0000000ab20acde- Nonce here serves as an random input to the hash function
- A “Miner” broadcasts to all other miners once a block is appended
Why previous hash is included in the block?
- prove where you are attaching in the chain
- to ensure the order of the blocks and preven from blocks being modified
RSM Consensus without trust
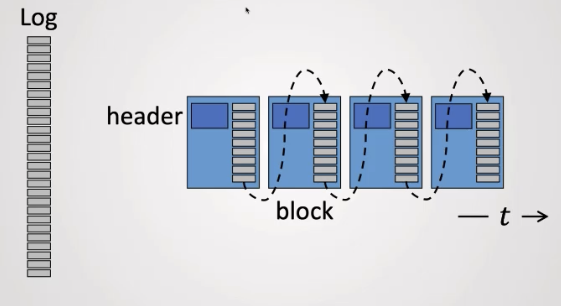 “Nakamoto Consensus”: a consensus algorithm that allows a set of nodes to agree on a set of transactions without trusting each other
“Nakamoto Consensus”: a consensus algorithm that allows a set of nodes to agree on a set of transactions without trusting each other
- Randomly choose replica to append a new block of log entries
- Each new block links securely to the previous block
- Adding a new block -> signals approval of all previous blocks
- Broadcast the new block; receivers inspect and accept/reject.
- reward faithful contributions and punish misbehavior
Correctness of Consensus
How to obtain consensus?
- miner proposes a new block with a sequence of new transactions, appended to the ledger/log/chain as they view it.
- “Everybody” verifies for themselves that the new block is valid and is linked to the “end of the chain”. Else reject block.
- Each replica exposes its current view of the chain to clients, but its view may change if it hears of a different/longer log suffix.
- If a replica accepts (votes for) a block, it also accepts the linked predecessor(s), overwriting/reverting its log suffix as necessary.
Longest valid chain wins: miners will dump the shorter chain once receiving a longer valid chain
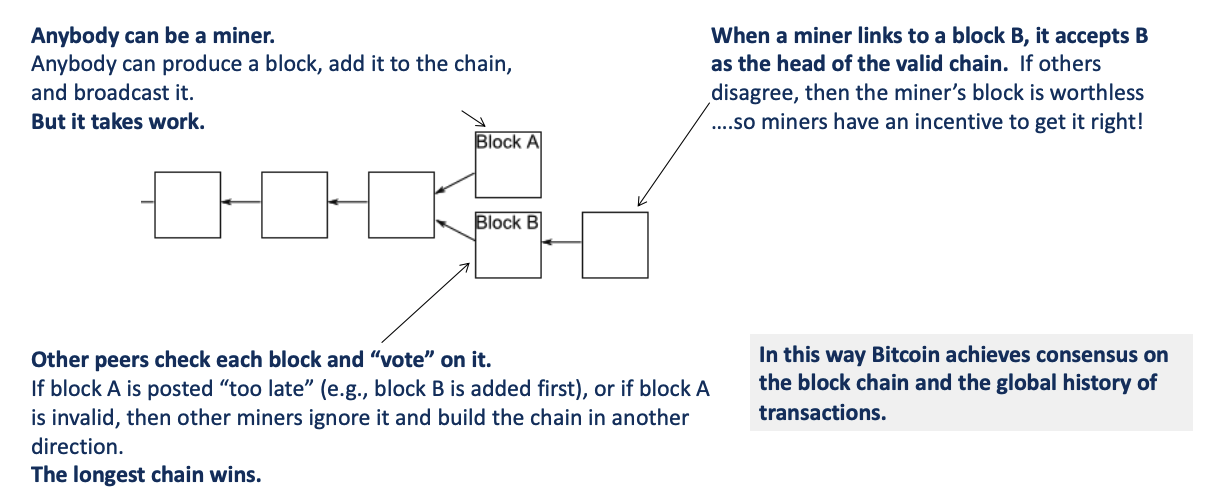
- if client’s transaction is in the chain’s tail-side blocks, then the transaction is confirmed
Forks and healing
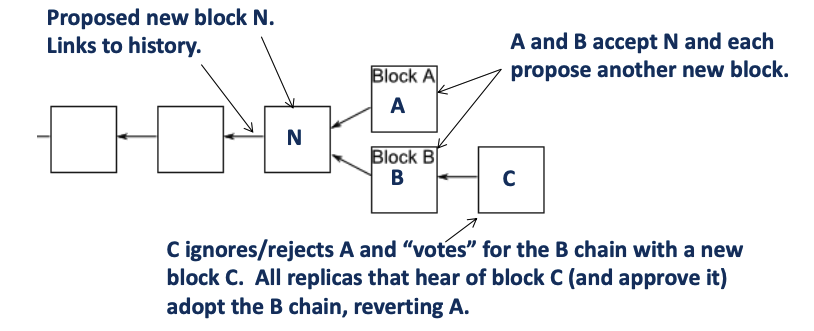
- Forks: result from faults, partitions, races, or attacks
- Over time, forks should resolve: one branch grows longer (attracts more “votes”) and so dominates
the only possibility for double spending is to let transactions appear on two different branches of the chain, which will finally be resolved by the longest chain rule
Miners’ Incentive
- Miners are rewarded for their work
- Each new block can include a Bitcoin payment to the miner that appends the block
- The total amount of Bitcoin is fixed, and the payment decreases in geometric fashion
- Client can optionally include a transaction fee to the miner, Miner will prioritize transactions with higher fees
Simplified Payment Verification
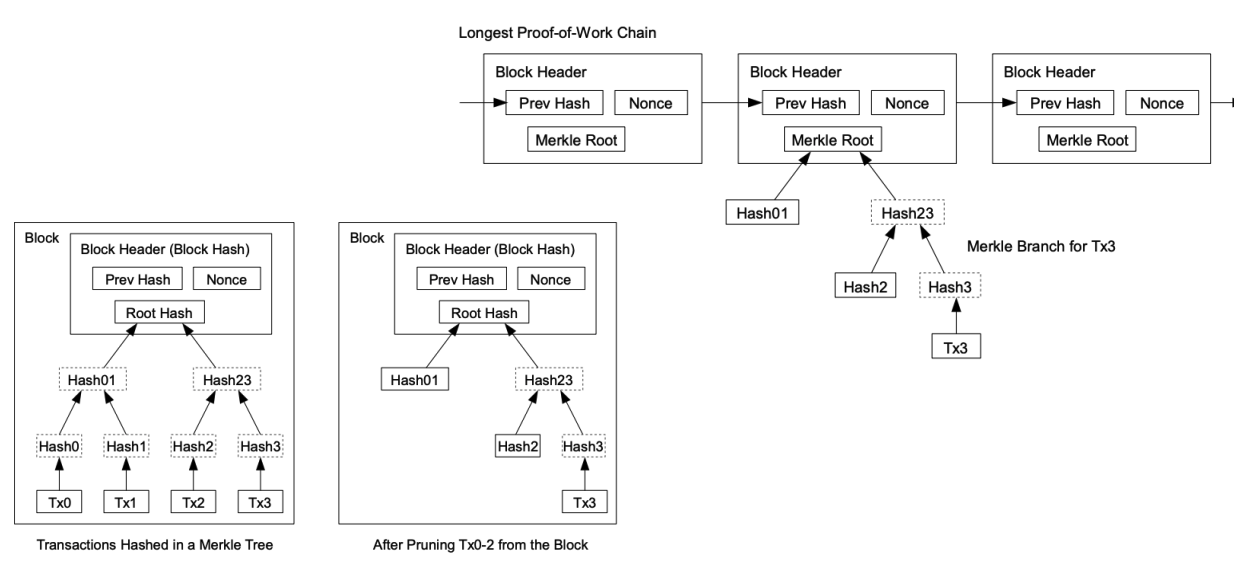
- Merkle tree: a binary tree of hashes, where each leaf node is a hash of a data block, and each non-leaf node is a hash of its children
- Payer can declare the block number where the transaction is included, and the Merkle Tree Path with that certain transaction is sent from the miner to the buyer
- Receiver can verify the transaction by hashing the transaction and the Merkle Tree Path, and compare it with the root hash
Value Splitting
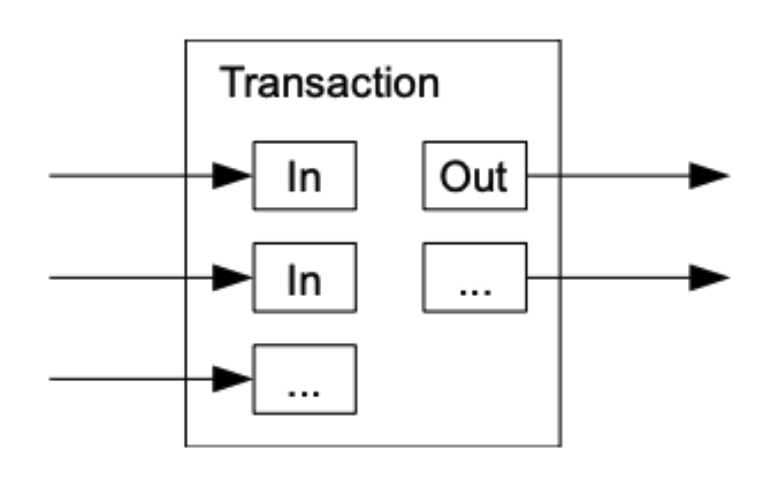
- UTXO: Unspent Transaction Output
- Each transaction has a set of inputs and outputs
- Each output is a UTXO
- Each input is a reference to a UTXO
- Each transaction consumes UTXOs and creates new UTXOs
- UTXOs are indivisible
- UTXOs are used to prevent double spending
- That’s why value splitting is needed
Blockchain versus Raft/ZooKeeper
- No fixed configuration: replica group is open+large
- Nobody trusts anybody
- No leader! 51% evil -> failure
- No RPC: no trusted server to respond! Broadcast.
- Log is public: public ledger. Anyone can read it
- Op confirmation appears in the log, so client and others see it
- Replicas “take turns” as leader and check each other.
- Leaders generate log entries in batches called blocks.
- Leaders sign their blocks and chain hashes: no tampering.
- Clients use keypairs to sign ops (entries, transactions)
Question
- Tolerating malicious participants requires 3f + 1
- Why Bitcoin only needs 51% of computing power to well behave (2f+1) ?
- Proof of Work (PoW): consensus is determined by computational power (hashing power) rather than the number of nodes. This mechanism is designed to make it difficult (expensive) for an attacker to take control of the network, but it doesn’t require a fixed number of nodes to tolerate faults.
- To secure Bitcoin’s blockchain, an attacker would need to control more than 50% of the total mining power in the network to successfully perform a 51% attack (such as double-spending). This is why 51% of computing power is required to “well behave” or keep the network secure.
- Why Bitcoin only needs 51% of computing power to well behave (2f+1) ?
Ethereum
Problem with centralized applications
- have to always trust the application developers/operators
- putting too much trust in a single entity
Decentralized Applications
Minimal trust in application developers/operators, support a wide range of applications
- Approach 1: Build independent network(blockchain)
- Approach 2: Build on top of an existing blockchain
- hard to generalize to other applications
Ethereum
Ethereum is a decentralized platform that runs smart contracts: applications that run exactly as programmed without any possibility of downtime, fraud or third-party interference.
- Security via blockchain: a world computer (every participant executes the exact same code on the exact same state)
- every miner will do the same computation
- Programmability: a programming language for ease of application development
- EVM: Ethereum Virtual Machine Assembly code
- Solidity: a high-level language for smart contracts that can compile to EVM
- Incentive methods for miners: a built-in currency called ether
- user to pay the miner
Ethereum account
- Accounts
- Nonce: a counter used to make sure each transaction can only be processed once
- The account’s current ether balance
- The account’s contract code, if present (contract accounts only)
- The account’s storage (empty by default, contract accounts only)
- Two types of accounts
- External owned accounts: controlled by private keys, like Bitcoin accounts
- controlled by end users
- Contract accounts: controlled by contract code
- controlled by ultimated entity
- External owned accounts: controlled by private keys, like Bitcoin accounts
Message
- An account can sends a message to another account
- The sender can be an external account or a contract account
- The receiver can also be an external account of a contract account
- If the receiver is a contract account, it can return a response
Transaction
- A transaction = a message from an external account + receiver account + amount of ether to send, STARTGAS, GASPRICE
- STARTGAS: the maximum number of computational steps the transaction execution is allowed to take
- Transaction can trigger the execution of code on the contract accounts, STARTGAS is used to limit the execution steps
- GASPRICE: the fee the sender pays per computational step
- STARTGAS: the maximum number of computational steps the transaction execution is allowed to take
- Each transaction has to specify STARTGAS, GASPRICE
- STARTGAS is the limit of steps
- GASPRICE is per-step payment to the miner
- If the transaction runs out of gas, all state changes revert, except for the payment(to the miner)
- If the transaction finishes before gas running out, remaining gas is refunded
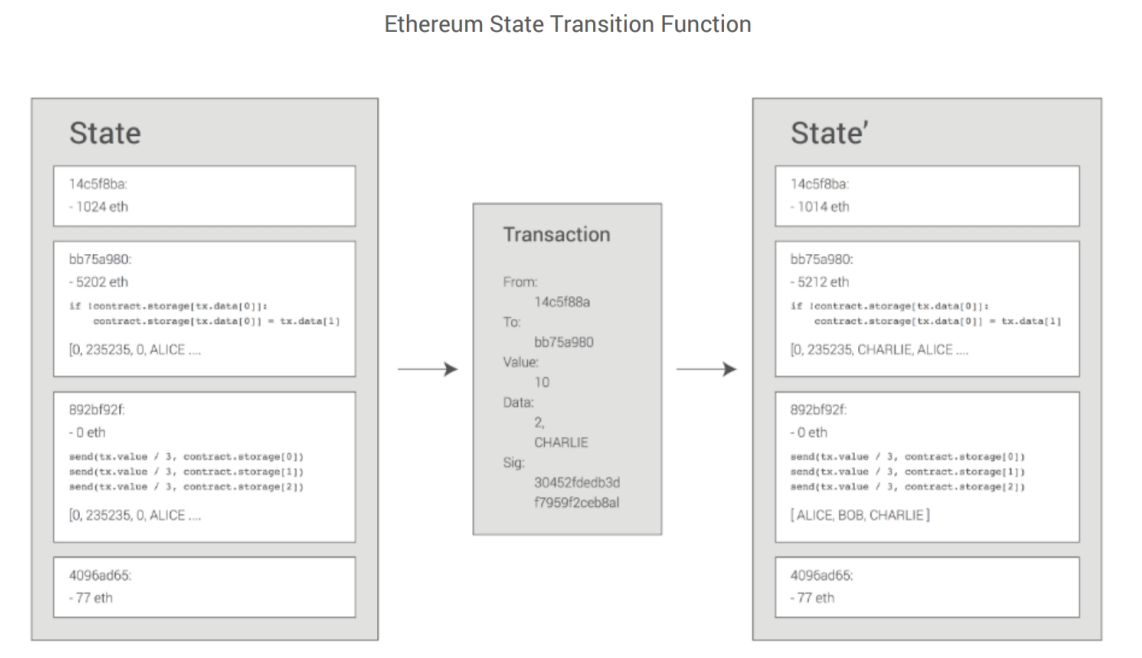 In the example the
In the example the 14c5f88a should be 14c5f8ba
- trsaction from
14c5f8batobb75a980with 10 ether - the code on the receiver account will be executed
Code Execution
- EVM
- a stack-based architecture
- Each operation is a single byte
- Resource for a single program
- Stack: FILO of 32-byte values
- Memory: an infinite expandable byte array
- Storage (persistent across computation): a key-value store of 32-byte keys and 32-byte value
Execution Model
- While the Ethereum virtual machine is running, its full computational state can be defined by the tuple (block_state, transaction, message, code, memory, stack, pc, gas), where block_state is the global state containing all accounts and includes balances and storage.
- Every round of execution, the current instruction is found by taking the pc-th byte of code, and each instruction has its own definition in terms of how it affects the tuple.
- Each Miner can be considered as a single thread of execution, and can reach a consensus on the state of the system.
mining
- Each block contains a set of transactions and the most recent state
- Patricia tree to store the state
- This means we do not need the full history to reconstruct the current state
Other Discussions
- Mining Pool:
- A group of miners who share their processing power over a network and split the reward equally, according to the amount of work they contributed to the probability of finding a block
- Pool operator will distribute the reward to the miners
- Reduce duplication of work, divide the job
- 51% attack: if a pool has more than 51% of the network’s hashing power, it can control the network
- Stale block:
- Should the miner still be rewarded?
- Yes, the miner has done the work, but the block is not included in the main chain
- Can a malicious user let EVM enter an infinite loop?
- run out of gas, the transaction will be reverted, but the miner will still be rewarded
- That means it will be expensive to block the network
- Is Turing completeness needed for ethereum?
- Turing completeness is needed for the flexibility of the system
- But it also brings the risk of infinite loops
- Ethereum is Turing complete, but it has a gas limit to prevent infinite loops
Google File System
Design assumptions
- Component failures are the norm
- Files are huge
- Most files are mutated by appending new data rather than overwriting existing data
- Co-designing applications and file system API
- relaxed consistency model
GFS Architecture
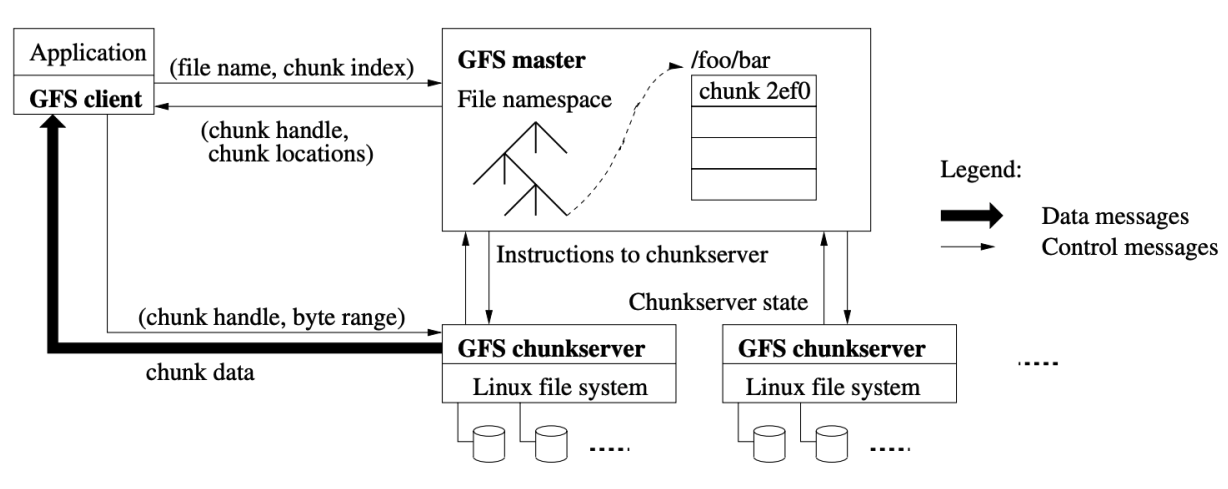
- A single coordinator and a set of chunkservers
- Files are divided into fixed-size (64MB) chunks
- Each chunk has an immutable and globally unique 64-bit chunk handle assigned by the coordinator
- chunk handle is used to refer to the chunk in all communication(identifier)
- Each chunk is stored at 3 different chunkservers
- Each chunk has an immutable and globally unique 64-bit chunk handle assigned by the coordinator
- Coordinator maintains all file system metadata
- Namespace, access control information, mapping from files to chunks, locations of chunks
Coordinateor data
- File Name -> array of chunk handles
- stored in Non-volatile storage
- Chunk handle -> list of chunkservers, version #, primary, lease expiration
- primary: which chunkserver is the primary one, responsible for chunk write
- lease expiration: coordinate assign the lease to the primary chunkserver
- version #: the version number is
- Log + Checkpoints
- Non-volatile storage
File system API
- Common API
- Create, Delete, Open, Close, Read, Write
- GFS-specific API
- Snapshot
- Record append
- GFS will return the offset of the record, facilitate the concurrent appending of records
Read workflow
- Client sends
<Name, offset>to Coordinator - Coordinator sends
<handle, a list of chunkservers, version#>to the client, after that client caches this information- Here the version number stands for the highest version number the coordinator aware of
- Client will cache the returned information for reuse
- Client picks one chunkserver and sends
<handle, offset>- Pick closest server to minimize network overheads
- Check version#: check the version number of chunk server is the same as the version number of the coordinator, if lower than the coordinator, the client will read elsewhere
- Chunkserver reads data from disk to sends content to client
Write/Append workflow
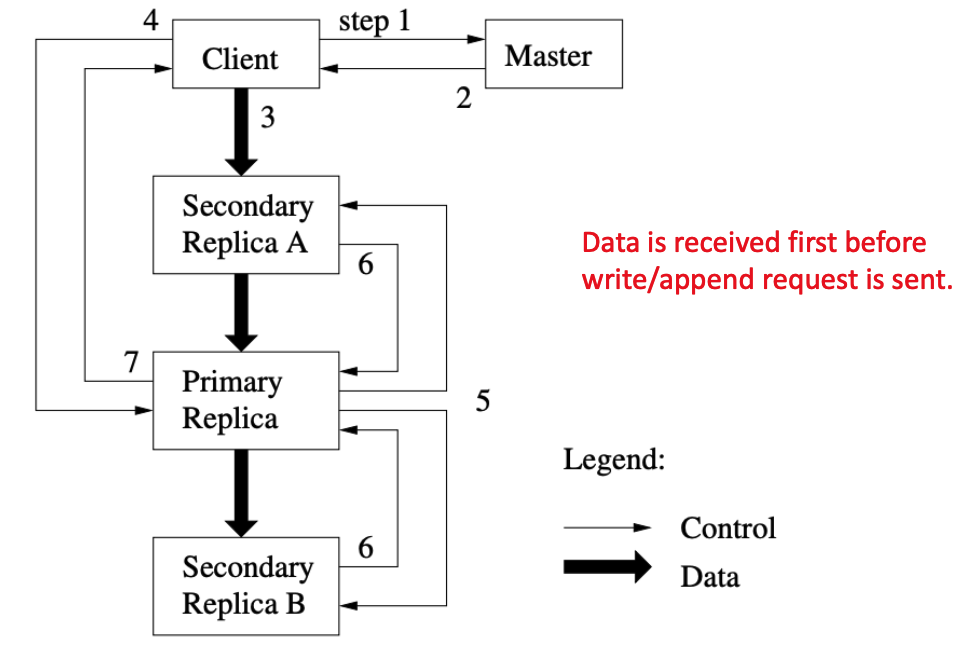
- Use primary back replication to create a 3-copy replicated system
- This means clients needs to know which chunkserver is the primary
- Primary will order write requests from multiple clients
- Coordinator needs to pick a chunkserver as the primary
- Exactly one primary per version number
- pick the one matches the current version number about the chunk
- lease: primary will hold the lease for a certain period of time
- When do primary respond to the client?
- After the data is written to all the chunkservers
- In GFS data and control are decoupled
- Data is temporarily buffered in any nodes and will be formally recorded in the chunkserver after the primary send the write request to the replicas
Single Coordinator
- Can use global knowledge to do chunk placement and replication decisions
- like chunk servers management: heartbeat
- Need to minimize its involvement in reads/writes so that the coordinator will not become a performance bottleneck
- only metadata operations are handled by the coordinator, like create or delete
- Hold metadata in memory: If a client’s request is read-only for metadata, then latency is low
- The coordinator writes an operation log on its disk, and the log is replicated to remote machines
- Periodically scan through its entire state for chunk garbage collection, extra replication when chunkservers failed, chunk migration to load balancing of disk spaces and chunk accesses
- the entire system’s intelligence is concentrated in the coordinator, and other nodes are only responsible for data storage and retrieval
- Polls chunkservers for chunk locations
Lease
- Coordinator selects primary by giving the primary a 60 second lease. When a chunkerserver has the lease, it knows that it is the primary for the chunk.
- The reason for lease:
- why not use rpc calls to select primary(assign, revoke)?
- probable network partition/ latency
- no boter for checking the primary, all need to do is to wait for the lease to expire, no need for reliable failure detector
- why not use rpc calls to select primary(assign, revoke)?
Record append

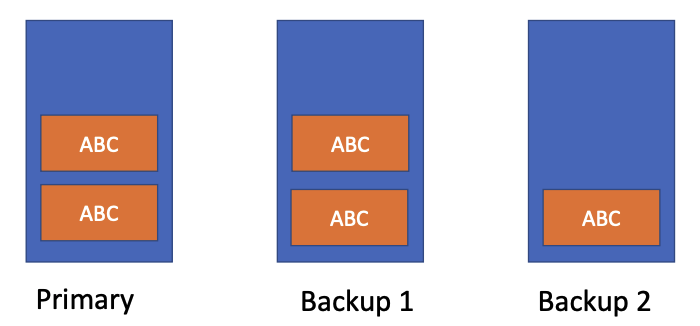
Here ths blue rectangle indicates the chunk. backup2 is not able to receive the data, if the primary retries to append data on backup2, the data will be appended somewhere else
- Read/Write are idempotent, but append is not
- No need to specify offset
- Offset is part of the return value of append
- append request from different clients will be ordered by coordinator
- GFS will append the record “at least once” atomically
- duplicated append will cause the data not consistent any more
- GFS think have an inconsistent chunk copy is fine
Consistency Model
- A file region is consistent if all clients will always see the same data, regardless of which replicas they read from.
- A file region is defined after a file data mutation (like a write or append) if it is consistent and clients will see what the mutation writes in its entirely.
- Client 1 write AAA, GFS returns successfully
- Client 2 write BBB, GFS returns successfully
- Client 3 read, won’t be case like ABA
- If all clients see case ABA, then it’s consistent but undefined
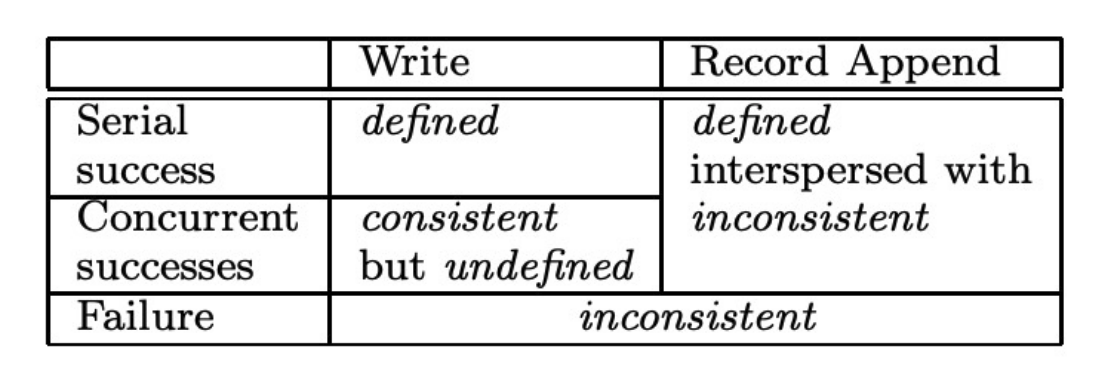
- the consistent and undefined for concurrent successes of writes indicates that there might be leader shift in the chunk boundaries, which might cause the operation order to be inconsistent among chunks
- For record append, append never cross the chunk boundary, so the record append is defined. but some chunks might contain multiple copies of same record
Big Table
Design Assumptions
- Lots of semi-structured data
- URLs: Contents, crawl metadata(when, response code), links, anchors
- Per-user Data: User preferences settings, recent queries, search results
- Geographical locations: Physical entities – shops, restaurants, roads
- Large Scale
- Billions of URLs, many versions/page - 20KB/page
- Hundreds of millions of users, thousands of queries/sec – Latency requirement
- 100+TB of satellite image data
Why not use commercial DB
- Scale is too large for most commercial databases
- Even if it weren’t, cost would be very high
- Low-level storage optimizations help performance significantly
- Much harder to do when running on top of a database layer
Goals
- asynchronous processes to be continuously updating different pieces of data
- access to most current data at any time
- Need to support:
- Very high read/write rates
- Efficient scans over all or interesting subsets of data
- Efficient joins of large one-to-one and one-to-many datasets
- Often want to examine data changes over time
- Contents of a web page over multiple crawls
Big Table
-
A distributed storage system for managing structured data that is designed to scale to a very large size
- Distributed multi-level map
- Fault-tolerant, persistent
- Self-managing
- Servers can be added/removed dynamically
- Servers adjust to load imbalance
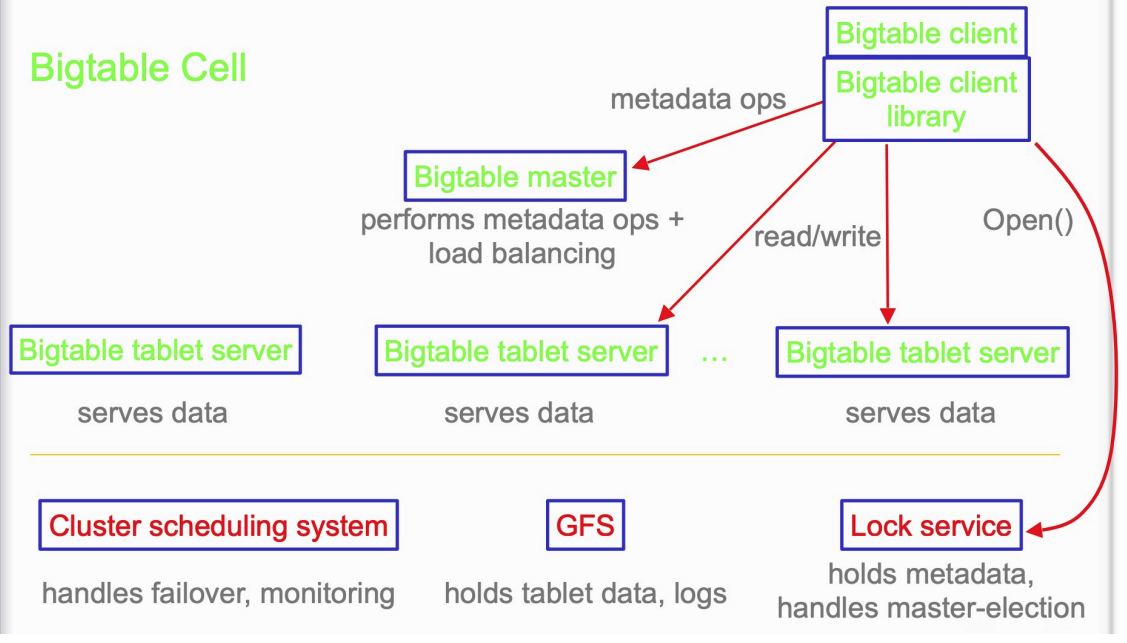
Components
- Google file system (GFS): raw storage, stores persistent state
- Scheduler: schedule jobs onto machines
- Lock service : distributed lock manager, coordinator election, location bootstrapping
- Mapreduce: large-scale data processing, used to read/write BigTable data
Data model
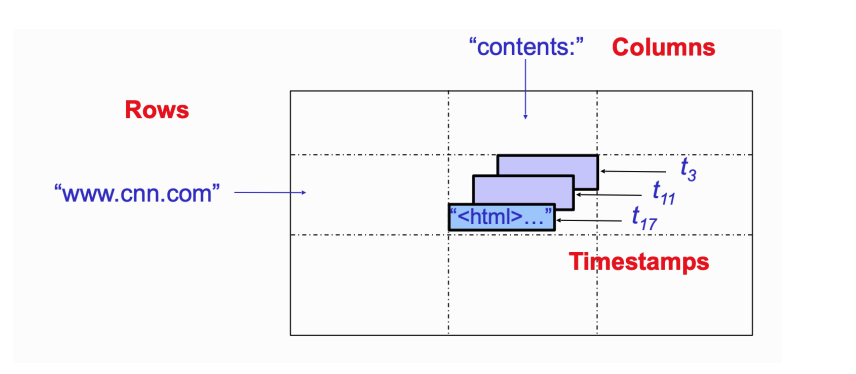
- Distributed multi-dimensional sparse map
(row, column, timestamp)-> cell contents
Rows
- Name is an arbitrary string
- Access to data in a row is atomic
- Row creation is implicit upon storing data
- Rows ordered lexicographically
- Rows close together lexicographically usually on one or a small number of machines
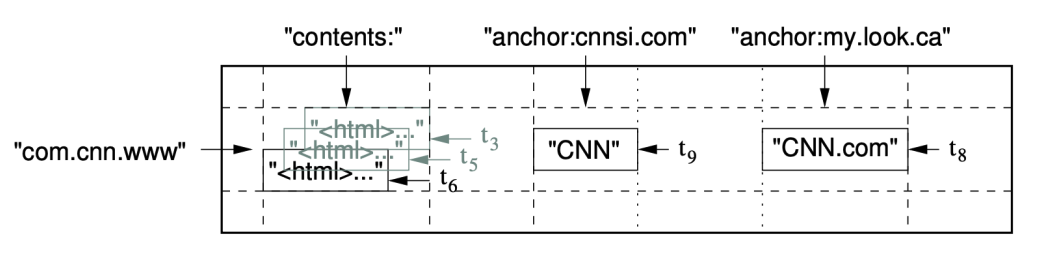
- usually URL is stored in the reversed ordering
- for locality reasons
- because of the url’s structure, the reversed url will have the same prefix for the same domain
Tablets
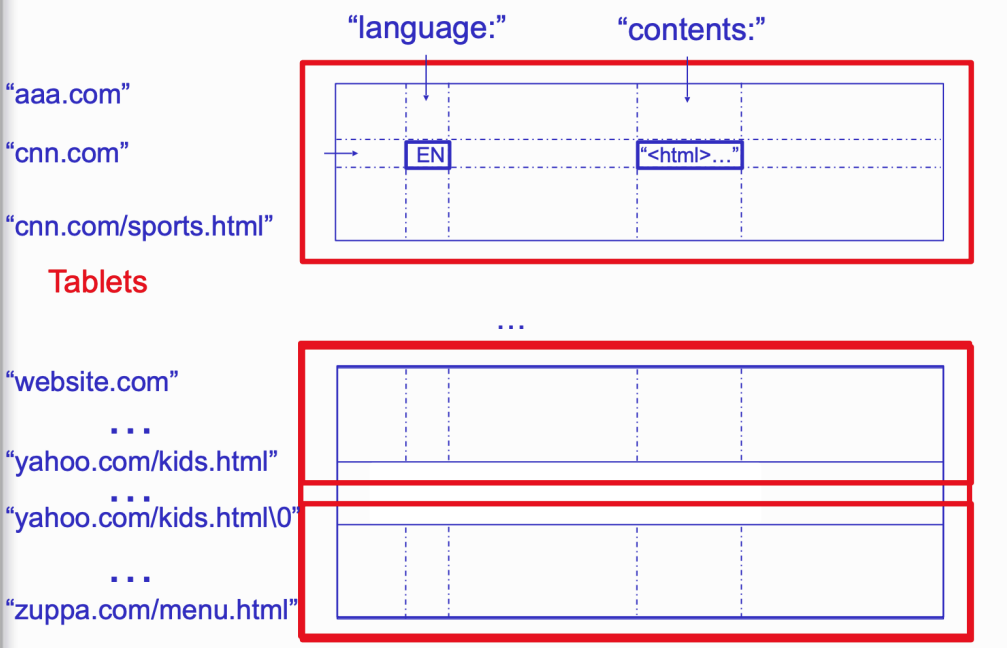
- Large table broken into tablets at row boundaries
- Tablet holds contiguous range of rows
- Clients can often choose row keys to achieve locality
- Aim for ~100MB to 200MB of data per tablet
- Serving machine responsible for ~100 tablets
- Fast recovery
- 100 machines each pick up 1 tablet from failed machine
- Fine-grained load balancing
- Migrate tablets away from overloaded machine
- Coordinator makes load-balancing decisions
- Fast recovery
Structure